To avoid this, do not set the share to host home directories.
Share flag “use as home share” is unset.
User flag “create home directory” is also unset.
I’ve no idea why this dataset in dataset is created.
Seems to me i’m not the only one:
https://www.reddit.com/r/freenas/comments/jzdb4v/truenas_creates_a_folder_with_the_username_in/
The Reddit link had the solution.
“Remove the “Path Suffix” in the share’s “Advanced Options”. I expect it is currently set to “%U” which is causing the username folders. Just remove that and save.”
“Additional Info for anyone googling this: You need to disable the Preset under Purpose to do that. The “Private Share” Preset adds this suffix.”
Checked my setting, and preset “Private SMB Datasets and Shares” was set. This added the %U flag in path suffix.
I changed the preset to no preset and adjusted “other options” manually and deleted the test sub dataset under the share dataset.
Test with Veeam and the same testuser was successfull.
No test dataset visible so far.
Now i have to adjust all remaining SMB share configs and add the final user configuration.
2 Likes
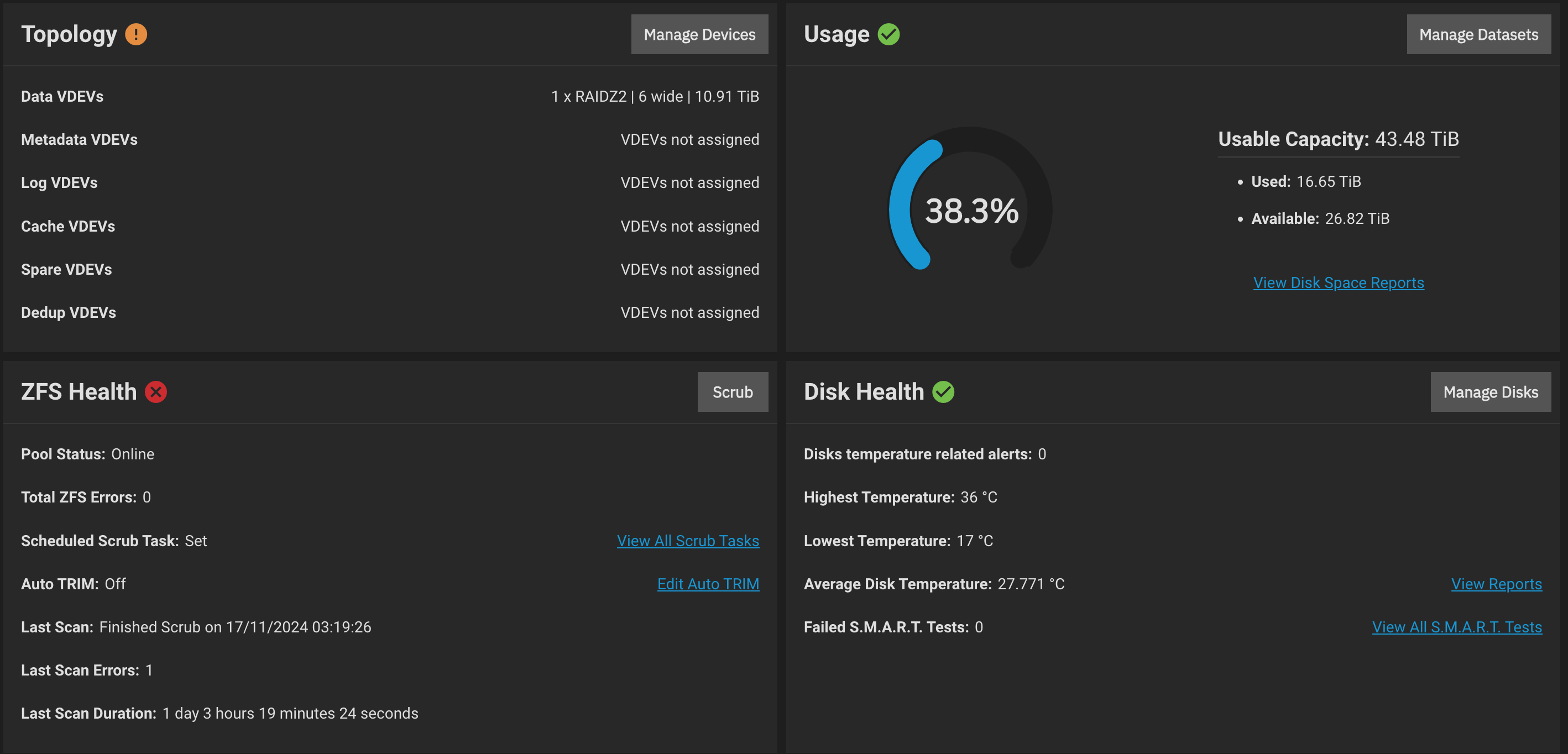
Hmm, scrub finished with checksum errors on some drives.
After a restart I checked all 6 drives with smartctl -a /dev/sd* and watched out for line that starts with “199 UDMA_CRC_Error_Count”.
The number at the end of that line shows how many times there has been a communication error between the disk and the host.
It’s been said a new disk and if the number is higher than 0, or if you notice the number increase over time, then you probably have a bad SATA cable.
5 drives show 0, but 1 drive 341.
So if that’s correct, i could be one faulty SATA cable.
That wonders me because if i recall correctly, while scrubbing a few drives showed some checksum errors, not only one.
zpool status -v for that pool shows:
pool: Backup
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: scrub repaired 64K in 1 days 03:19:24 with 1 errors on Sun Nov 17 03:19:26 2024
config:
NAME STATE READ WRITE CKSUM
Backup ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
bc246e49-0fe9-4fd1-9d32-cd4a08539959 ONLINE 0 0 0
1cb0e718-7283-40cb-a579-d5fbd138dc61 ONLINE 0 0 0
8186c3e0-0d82-4cae-8c77-5cb289000fab ONLINE 0 0 0
67adade2-79a8-4f5d-91d0-2aa97df2a209 ONLINE 0 0 0
89817079-a2de-4f5f-a50b-86bcbc5f6f8d ONLINE 0 0 0
7ed0e6c6-ea70-4740-b51b-3fb85b0ecf7b ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
Backup/Backup@auto-02-10-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-16-11-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-25-08-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-23-10-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-16-10-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-04-09-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-30-10-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-28-08-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-05-10-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-09-10-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
/mnt/Backup/Backup/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-21-08-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-28-04-2024_22-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Backup/Backup@auto-13-11-2024_21-00:/Server Infrastructure Software/NetApp/ONTAP/8.1.ZIP
Am I right in assuming that if I identify the one drive with the serial number, replace the SATA cable with a new one, do a zpool clear and then, even if it takes another day, manage to scrub again without errors, everything is OK?
Possibly…
But you may have one genuinely damaged file, which should be deleted alongside any snapshot referencing it.
1 Like
I replaced the SATA cable on the identified drive.
To be on the safe side, I unplugged both ends of the SATA cable on the controller and all drives in all pools and blew out the connector. But I only replaced one.
Then I deleted the file on the dataset and all the listed snapshots that pointed to the error.
In the meantime I copied some more data onto the dataset, was just about to do a zpool clear and then start a scrub, when the zpool health status in the storage dashboard went from red to green again.
Of course, “Last Scan Errors” is still listed as 1 at the bottom, but a zpool status -v recently shows “errors: No known data errors” for the pool, both of which are positive.
Nevertheless, I’m going to do a zpool clear and start a scrub.
1 Like
Man, i must have been lucky. The scrub ran through without any errors. I normally only run a scrub once a month because it takes so long with the z2 pool with the mechanical HDDs.
For sdh, the UDMA_CRC_Error_Count stayed at 341, but after the actions mentioned above, no more were added. I think the smart value stays the same and just calculates upwards.
zpool status -v also looks clean:
pool: Backup
state: ONLINE
scan: scrub repaired 0B in 1 days 03:13:47 with 0 errors on Tue Nov 19 04:58:54 2024
config:
NAME STATE READ WRITE CKSUM
Backup ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
bc246e49-0fe9-4fd1-9d32-cd4a08539959 ONLINE 0 0 0
1cb0e718-7283-40cb-a579-d5fbd138dc61 ONLINE 0 0 0
8186c3e0-0d82-4cae-8c77-5cb289000fab ONLINE 0 0 0
67adade2-79a8-4f5d-91d0-2aa97df2a209 ONLINE 0 0 0
89817079-a2de-4f5f-a50b-86bcbc5f6f8d ONLINE 0 0 0
7ed0e6c6-ea70-4740-b51b-3fb85b0ecf7b ONLINE 0 0 0
errors: No known data errors
pool: VM_Storage
state: ONLINE
scan: scrub repaired 0B in 00:07:03 with 0 errors on Mon Nov 18 01:40:35 2024
config:
NAME STATE READ WRITE CKSUM
VM_Storage ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
dff995c9-12e8-4718-8742-178069eaef38 ONLINE 0 0 0
06c79ccd-acf0-4bb1-aef3-61d518e1652f ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
877fac40-bdfa-4220-b2ff-1f078be7c717 ONLINE 0 0 0
9a9a9dea-8edb-49a4-b4ea-200a4f930de3 ONLINE 0 0 0
logs
mirror-2 ONLINE 0 0 0
fbe06849-bf33-481f-bf7a-137e80794225 ONLINE 0 0 0
38f2107f-ec9b-40dd-a297-b1e3d02b5ece ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 02:09:12 with 0 errors on Mon Nov 18 03:51:49 2024
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdl3 ONLINE 0 0 0
sdm3 ONLINE 0 0 0
errors: No known data errors
i have played a lot with ZFS on Windows recently. It is still beta but already quite usable based on OpenZFS 2.2.6. Remaining problems are mainly around the driver and Windows integration what can mean BSOD due mount problems or compatibility with other services. ZFS itself is quite stable as it is a regular OpenZFS.
Once OpenZFS is installed on Windows fastest method to replicate datasets from TN is via netcat, settings ex via nc64
Windows receive:
\path\nc64.exe -v -l -d -w 10 -p 53087 | zfs receive -v tank/data
Linux send
zfs snap tank/data@2
zfs send tank/data@2 | pv | nc 192.168.2.65 53087
For a filebased sync I would prefer robocopy from Windows via SMB over rsync as this can preserve ntfs alike ACL.
1 Like