root@truenas[/home/truenas_admin]# zpool list test_pool && zfs list test_pool
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
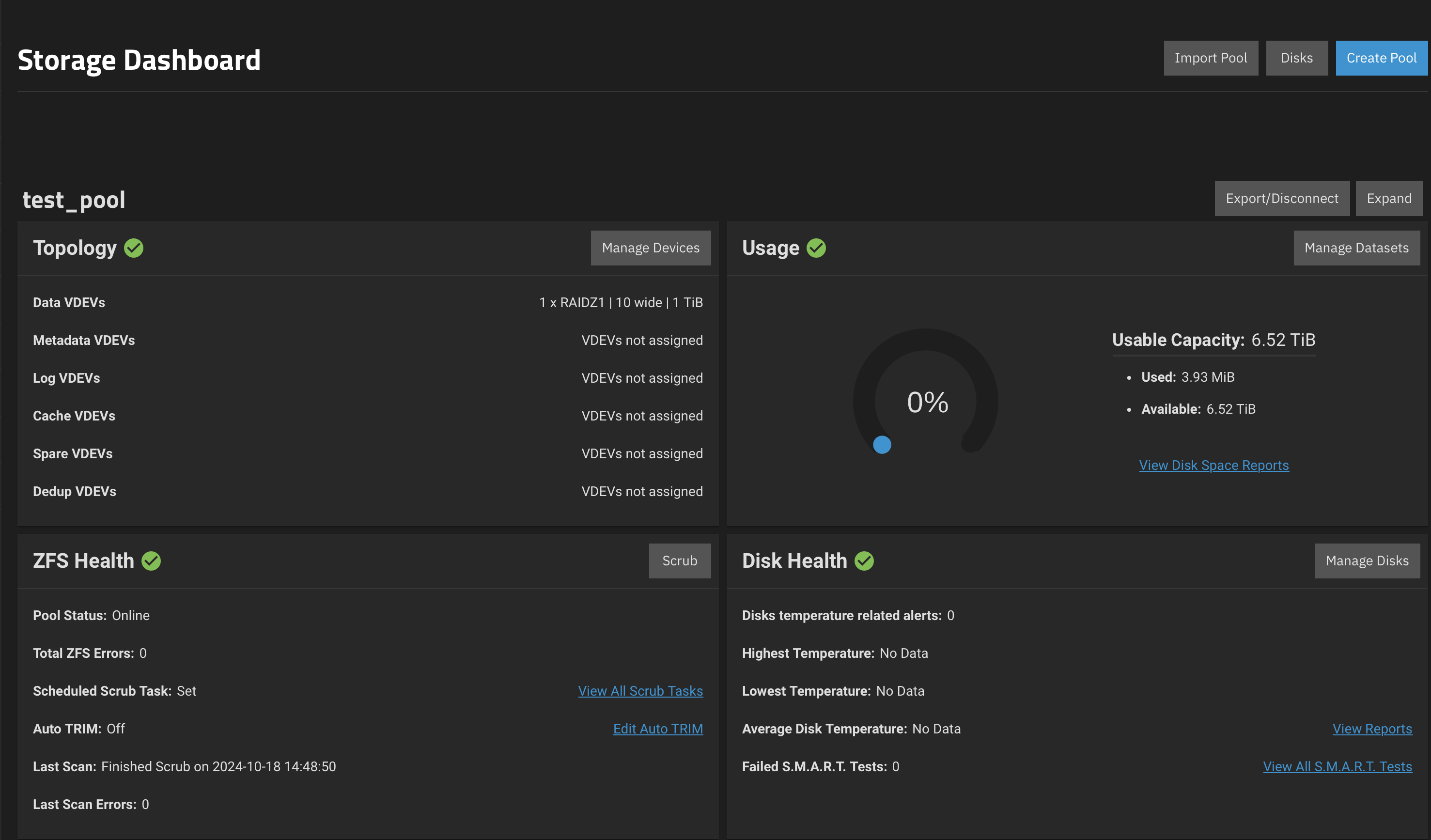
test_pool 9.98T 6.04M 9.98T - - 0% 0% 1.00x ONLINE /mnt
NAME USED AVAIL REFER MOUNTPOINT
test_pool 3.93M 6.52T 128K /mnt/test_pool
Which means, that it appears that 3.5T of parity overhead is present, when in reality its only 1T. This means that the parity overhead appears to be 3.5x higher than it should be.
Now I’m curious what will happen if you dd (from /dev/urandom) a 6.5 TiB file? Will the pool claim you’re at 99% capacity? Will it “change” the pool’s actual capacity when it realizes what a liar it is, and then “correct” itself to claim you’re at 75% capacity?
/*
* Compute the raidz-deflation ratio. Note, we hard-code 128k (1 << 17)
* because it is the "typical" blocksize. Even though SPA_MAXBLOCKSIZE
* changed, this algorithm can not change, otherwise it would inconsistently
* account for existing bp's. We also hard-code txg 0 for the same reason
* since expanded RAIDZ vdevs can use a different asize for different birth
* txg's.
*/
static void
vdev_set_deflate_ratio(vdev_t *vd)
{
if (vd == vd->vdev_top && !vd->vdev_ishole && vd->vdev_ashift != 0) {
vd->vdev_deflate_ratio = (1 << 17) /
(vdev_psize_to_asize_txg(vd, 1 << 17, 0) >>
SPA_MINBLOCKSHIFT);
}
}
So, if the code can’t be changed because its used for BP calculations, it seems like NEW code needs to be added for the ALLOC stats, and the BP calculations need to use the old code.
As mentioned before, I don’t know all the dependencies and requirements at this level of the ZFS code… but this situation is not good for end users.
which would be why I’m currently replacing 8T disks with 22T disks… I can run that test when it finishes… assuming that the expansion works and that isn’t buggy too. ↩︎
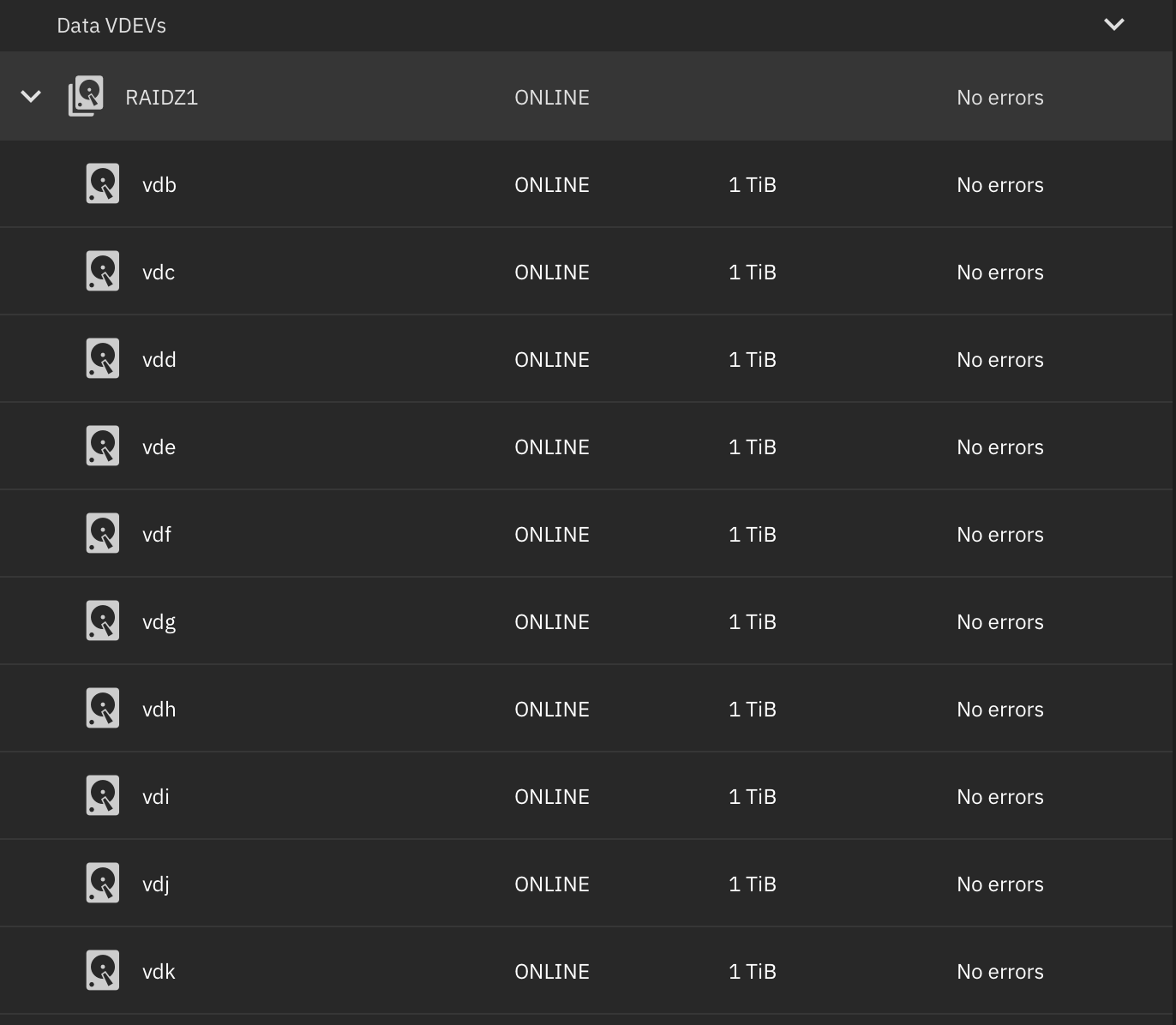
When the expansion completes, the additional space is available for use, and is reflected in the available zfs property (as seen in zfs list, df, etc).
It is not fully reflected.
RAIDZ vdev’s “assumed parity ratio” does not change, so slightly less space than is expected may be reported for newly-written blocks, according to zfs list, df, ls -s, and similar tools.
And the above does not seem to fully capture the issue, except that it does state that the “assumed parity ratio” does not change, and that is what is used to determine how much space is available from the set of disks… apparently.
I think that adding drives, and keeping files in the original drives is the problem.
By expanded new files are distributed among all drives but the old files remain in the prior ( original ) drives.
I think that upon the new setup, if the data is reshuffle among the drives, even tho slow, would solve the problem.
If they don’t fix it to our expectations, I’ll become a dev myself. Give me some time and I’ll fix it. Say … 'bout 10 years ?. Yea.
If it wasn’t clear, I did my tests with an empty pool.
The issue is (I believe) the capacity is determined by multiplying the size of the members of the vdev by the number of members, and then by the original parity ratio. (simplifying)
If it were strange calculations by the middleware it could be fixed at any time.
But here it is deep into ZFS code. However faulty (hardcoding assumptions , including quite possibly a wrong one about blocksize?) this might be, it will take LOTS of time and efforts to fix. Possibly on the same order of magnitude as raidz expansion itself.
Sure, OpenZFS 2.3 is still in its RC stage, as of this post, but it’s unlikely that a release-candidate will see such a correction before its stable release. ↩︎