Please read the linked resources as they give you the tools to answer most of your questions or directly address them.
I will respond to a few, not being able to run the numbers for the math required not being home and answering from my mobile.
If the new disk you are using to replace the failed disk fails during resilvering, your pool stays in a degraded state and does not gain back the parity to withstand further failures.
If at any point your degraded RAIDZ1 pool experiences the failure of one of the remaining disks, you lose the pool.
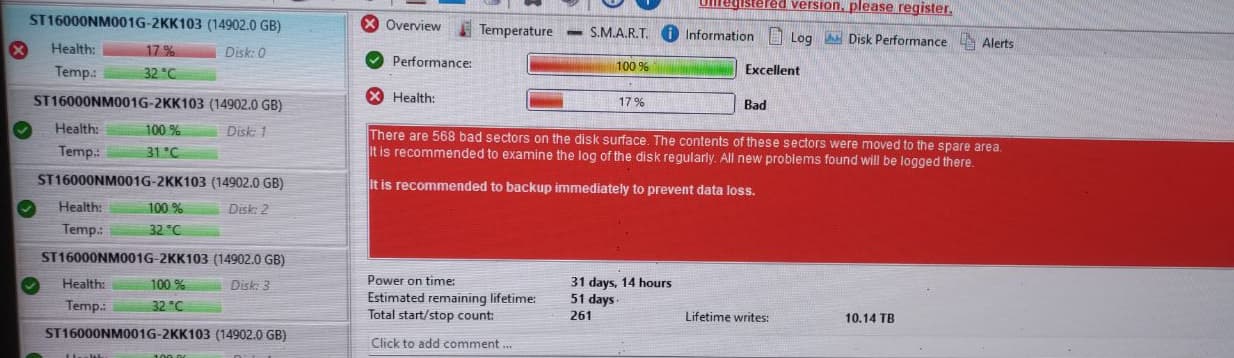
Doesn’t sound like it’s in a good state, but do you not run periodic long smart tests? Those are made to get a picture of the health of the drives and take decisions.
Basically, yes. You stress test the hardware before using it in order to have some degree of assurance it won’t fail on you as soon as you put it inside the system.
I reccomend to always burn-in your hard drives when you get them before putting your data on them.
The drives that should be used inside a NAS are the ones engineered to operate 24/7: if they fail after a few hours, because a few days are just a few hours compared to the 3-5 years they are guaranteed to last, your system dodget a bullet and the manufacturer earned a RMA. If your drives reaches unusually high temperatures during burn-in, that’s usually your signal to increase their cooling.
I burn-in my drives for a few days before attaching them to any pool. Professional folks burn-in them for weeks or even a few months, I am on the “if it did not fail on me after a few days of intensive use, it’s good for my personal use” camp.
Nope, each 4-way mirrored VDEV can withstand up to 3 drive failures before incurring in data loss: this means that a pool composed of 4x 4-way mirrored VDEVs can withstand up to 12 drive failures.
With symmetrical VDEVs performance is calulated per VDEV, then it’s multiplied for the number of VDEVs: assuming the use of EXOS X16 drives with a read speed (meaning streaming reads of big blocks and large files) of 260 MB/s, a single 8-wide RAIDZ2 VDEV will theoretically reach 8 - 2 = 6 * 260 MB/s which means around 1500 MB/s; since we have two VDEVs the pool’s theoretical read speed will be of 3000 MB/s, or around 3 GB/s. At least on paper.
256 GB should be and appropriate number, but the real size of the pool won’t be grater than 160 TB: still grater than 128 GB, meaning you should require 256 GB of RAM due to to the power of two rule. With 128 GB you should still experience great performance, and I guestimate that 32 GB would still be plenty for traditional home network speeds.
From unrelated reasons (ie excluding PSU failures), very low; do note that the chance of failure increases as time passes.
If you mean a physical impact, depending on the failure maybe; an improperly configured HBA (aka non IT-mode) is a different story.
For RAIDZ VDEVs not on CORE, it’s a feature landing in the next versions of SCALE.
You can only add more VDEVs to existing pools.
For MIRROR VDEVs, yes: you can add and remove drives as you require.
Parity data is actually striped across all drives. The concept of parity drives is a semplification.
Having more resiliency means that even if a drive fails, if the stress experienced during resilver brings another down the resilver will be able to continue, establishing again enough parity to withstand further failures. That’s why RAIDZ2 is better than RAIDZ1; read the linked resources for more in depth explainations
Finally, please leave me a heart as I spent several hours digiting on my small mobile keyboard with my big fingers in order to answer you; you are lucky it’s just me, @winnielinnie would have asked for an ethernal monument to immortalize his glory!