smbd issue where it could go OOM is fixed in 24.10.
1 Like
This issue was never solved for me either.
On the latest release it’s still not just SMB but also NFS that will cause these OOM crashes every time a degree of real load is placed on the Truenas server. The underlying ZFS memory behaviour is still broken.
I’ve had to write it off and move to another solution for now as there was no traction on getting it resolved, but I still have the truenas server and will re-test 24.10 when it releases just in case.
What solution did you end up going with? I just went back to Core hoping this would get fixed soon, but I’m losing confidence it will.
TrueNAS 24.10 was just released. We don’t have OOM reports for it so far. If somebody still do, please open the ticket with relevant details.
I’m holding off until the next release, it looks like there may be a possible hotfix in the works already: SMB service randomly turns off due to going OOM - #12 by awalkerix
Really hoping this does the trick, I’m excited to get off TrueNAS Core.
Yea, that fix will land in the hotfix release later this week. So far its the only OOM we’ve seen, and it wasn’t ZFS related at all, Samba specific for that particular workload.
1 Like
Hi,
Truenas Scale EE 24.10 here.
“Dec 21 13:49:45 truenas kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=df25152698d89dbaacac10f583933d03df2d9fe334e721676fa6a7bc8d3dcb90,mems_allowed=0,oom_memcg=/docker/df25152698d89dbaacac10f583933d03df2d9fe334e721676fa6a7bc8d3dcb90,task_memcg=/docker/df25152698d89dbaacac10f583933d03df2d9fe334e721676fa6a7bc8d3dcb90,task=ffmpeg,pid=3524723,uid=0”
It might be related to the same issue.
@Momos Do you have any memory/ARC statistics for the time it happened? Because with TrueNAS no longer having swap partitions any misbehaving or just requiring too much resources application can end up in that position. All that TrueNAS can and should do is to try shrinking ARC as much as possible, but there is only as much it can do.
1 Like

Was there transcoding going on via Plex or Jellyfin around the time it happened?
Uncertain if related or useless information - I’ve noticed every time I shutdown/stop a VM the ARC MAX resets from my manually set values on boot. But I’m a few versions behind because I don’t currently have time; maybe this is already patched out.
No. Frigate app was running.
happened again:
Dec 23 02:45:51 truenas kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=9704b43b3df9625462a22e37d267fa101cd2129fbd0689288628f80046bb7d34,mems_allowed=0,oom_memcg=/docker/9704b43b3df9625462a22e37d267fa101cd2129fbd0689288628f80046bb7d34,task_memcg=/docker/9704b43b3df9625462a22e37d267fa101cd2129fbd0689288628f80046bb7d34,task=python3,pid=1115451,uid=0
No idea what is causing it:( , but the Frigate app crashes and doesnt restart, gets stuck at deploying. Then if works fine again for a few days/hours.
How much RAM did you give Frigate, do you have other apps?
And again it happened.
Dec 23 12:39:30 truenas kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=c275e4dd561d2a2d387c61e519a482a4369d58be26f8a35a4462305637bbec17,mems_allowed=0,oom_memcg=/docker/c275e4dd561d2a2d387c61e519a482a4369d58be26f8a35a4462305637bbec17,task_memcg=/docker/c275e4dd561d2a2d387c61e519a482a4369d58be26f8a35a4462305637bbec17,task=ffmpeg,pid=276860,uid=0
This is my app list:

Not eating much from my system
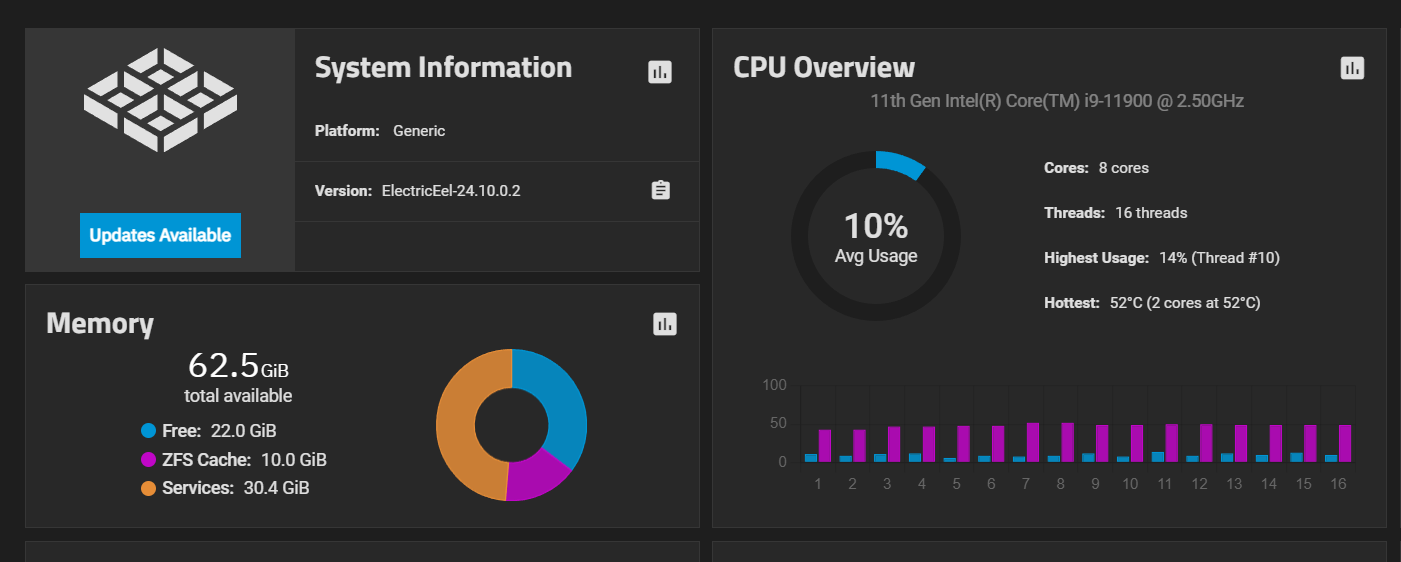
To Frigate app i gave 12 GiB. And this last crash Frigate was still up and runnig. There does not seem to be a common denominator.
PS: side question about memory allocation for Apps in EE: does the sum of allocated memory should be under the total system memory or it allocates based on the need? as far as i can tell the second seems to hold true.

I don’t think i have a memory issue.
Maybe create an SSH session and run command top -o RES to watch resident memory for applications before OOM killer gets triggered. Typically the problem application will float to the top of that output.
1 Like
i can run this in a putty window from a windows PC. Is there a way to autosave the results to a file every minute for example ?
Cant stare at the screen until something bad happens …
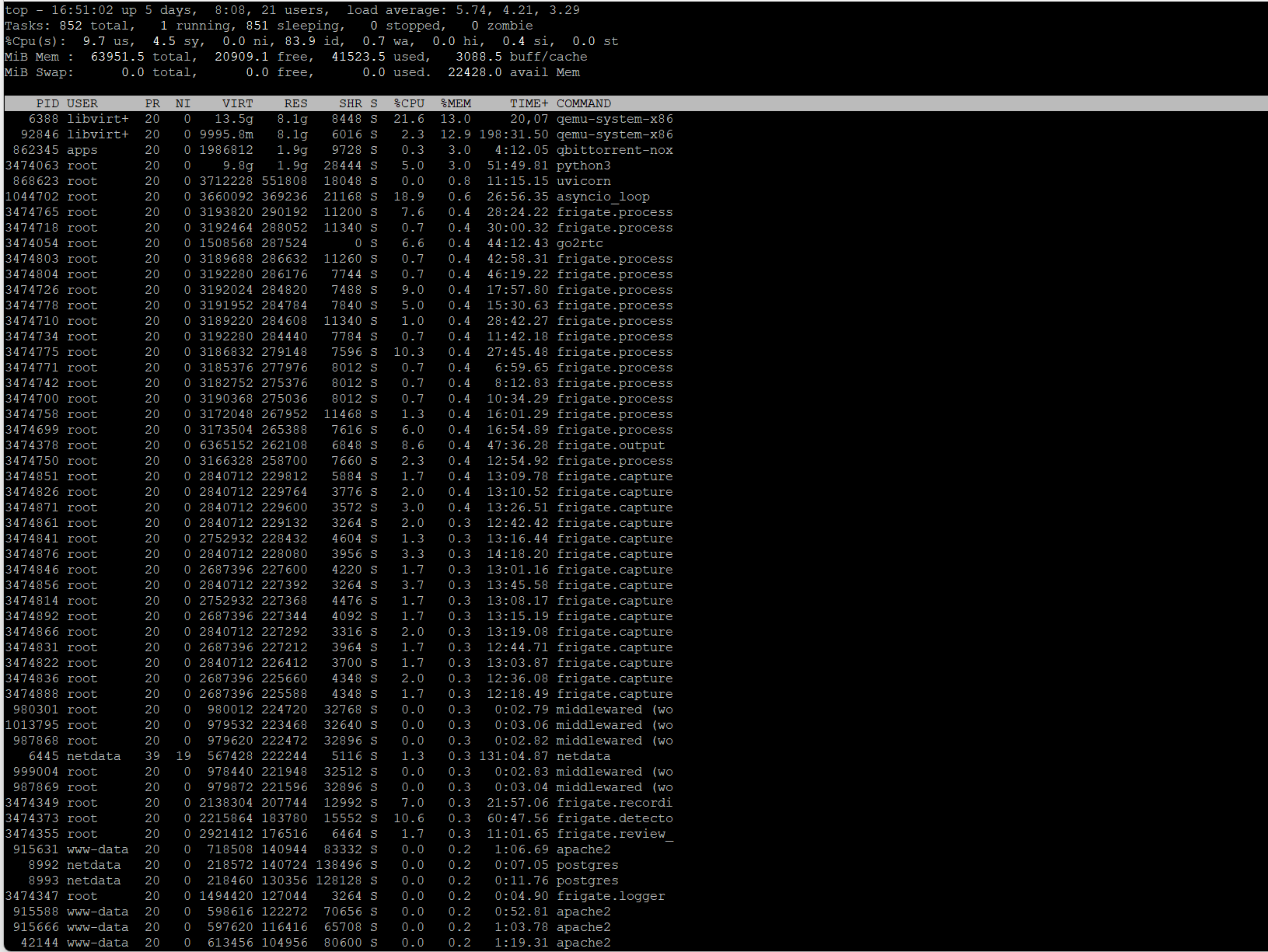
and another crash.
Dec 23 19:15:28 truenas kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=c275e4dd561d2a2d387c61e519a482a4369d58be26f8a35a4462305637bbec17,mems_allowed=0,oom_memcg=/docker/c275e4dd561d2a2d387c61e519a482a4369d58be26f8a35a4462305637bbec17,task_memcg=/docker/c275e4dd561d2a2d387c61e519a482a4369d58be26f8a35a4462305637bbec17,task=python3,pid=3474063,uid=0
of course i wasnt watching the top screen ![]()
Does the issue persist if you limit the memory to 8GiB? Maybe it will work around the issue? It looks like you have a VM also consuming RAM, so it may be a combination of factors here leading to resource exhaustion.
I’m sure it is a combination of factors.
Things i tried: setting the Frigate App memory to 6GiB, then to 8GiB, playing with the number of cores allocated from 4 to 8, and combinations of the above.
I think it might have something to do with HW acceleration not working as intended on the iGPU. Frigate app shows only 1% on the Intel GPU, so most of the processing goes to the CPU probably.
Will keep testing and report.
1 Like