So, new kernel resolved the incompatibility for the restart, but you still have hardware issues or incompatibility.
I don’t know how you can tell it is an hw issue / incompatibility.
Anyway, I ran the indexing of one big folder and it crashed (just to mention, since the upgrade, the system restarted instead showing nothing).
From photoprism debug log last few lines:
time="2024-10-03T07:22:00Z" level=info msg="convert: converting DSC03058.ARW to DSC03058.ARW.jpg (darktable-cli)"
time="2024-10-03T07:22:00Z" level=debug msg="exiftool: extracting metadata from 'smartphone/myfolder/RAW/DSC03059.ARW'"
time="2024-10-03T07:22:00Z" level=debug msg="cache: created 4d49392aea7166ff98614cf1666b17829eeb81a8_exiftool.json"
time="2024-10-03T07:22:00Z" level=info msg="convert: DSC03056.ARW.jpg created in 1.840076544s (darktable-cli)"
time="2024-10-03T07:22:00Z" level=debug msg="index: created DSC03056.ARW.jpg"
time="2024-10-03T07:22:00Z" level=debug msg="metadata: fc5830e76251ec0b37724d81bb4a6b855ddb4e3c_exiftool.json not found (no such file or directory)"
Then I re-ran the same index and it worked perfectly.
Could be something related to the cache?
cache-path | /photoprism/storage/cache
Is hard to think that 1 metadata file missing/not generated can trigger a total system crash… Despite, if those error are a lot, Is more plausible.
Maybe Is worth to check exiftool -ver inside the container, and why not try to manual generate the metadata JSON on one of those RAW file.
Also, try to cap-reduce container resource. Your spec are totally good but maybe this prevent system to reboot
1 Like
There are a lot of “missing/not generated” but after the second re-index it worked fine.
What’s your suggestion about reducing resources? My first idea was to cap the workers to 2 (default 4), limiting at docker level is dangerous according to photoprism.
Yeah, was thinking about PHOTOPRISM_INDEX_WORKERS but also
PHOTOPRISM_READONLY and maybe disable some other stuff like face recognition (at least for test) PHOTOPRISM_DISABLE_TENSORFLOW.
Also check your swap Memory, try increase a bit of Is 4gb or less.
Thinking on we are talking about reduce resource on your system, despite i’m running flawlessy photoprism in a virtualized alpine linux, with 1 virtual core CPU and 4gb RAM shared with other 15 container Is such weird ![]() but out of those im out of idea
but out of those im out of idea
1 Like
Will try tomorrow but it feels like photoprism crashes because of some limit, but again my system was never above 40% utilization.
How can I change the swap? I think it is not possible on zfs system?!
I used glances for monitoring my VM, and set properly resource, include swap usage (obv you can do via shell too, but Is pretty light and usefull for other stuff too)
version: '3'
services:
glances:
image: nicolargo/glances:latest
container_name: glances
ports:
- "61208:61208"
volumes:
- /:/host:ro
restart: unless-stopped
command: glances -w
I don’t know exactly how add or what impact can have edit swap on Scale, try other things maybe before
Ok, I think we made some progress here ![]()
I disabled raw processing (which I didn’t need anyway because I will process my RAW in lightroom first) and restarted the indexing → crashed.
Then I set the workers to “2” and… magic! Full reindex with no issue at all.
At the end I had 95% of memory occupied
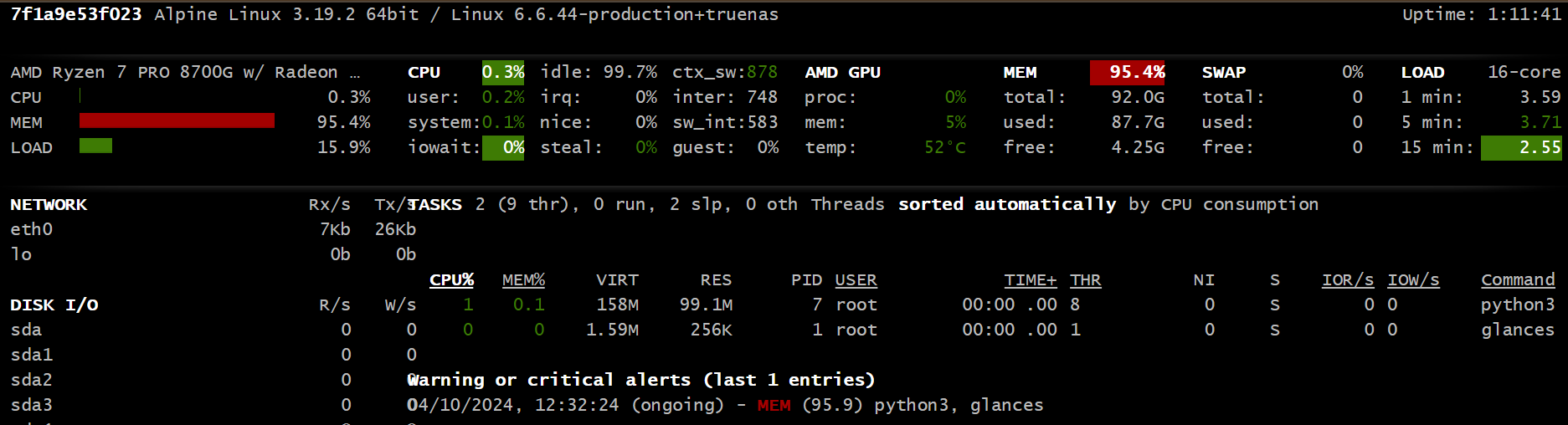
but mostly from zfs cache:
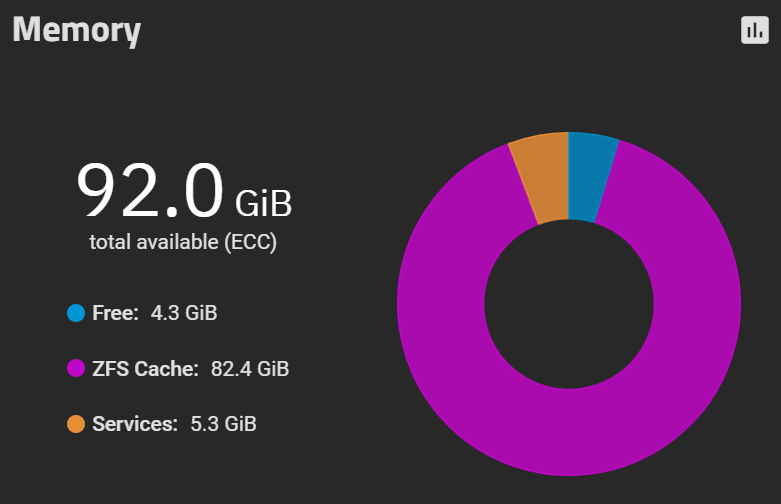
I don’t know… I guess two is better than 4? TBH, with 2 it feels faster ![]()
1 Like
I have capped at 1 from beginning and never try to increase. So, if system Is really ok now, don’t put more workers. Try if other crash happens again on normal rescan!
For the RAM, nothing strange (TN will use all unused RAM as cache, releasing on need).
What Is strange to me Is the 0 swap memory (but prob Is strange only for me due my in-experience ![]() )
)
1 Like
Same for me, but I guess either it doesn’t need swap OR zfs doesn’t really have swap?
Anyway, thank you so much for your support!!!
1 Like