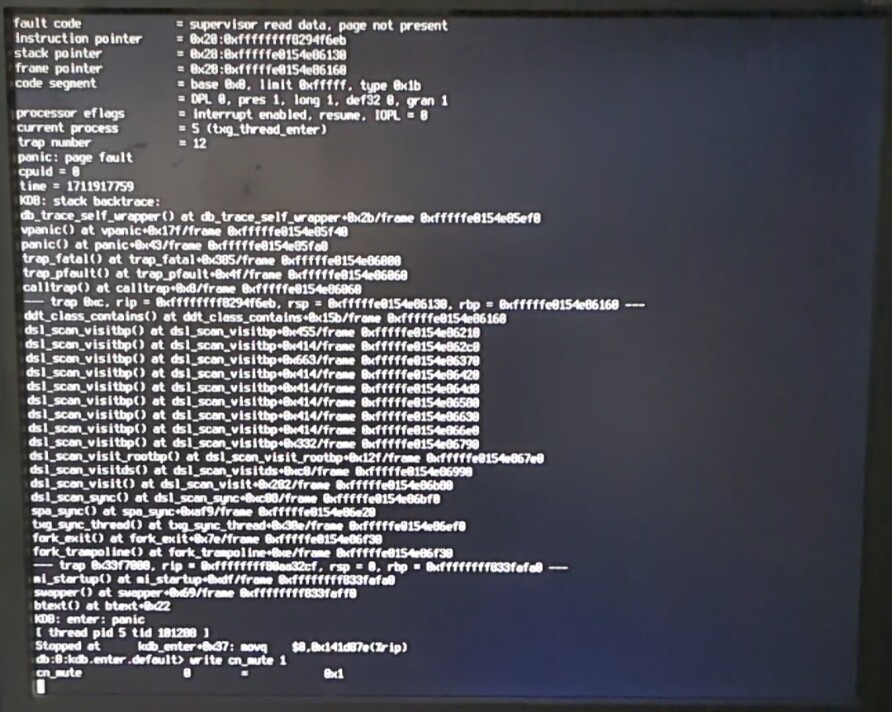
A few days ago I got an alert that the system had an unexpected restart but nothing was wrong so I just kind of ignored it. The system is behind a UPS so the random restart wasn’t due to power loss. The next day I realized it was stuck in a boot loop with a message before restarting
The system would no longer boot so I tried installing TrueNAS Core on a new partition as an upgrade, but the same issue happened. I then tried doing a clean install and while I could get to the GUI as soon as I tried to import the pools the system would restart and go back to the same error. I tried following a few different solutions found on the forum like importing as readonly but it did the same thing. After reinstalling TrueNAS when I try to import the pool it says poolname not found, and when I try to list the pools it only shows boot-pool, unless its a clean install I can see the pool through the GUI. So maybe I’m just using the wrongs commands since I’m not very familiar with this.
I’ve had the system running for over a year without any problems so I’m not sure what happened since I didn’t do any updates or anything like that when it started happening. Below are my system specs. Its been a while since set it up but I’m pretty sure its setup as RAIDZ2, but could be RAIDZ1.
Does anyone have any ideas how to fix this?
What I tried :
Ran S.M.A.R.T. test on all drives and it passed without any errors
Ran MemTest and it passed without errors
Upgrading TrueNAS Core from previous installation
Installing TrueNAS Core from scratch
Importing pools as readonly
System Specs Motherboard : MSI PRO B660M-A Micro-ATX RAM : 2x 16GB DDR4 3600 CORSAIR Vengeance CPU : Intel Core i5-12600K Storage : 8x Seagate 10TB IronWolf SATA III, 1x 500GB SSD (for running TrueNAS) Expansion cards : 1x 10GB PCI-E Network Card (onboard had issues), 1x M.2 PCIe 6 x SATA Adapter Card (motherboard doesn’t have enough SATA ports)
I only have 2 sticks of memory so I tried using just one at a time, and had the same issue.
I was messing around with it and noticed it booted if I had 3 or more drives unplugged, which I’m going to guess is because it couldn’t import the pool. After plugging all the drives back in it booted up but it says “ONLINE (Unhealthy)”. All the drives are there and seem to be working, could it be “unhealthy” because of the adapter?
As I see, ZFS runs pool scrub, and I suppose in process hits some metadata block with valid checksum, but with block pointer containing some incorrect values, that causes panic in dedup code. It still may be a result of a pool corruption. You should be able to import the pool read-only and evacuate the data.
There is talk in this Reddit discussion about the controller overheating if there is no heatsink. Other versions on Amazon seem to have a heatsink. Maybe add one if it is g there already.
As I see, ZFS runs pool scrub, and I suppose in process hits some metadata block with valid checksum, but with block pointer containing some incorrect values, that causes panic in dedup code. It still may be a result of a pool corruption. You should be able to import the pool read-only and evacuate the data.
When I ran zpool status two of the drives had a 1 under the “UM” column. I cleared the errors and they haven’t come back since the system has been running.
There is talk in this Reddit discussion about the controller overheating if there is no heatsink. Other versions on Amazon seem to have a heatsink. Maybe add one if it is g there already.
That’s interesting and I haven’t thought about it overheating. The system is in my basement which stays pretty cool and has constant airflow, but I do have a fairly large heatsink on the CPU which covers the M.2 slot. I might try to move it to the other M.2 slot to see if that makes it any better. The drives themselves sit around 30℃.