Hey all, I’ve got a doozie of an issue here. I have an old Dell R620 running 2 Xeon 2620s and 16GB of RAM, and I threw an LSI SAS9207-8e and flashed the Dell RAID controller to an HBA firmware so I could use this as a ZFS replication target for backups. The drives would be inserted into a Netapp DS4246 and connected via the LSI HBA mentioned above.
So I created a pool out of 4 4TB Ironwolf NAS drives in a RAIDZ2 for Server Backups, and another pool out of 2 vdevs of 4 12TB Seagates in RAIDZ2 as well. Everything was running smoothly and no issues to speak of.
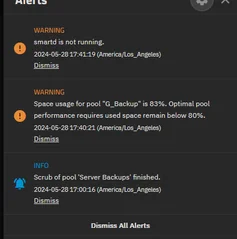
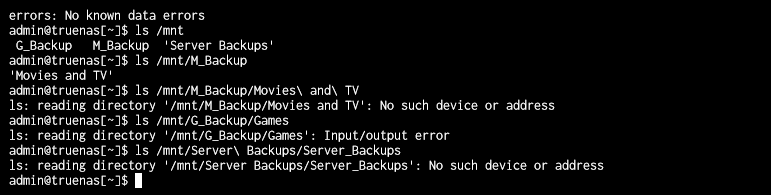
Then I created the third pool. 4 10TB HGST drives. I ran ZFS replication on it, and all was well for a few days, until Sunday. I laid down in bed and got 20 emails about being unable to read SMART data across any of the drives. I went to take a looksie, and all the pools were in a suspended state, but appeared to be online in the web gui. I poked around in the shell and couldn’t get anywhere, so I chose to reboot. From then on it doesn’t seem like I can get the pools to work properly.
I have done a clean install on a few different versions of TrueNAS, and every time the third pool is imported and the system reboots, the following happens:
Smartd fails to run:
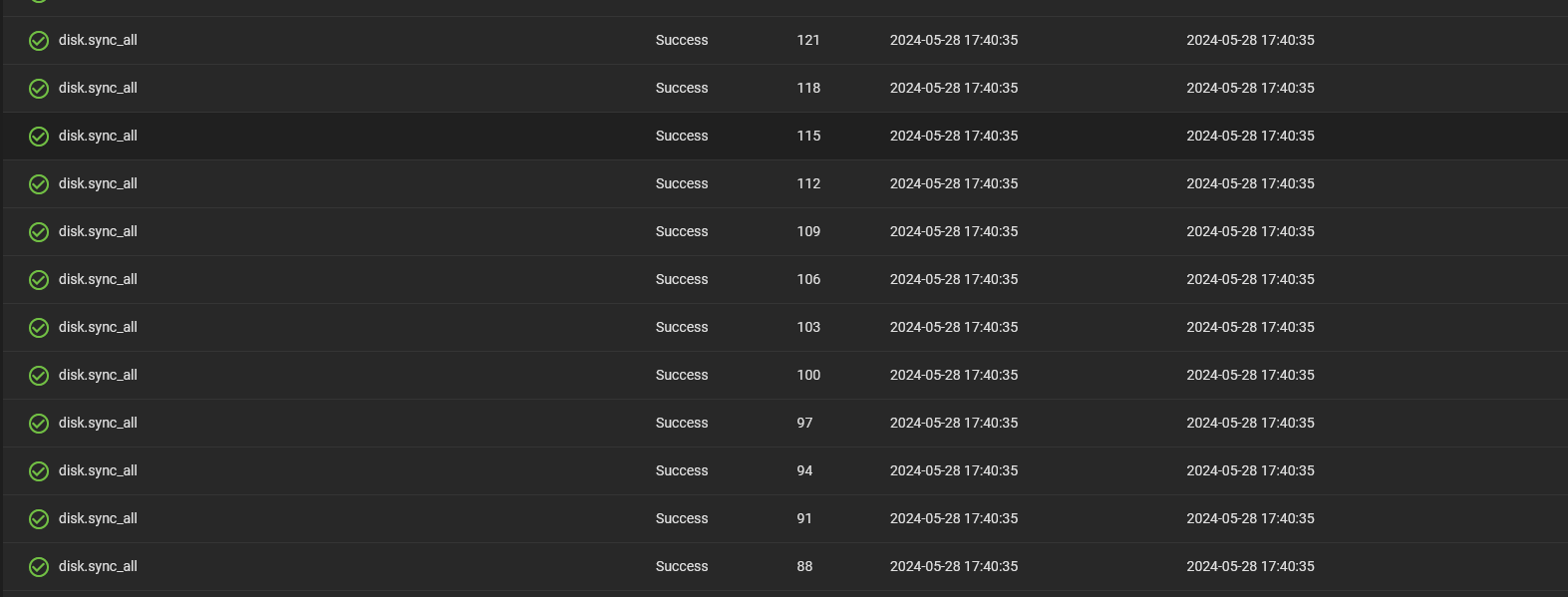
The system seems to run several disk.sync jobs, which never work quite right and leads to disks having labels that seem…off:
The prior screencaps are running on 23.10.2, but I see the same behavior on 24.04.1. The trigger seems to be having 3 pools, the order of import does not seem to affect things as far as I can tell.
I am unsure of the “why” here. The trigger is definitely having 3 pools, but I am unsure if this is a hardware limitation, or some random issue with TrueNAS. I have a new cable coming in for the HBA tomorrow so I’ll try that…But its very strange.
Just for fun, I tried importing the pools on CORE 13.3 to see if the issue was present there as well. It is not, so this appears to be an issue with either SCALE, or some sort of upstream Debian thing maybe?
So on Core 13.3, I imported all three pools and rebooted 5 times, and did not experience this issue. It seems SCALE specific…Not sure what would fix this though.
System → Advanced → Save Debug will do it. Then you can file a support ticket through the Report a Bug link at the top of the forums - don’t attach the debug as a regular file, but wait for it to confirm the bug was filed, and you’ll get a prompt for a secure upload portal.
Having a similiar issue with the same server r620 and lsi 9207-8e. If i reboot the server sometimes 1, 2, or all 3 pools will get IO errors and eventually lock out. If i keep rebooting eventually all the pools will come online and be happy. No issues on core this happened when i upgraded to scale. SAS card is in IT mode also tried another card model with the same issue.
Hey heads up, I was able to import my pools on CORE 13.3 BETA. Really not pleased with having to do that since CORE Is going the way of the dodo…But since there seems to be no fix in sight for this issue from the dev team, this looks like the best option at the moment…