root@truenas:/# sudo zpool import -d /dev/disk/by-id/
pool: data
id: 15103091714514370022
state: FAULTED
status: The pool metadata is corrupted.
action: The pool cannot be imported due to damaged devices or data.
The pool may be active on another system, but can be imported using
the '-f' flag.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-72
config:
data FAULTED corrupted data
wwn-0x50014ee26181b6f3-part2 ONLINE
wwn-0x5000cca371c31a04-part2 ONLINE
root@truenas:/# sudo zpool import -d /dev/disk/by-partuuid/
pool: data
id: 15103091714514370022
state: FAULTED
status: The pool metadata is corrupted.
action: The pool cannot be imported due to damaged devices or data.
The pool may be active on another system, but can be imported using
the '-f' flag.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-72
config:
data FAULTED corrupted data
b25df2bc-ce76-11ee-9fb8-d45d64208664 ONLINE
b24ce596-ce76-11ee-9fb8-d45d64208664 ONLINE
Well - although the ZDB output is similar to the reddit post, the import results are different.
In the example, the original import showed 3 devices, the zdb showed 5 with 2 missing, and the revised import by-id showed all 5 devices.
But we still get only 2 devices and not 3.
I am running out of ideas (or have already done so).
1 Like
In case it helps, I think the problem comes from a power outage and that caused the computer to suddenly shut down, causing the pool metadata to become corrupted.
But I don’t understand how it is that because of a corrupted pool, I lose access to the data on the disks.
thanks anyway.
This post (which even though it is old and relates to Core should still be useful because ZFS is the same) suggests how to make it work - but I would wait and get some feedback from an expert as to whether this will work or not before you try it:
-
Use the UI to add
/dev/sdaas a stripe. (I would then do thesudo zdb -eC datato see what it says.) -
Reboot.
But as I say, I think you should wait for e.g. @HoneyBadger to review this idea before you try it (and it is the weekend and as an iX employee it will probably be Monday before he reads this stuff).
Corrupt metadata can screw up any configuration however redundant. BUT ZFS is supposed to be ultra safe on writing data to ensure that it never gets corrupted.
But in simple terms a ZFS pool completely relies on every data vDev and special (metadata) vDev being there or the pool is toast.
In a redundant configuration (i.e. every vDev is mirrored or RAIDZ), in general terms if a single thing does go wrong (like a disk gets dropped) then because of the redundancy the vDev stays online, and so the pool stays online, and recovering the vDev from degraded to fully working is easier. But if you lose a vDev completely, your pool is then in error state and offline.
When you have no redundancy, any single issue makes a vDev unavailable and so makes the entire pool unavailable.
With a non-redundant stripe layout, there’s zero tolerance to failures.
Wouldn’t that wipe the drive before adding it? ![]()
Rebooting seems safer, or at least harmless. But I have no clue what could cause ZFS not to see sda as a member drive.
1 Like
thanks to @Protopia and @etorix i gonna wait until @HoneyBadger say something, i wish i can recover all data.
I would like to pay a company to recover the data, but I am 19 years old and I am studying, I do not have money to pay for it lol
anyone, Thanks ![]()
I am
I am only reporting what an ancient community post said - and I thought that it might wipe the drive too, hence suggesting a wait for HB to chip in.
A reboot wouldn’t hurt - and aside from possibly reordering the drives it will either work (in which case hurrah!!!) or it won’t (in which case nothing lost).
But unless anyone else can find relevant potential fixes by looking wider on t’internet, then I think we have come as far as we can (which is actually quite a long way).
Hmm. Looks like you do have two valid labels to go with the two bad ones on your 1TB. But you definitely have a stripe pool.
Let’s try manually specifying the UUIDs directly.
sudo zpool import 15103091714514370022 -d /dev/disk/by-partuuid/b2639d11-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b25df2bc-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b24ce596-ce76-11ee-9fb8-d45d64208664 -R /mnt -N -o cachefile=/data/zfs/zpool.cache
If this doesn’t work, try the same command with -Fn after the -R /mnt on the end.
If this does work and returns no errors, check sudo zpool status -v to see if the pool’s there. If it does, then export it again with sudo zpool export data and then try importing from the webUI to see if it will pick it up with the repaired labels.
It does also look like that “Portable SSD” is exactly the right size to clone your 1TB MQ01ABD100 drive to as well so if the above throws the same error, I’d look at making a clone of your existing 1TB Toshiba disk to that external SSD before we attempt a label repair.
1 Like
Hello,i test both options and one return an error and the other one, dont return nothing
alber@truenas:/$ sudo zpool import 15103091714514370022 -d /dev/disk/by-partuuid/b2639d11-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b25df2bc-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b24ce596-ce76-11ee-9fb8-d45d64208664 -R /mnt -N -o cachefile=/data/zfs/zpool.cache
[sudo] password for alber:
cannot import 'data': I/O error
Destroy and re-create the pool from
a backup source.
alber@truenas:/$ sudo zpool import 15103091714514370022 -d /dev/disk/by-partuuid/b2639d11-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b25df2bc-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b24ce596-ce76-11ee-9fb8-d45d64208664 -R /mnt -Fn -N -o cachefile=/data/zfs/zpool.cache
alber@truenas:/$
The other 1TB SSD it and extern disk all add I thought maybe it would work to add another disk.
sudo zpool status -v return this
alber@truenas:/$ sudo zpool status -v
pool: boot-pool
state: ONLINE
status: One or more features are enabled on the pool despite not being
requested by the 'compatibility' property.
action: Consider setting 'compatibility' to an appropriate value, or
adding needed features to the relevant file in
/etc/zfs/compatibility.d or /usr/share/zfs/compatibility.d.
scan: scrub repaired 0B in 00:00:26 with 0 errors on Fri Nov 8 03:45:27 2024
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
ata-EMTEC_X250_256GB_A2205CW03290-part2 ONLINE 0 0 0
errors: No known data errors
So, should I try to export the pool again with sudo zpool export data?
Sorry for not replying sooner, I didn’t get home until now
You cannot export a pool which is hasn’t imported successfully. The objective is to get the pool to import somehow and once it is imported we can make sure that it will mount all the datasets at the expected mount points, that the pool will remain imported across reboots and that the UI is in step with the underlying ZFS status.
But we are well past my own limited expertise, so we probably now need to wait for @HoneyBadger to suggest a next step.
So far my basic understanding of this issue has been that the pool metadata is corrupted, but the data on the disk is, so it’s still possible to recover it, right? (I think I already asked this)
Talking about reboots, i dont reboot since i start this post, Just in case after running so many commands something doesn’t break when restarting, am I doing the right thing?
It is entirely possible that you could build your own spaceship and take yourself to the moon. All the science is done - you just need to repeat what NASA did. In the same way that it is possible for you recover the data without importing the pool and mounting the datasets.
As I said previously, at this point you can either physically send your disks to and pay a VERY expensive data recovery company to recover your data for you, or you can wait and see if HoneyBadger is able to find a way for you to get your disks to import.
Regarding reboots, it is very unlikely IMO that a reboot will cause any damage to a pool which isn’t imported, but it is potentially possible that it might. Equally it is unlikely that a reboot will cause the pool to start working again, but it might. Again, at this point I suggest you wait for HoneyBadger to respond.
1 Like
I think the best option is to wait for Honey Badger, thanks
Because the latter one with the -Fn returned without an error, that suggests that you may be able to import while rewinding to that previous state.
Re-run the command but use only -F instead of -Fn
If it succeeds, check with zpool status
Doesn’t work ![]()
alber@truenas:/$ sudo zpool import 15103091714514370022 -d /dev/disk/by-partuuid/b2639d11-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b25df2bc-ce76-11ee-9fb8-d45d64208664 -d /dev/disk/by-partuuid/b24ce596-ce76-11ee-9fb8-d45d64208664 -R /mnt -F -N -o cachefile=/data/zfs/zpool.cache
[sudo] password for alber:
cannot import 'data': I/O error
Destroy and re-create the pool from
a backup source.
alber@truenas:/$
Well, we’re now on to the voodoo.
Step 1. Clone your 1TB Toshiba to another disk (that external SSD) so that we have a backup to try again if this doesn’t work. Use Clonezilla or another bit-by-bit copying program. Ensure you are copying FROM the Toshiba TO the SSD.
Step 2. Do sudo zhack label repair -cu /dev/devicenameofthetoshiba
Step 3. Attempt the reimport of the pool.
2 Likes
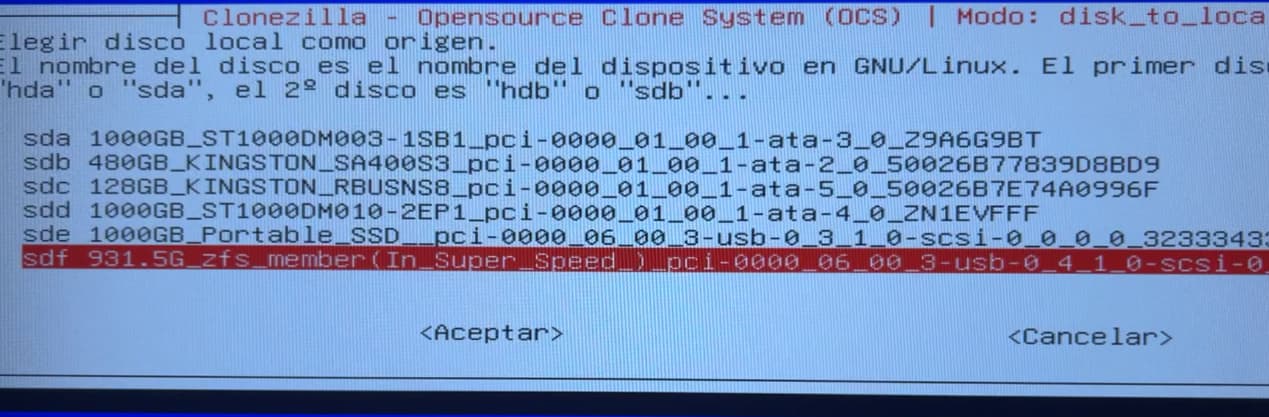
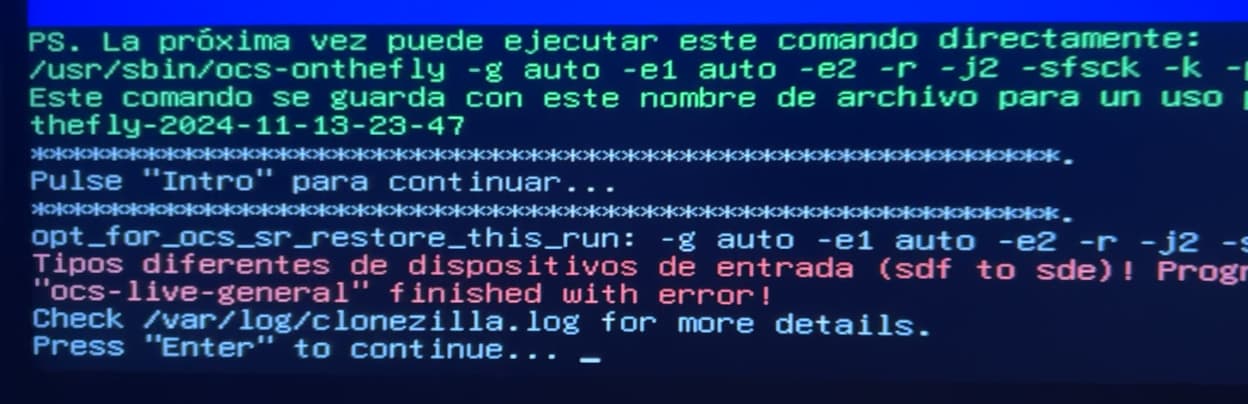
I’ve been trying to clone them all afternoon, but for some reason, in the BIOS bootmenu it detects both hard drives, but when I enter Clonezilla, it only lets me clone the 1TB portable SSD, but not the HDD. I don’t understand why it appears in the BIOS, but not in Clonezilla ![]()
im trying other softwarem but they run on Windows, and they are not an iso image, but it does not work either
[EDIT] I’m trying clonezilla on my main computer and now it detects both disks, I’m cloning, I hope it works
[EDIT 2] I think the cloning didn’t work, or at least it was cloned instantly, I mean, it didn’t even take 10 seconds, im so confuse
You’ll need to ensure you are working in device-to-device mode, and that you select the entire disk for the source and not just a partition.