I never noticed this on TrueNAS Core 13.3, until I decided to create a new dataset.

I know that this has already been available to ZFS, but now it’s exposed by the GUI?
Is this an oversight, or does iXsystems believe that 16-MiB recordsize is considered tried-and-true to allow for datasets on a TrueNAS server?
For those using SCALE, does the drop-down also make 16M available?
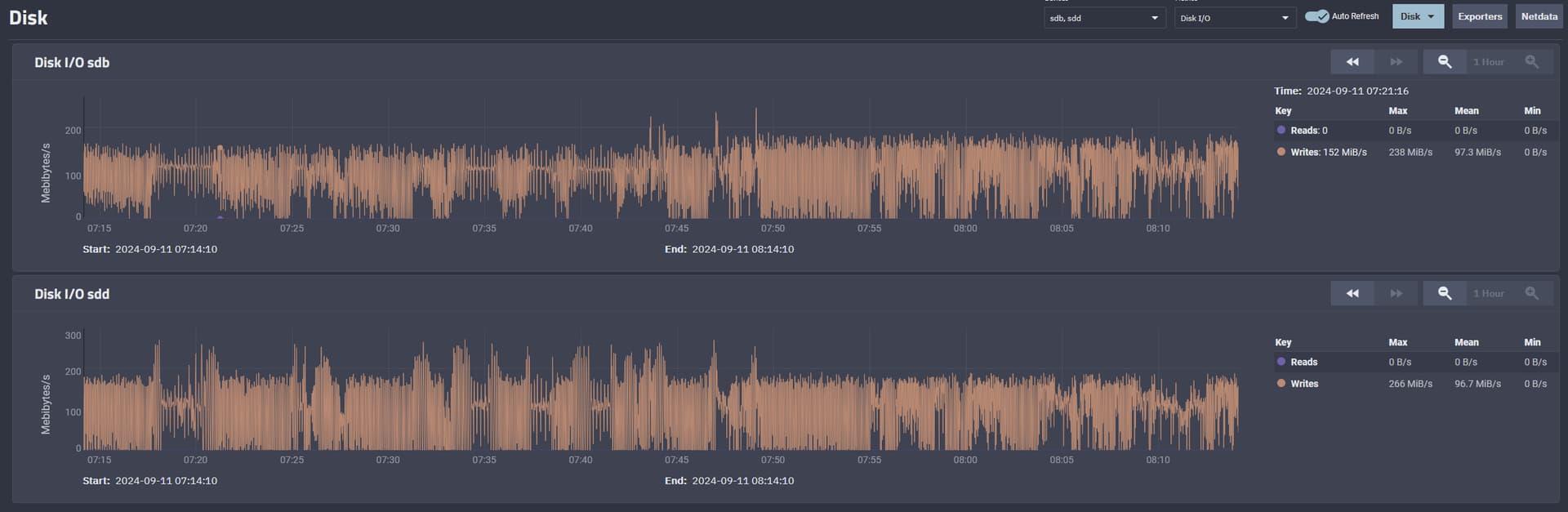
I’ve had phenomenal results with pretty much all of my datasets using 1-MiB recordsize, which was the highest available level (in the GUI) for TrueNAS Core 13.0 and prior.
Is there an obvious caveat I’m missing that would cause performance and efficiency issues by setting it to 16M? Because of inline compression, no files will consume an additional ~16 megabytes due to “padding”. So a 500 KiB file will consume approximately 500 KiB. The same is true for a 2 MiB file, a 10 MiB file, and so on. Nor will a 33 MiB file consume 48 MiB on the storage medium. It will consume 33 MiB, as expected. (First block, 16 MiB. Second block, 16 MiB. Third block, 1 MiB, as the padding of zeroes are compressed to nothing.)
So talk me out of this! Tell me why I shouldn’t set the recordsize to 16M? Trample on my dreams, why don’t you? ![]()