Agreed. This is not “unsafe” on the surface. But for a filesystem that boasts resiliency, stability, and flexibility, it’s just silly to not even display a pool capacity that reflects a fairly accurate size. (Because it’s using a “pre-expansion” calculation, it’s okay for it to lie about how big your pool really is? Sure, maybe for a new filesystem being developed, or some beta that is experimenting with a new feature, but for a stable release of a “mature” filesystem?)
And while it’s not outright “unsafe”, it affects how the user stores and manages their data. Imagine that you believe there is only 2 TiB available on your pool (when in reality you actually have 7 TiB usable space remaining.) Would that not play a factor in your purchasing decisions to expand your pool further? In your pruning decisions? In your snapshot management?
This issue is more than just a poor estimate.
I can understand imperfect displays of “total pool capacity” and “available space”, due to padding, reserved metadata, checksums, predictable parity (unavailable for user data, and hence not “usable”), inline compression, and etc. Basically, things that can amount to “rounding errors”.
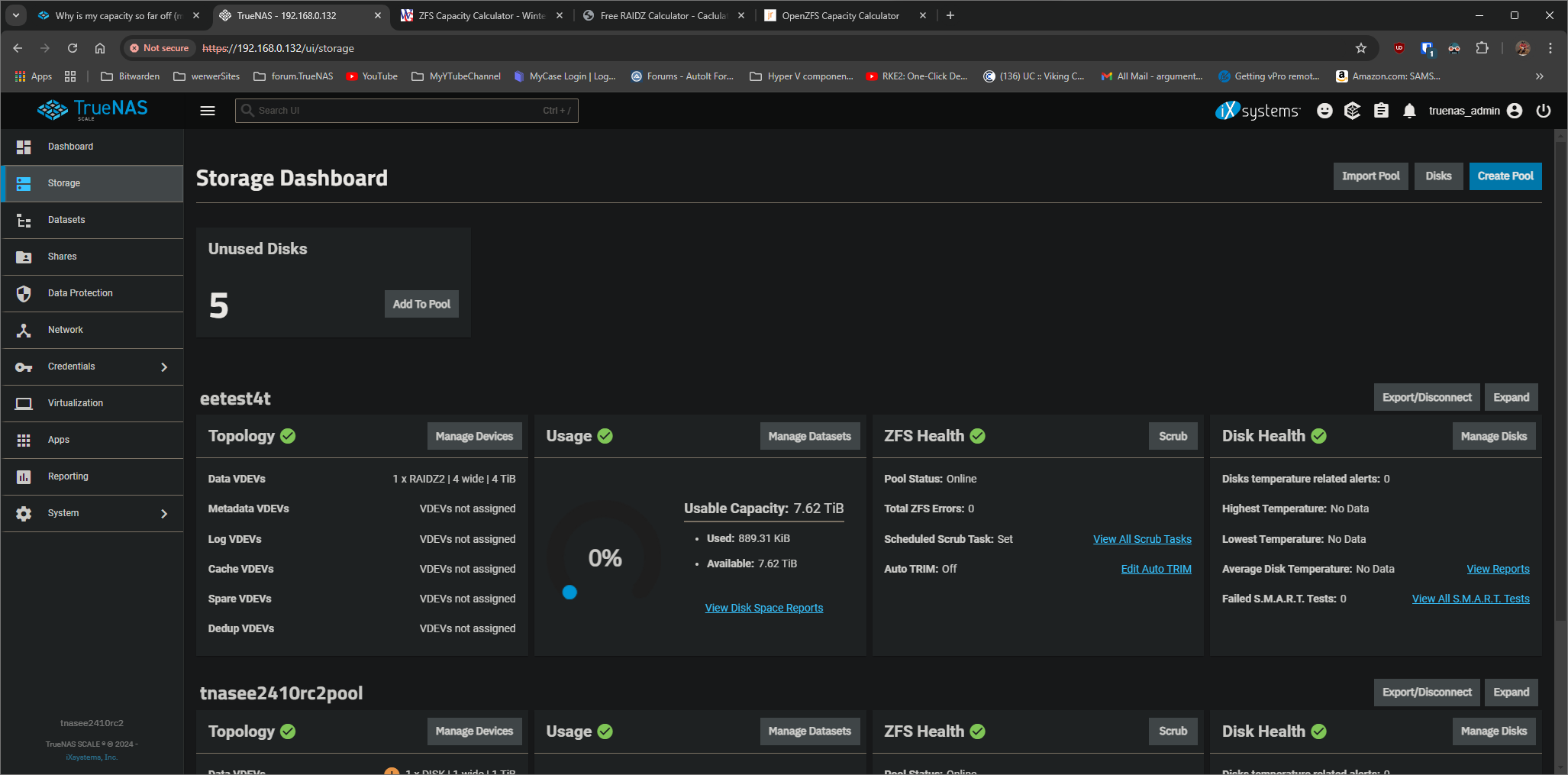
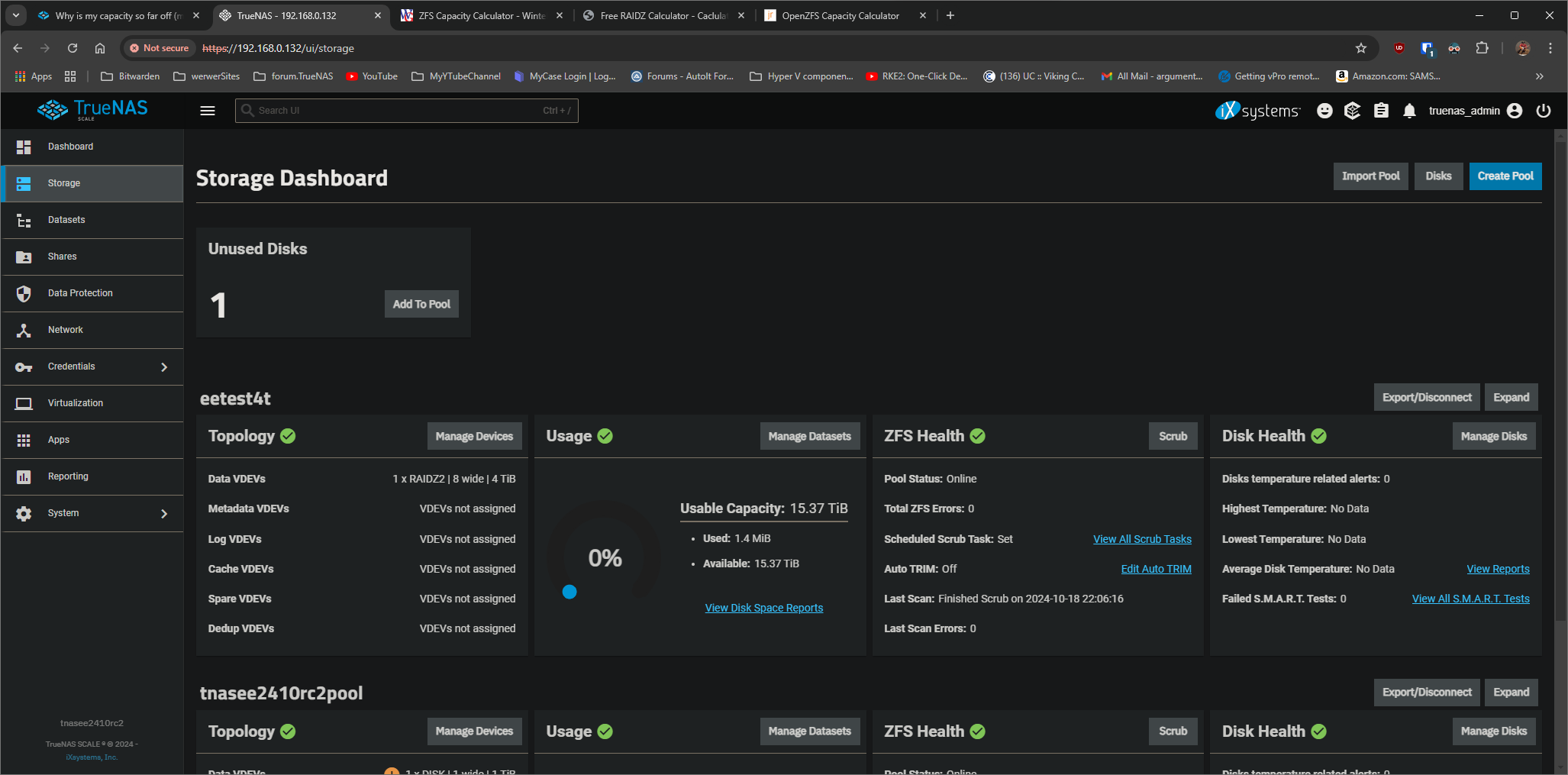
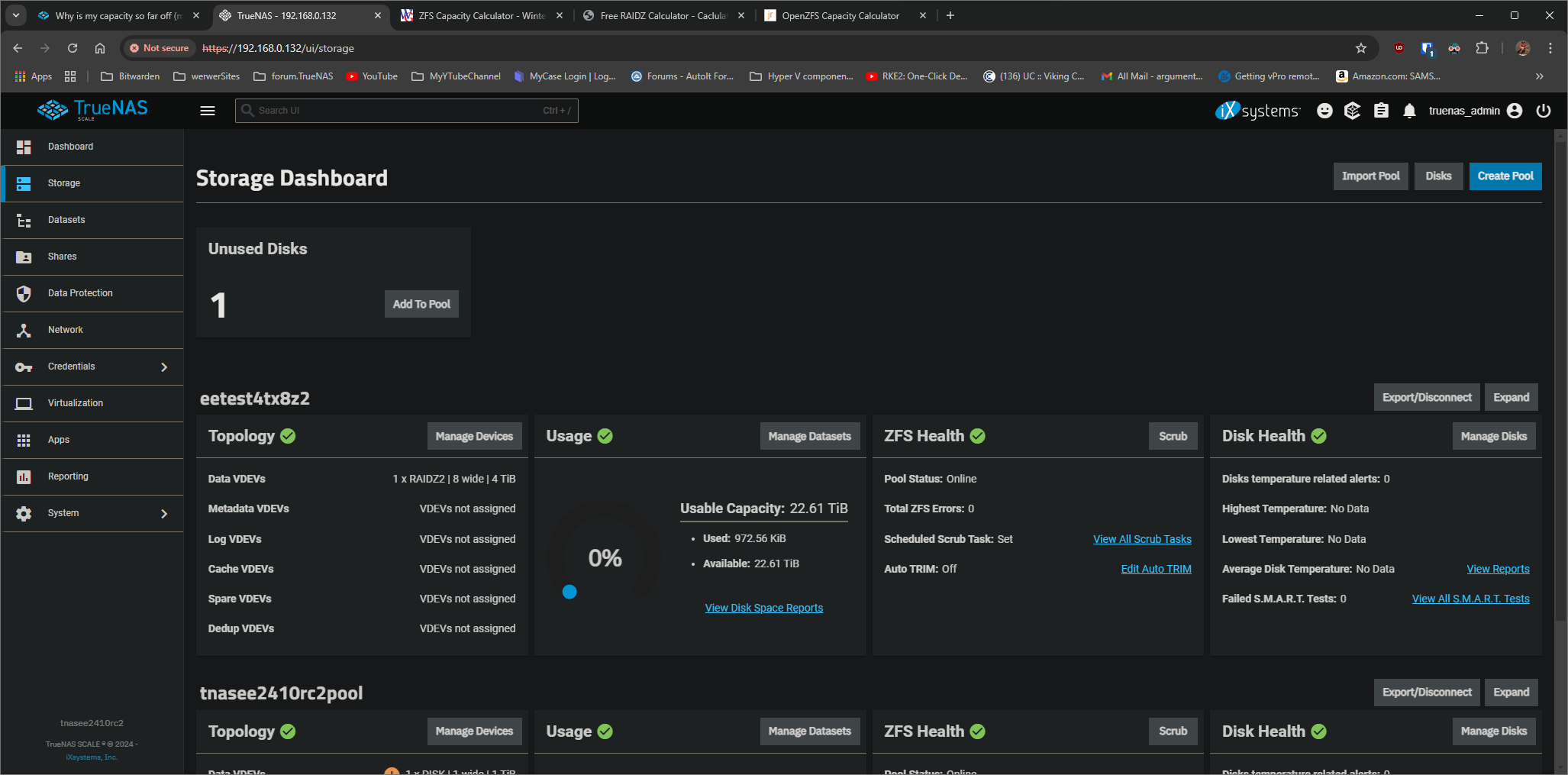
But this issue, as demonstrated by @Hittsy and @Stux is just outright wrong, on the scale of almost an entire 18 TiB’s worth of usable storage space. (Depending on the underlying member drive capacities.) There’s really no excuse for it. We can’t expect the user to “calculate the real numbers” in their head.
When it comes to things like inline compression (which can indeed offer “more space”, depending on what types of files you are saving), the total pool capacity is a known amount, and remains as such. Even the available remaining space is fairly accurate. (You might have 2 TiB of “available space”, and decide to save 1 TiB of highly-compressible files. These files end up only consuming 500 GiB on the pool. Predictably, you still have 1.5 TiB of available space, and your pool’s total capacity remains consistent. Any “discrepancy” can amount to a rounding error, which is acceptable for most users.)
While RAIDZ space calculation isn’t a precise estimate, you at least get an idea of “This is how big my pool is.” However, after you expand your RAIDZ vdev you’re expected to carry a calculator with you to understand how big your pool really is, let alone how much available space remains.
Just like “corrective receives” introduced with OpenZFS 2.2, this new feature introduced with 2.3 seems unfinished but “good enough”, where the developers just figured “It does what it needs to do.” It carries a degree of “hobbyist” project.
It doesn’t come off as professional quality.