I did a Raid5 Expansion on a Synology the other day.
It took approaching a month to complete. It was a fairly big array with a lot of data
I did a Raid5 Expansion on a Synology the other day.
It took approaching a month to complete. It was a fairly big array with a lot of data
@prez02 Yeah the “7th bay” is just the caddy with for the 4 additional NVMes
That’s a very valid point, but I wouldn’t rule out my own incompetence to find (or properly search for) the documentation. I’ll ask around ![]()
Update: I have no clue what happened 3h ago but I’m seeing vastly improved speeds, with zero changes on my part.
$ sudo zpool status hdd_array -v
pool: hdd_array
state: ONLINE
expand: expansion of raidz1-0 in progress since Sat Jan 4 00:03:08 2025
3.65T / 10.5T copied at 43.1M/s, 34.69% done, 1 days 22:22:53 to go
config:
NAME STATE READ WRITE CKSUM
hdd_array ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
28b6cbd7-3726-447e-a894-5d618c9ab79f ONLINE 0 0 0
c71373d1-b30a-43b9-8f26-51e249021d5d ONLINE 0 0 0
1879b64d-45b0-42a9-8d48-b0381f87a21f ONLINE 0 0 0
336608bc-9edf-43e8-a630-55f24fbbbced ONLINE 0 0 0
That’s to be expected if you have different file sizes (ie small photos and large video files).
I have only ~100G of music, the rest is mostly movies and series. I don’t know why the first 500G+ would have been slow
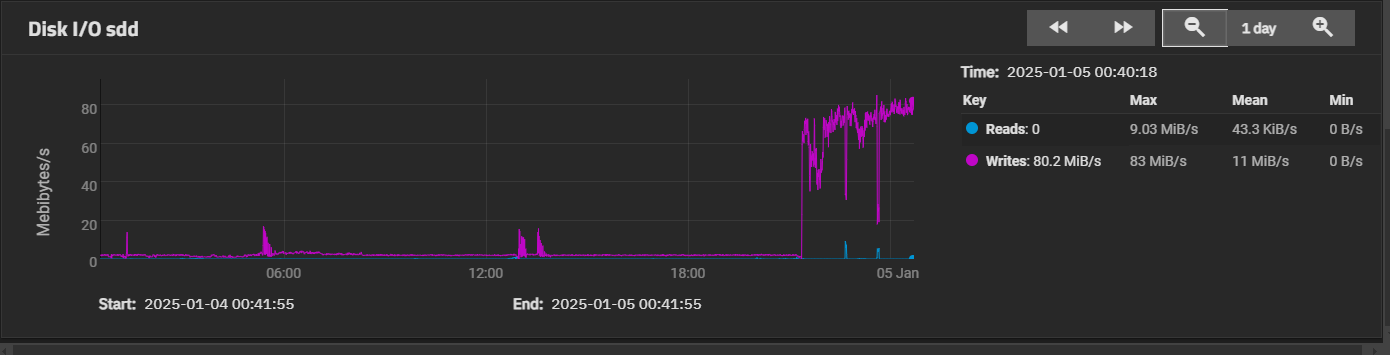
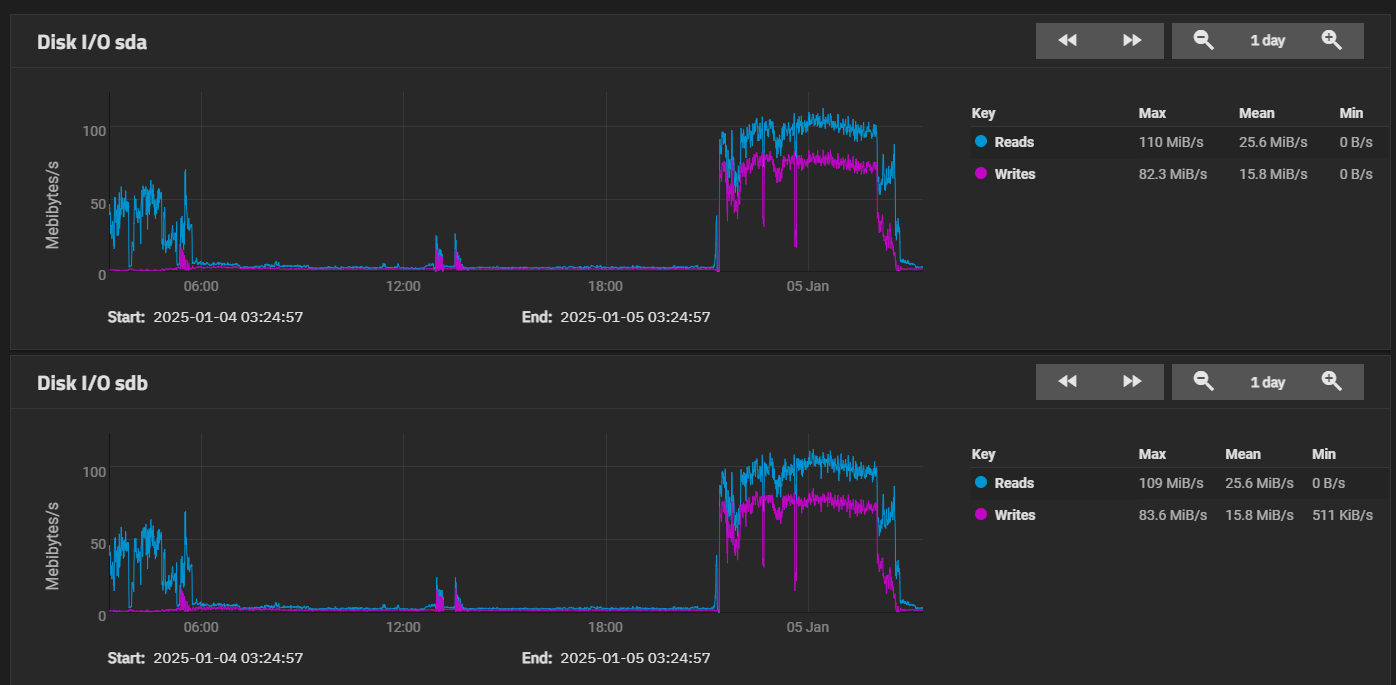
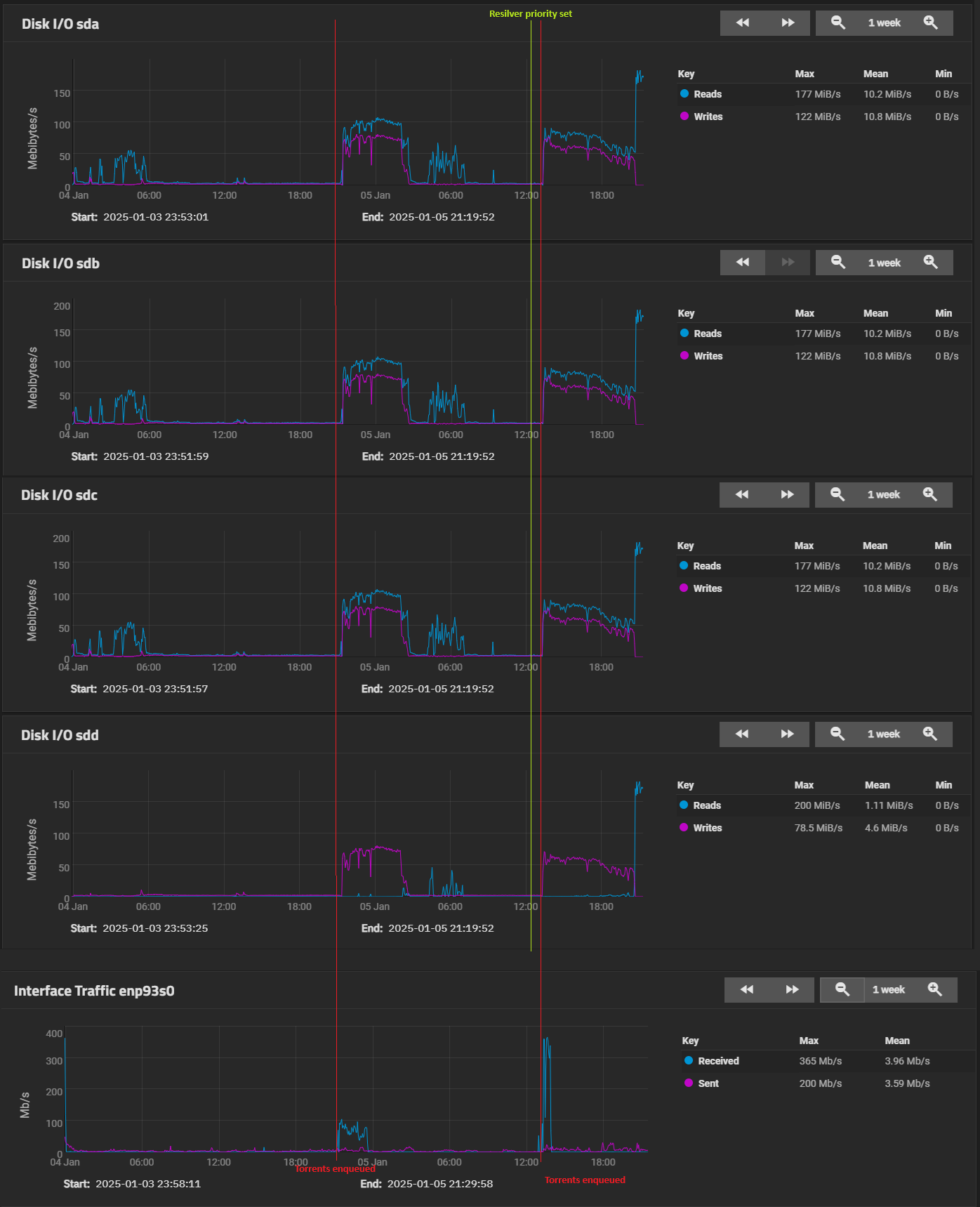
While you still have a chance to look at recent disk history, can you show the read activity on the other disks? Hopefully to align (as close as possible) with the graph from the new disk that you just displayed.
Interesting. I thought that perhaps that RAIDZ expansion triggers a scrub ahead of the actual expansion, and so the numbers you were seeing were inaccurate. Like some sort of rough average estimate. (That might have also explained why you had the sudden boost of speed, if it were the case.)
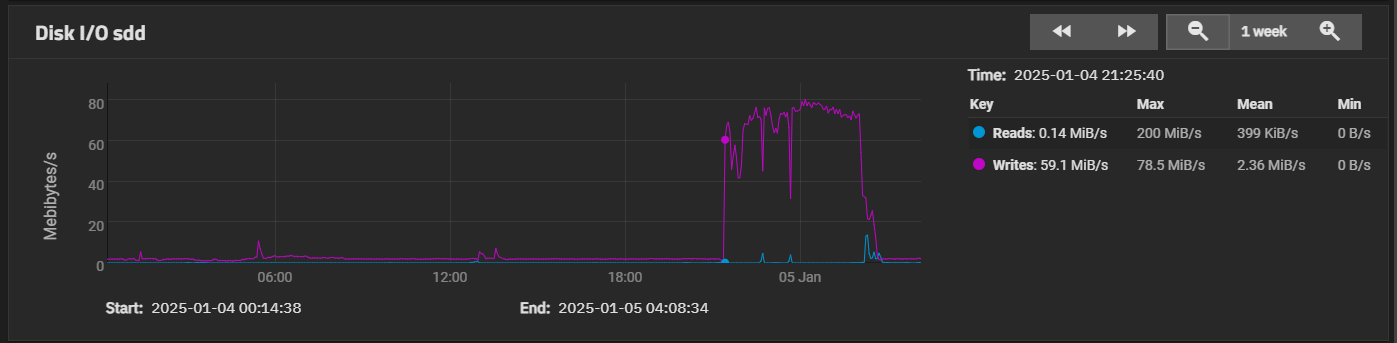
However, there’s no read activity on the other drives to show this.
There could be another explanation for this peculiar window of performance.
Do you have this menu somewhere in SCALE? In Core, it essentially lets you schedule a window of time where resilvers get priority. This might also apply to RAIDZ expansions.
I had a similar gut feeling (that it’s doing some preprocessing on the existing disks) since the pool was initially set up on a different system (with older ZFS to boot). There was also some read activity on the other drives in the initial 6 hours However, now the speeds are down again.
As for the setting, I do have it under “Data protection” but it’s not Enabled.
As far as I can see the only things currently set up are “Scrub Tasks”, due in 7 days.
What if you enable it and set the day for all seven days of the week, and set the hours to 00:00 through 23:59?
I’ve set the resilver priority to all the time now. Let’s see what comes of it.
Digging around a bit I found a small bit of a curious coincidence:
(I didn’t quite match the time windows but the start timestamps should be visible)
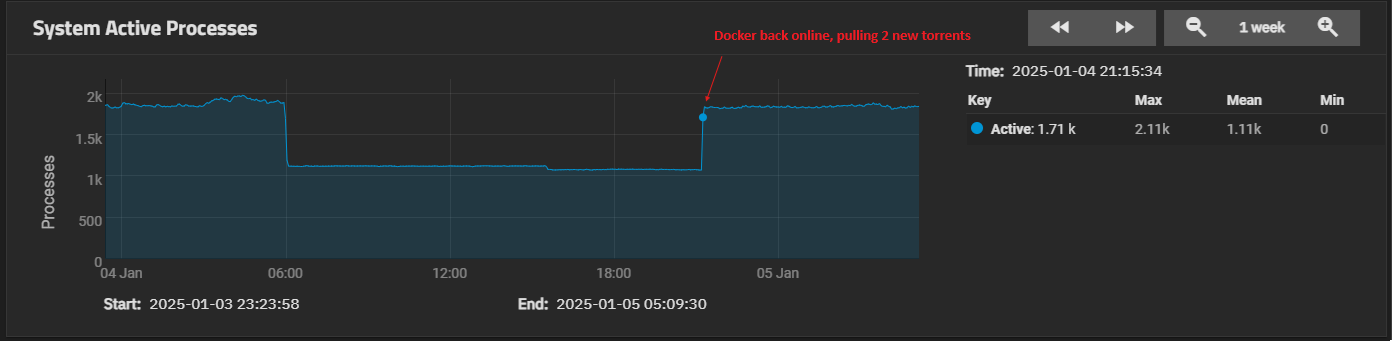
This reminded me that I shut down my whole Docker media stack at some point to try to make the expand faster - and re-enabled it right before the speeds went up. Is it possible that it was just the new data that got adjusted that quickly? But the new data was nowhere near the 3TiB progress reported by zpool status
Yes - it definitely looks to me that the data written to sdd was new data which is being written to all 4 drives during the expansion.
The numbers reported in zpool status are known to be very inacurate.
I’m just reporting back for posterity. My RAIDZ1 expansion has been completed and is now scrubbing, with the capacity of 3 disks:
$ sudo zpool status hdd_array -v
pool: hdd_array
state: ONLINE
scan: scrub in progress since Sun Jan 5 20:38:00 2025
2.58T / 10.6T scanned at 1.09G/s, 1.50T / 10.6T issued at 649M/s
0B repaired, 14.16% done, 04:05:24 to go
expand: expanded raidz1-0 copied 10.6T in 1 days 20:34:52, on Sun Jan 5 20:38:00 2025
config:
NAME STATE READ WRITE CKSUM
hdd_array ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
28b6cbd7-3726-447e-a894-5d618c9ab79f ONLINE 0 0 0
c71373d1-b30a-43b9-8f26-51e249021d5d ONLINE 0 0 0
1879b64d-45b0-42a9-8d48-b0381f87a21f ONLINE 0 0 0
336608bc-9edf-43e8-a630-55f24fbbbced ONLINE 0 0 0
Between “resilver priority” set and the last boost of speed was about ~1h. Another batch of downloads expectedly triggered more activity on all drives for the ~45min they took, but for whatever reason the speed persisted until the end. The last read spike is from the scrub.
I can’t explain any of this to myself so I’m going with the idea that the resilver priority just took a bit of time to kick in because I can’t rationalize why external disk activity would improve the expansion process for longer. Even if I’ve naively tried to reproduce that behaviour from yesterday earlier today ![]()
So, thank you very much @winnielinnie ![]()
Naturally also thanks to everyone who otherwise chimed in, I’ve learned a lot.
If anyone would like me to check / run / test anything (@Davvo ?), let me know, I’m happy to provide more info.
I have gone through this process. There is nothing you can do but wait.
When it has finished, the capacity of the Pool will jump up.
Mine took a week. The system has to recalculate all the parity data across every drive. A fast CPU helps here.
I must admit though 8.47M/s does seem slow. Mine was in the 60’s, and my CPU is only an i5 7500.
Just for factual accuracy this is NOT the case. When expanding, it does NOT recalculate the parity - it just spreads the existing blocks with the same parity across one more disk.
So if you had (as OP did) a 3x RAIDZ1 and you add a 4th drive, you start off with records which have 2 data blocks and 1 parity block, and after expansion all the old data still has 2 data blocks and 1 parity block - but any new data is written with 3 data blocks and 1 parity block.
And this is why you should run a rebalancing script afterwards - because it will take 3 records consisting of 2 data blocks and 1 parity block (9 blocks in total) and convert it into 2 records of 3 data blocks and 1 parity block (8 blocks in total) thus recovering 1/9 of the used space.
The reason that expansion does this is so that it doesn’t mess with snapshots. From a snapshot perspective the blocks have stayed the same - ZFS just creates a map from the old block locations to the new ones. If the expansion process recalculated the parity then it would be a COW operation which would impact snapshots - which is why it is left for a rebalancing script to be run by the user who is able to determine the impact on their snapshots.
I am not sure whether this is true or not - my guess is that this is unlikely to be true because:
Parity calculations do not need a fast CPU generally.
Expansion is not doing parity calculations anyway (except to verify the records as they are read as normal).
The expansion functionality is pretty much I/O bound.
The slowness has been identified as being caused by I/Os being single blocks and has been addressed in a ZFS fix which is not yet in TrueNAS - but the expansion process involves copying one block of the majority of existing records to the new drive (expanding from 3-wide to 4-wide it would be 1/4 of all existing blocks) to the new drive and is never going to be instantaneous.
I would be interested to see some CPU graphs during an expansion process to verify whether a system is indeed CPU-bound or not.
Mine completed today and it also took a week - was very slow 5mb/s slow. It also got to 100% and did not finish, it finished at around 110%; once it got to 100 it stopped estimating time remaining.
Another side effect of the broken size reporting, I suppose.
no - if you read the openZFS PR it is clear that this is an entirely separate issue.
I question the wisdom of going 3xz1 to 4xz1 on 8TB disks in the first place.
Wouldn’t this be a classic use case for:
Even better might be to do something similar but with 6xraidz2 or 8xraidz2, so there’s not need for expansion again any time soon.
This seems like a missed opportunity to get off raidz1 for this data.