With VMs on HDD you really, really need to add a very fast NVMe SLOG, regardless of vdev type.
1 Like
It’s not.
A ticket has been filed.
1 Like
Me personally, my JF does run on another system under Mint Linux, and I do NFS shares, I also use said NFS shares for my NVIDIA shield to access the media library.
Back when i did this, I had choppy issues with SMB, but moving to NFS cleared that all up and everything is buttery smooth.
If you were running Kodi on the shield and NFS was better than SMB, chances are it was an older version of Kodi before they introduced the sweet caching options right from a system interface menu. With it, smb3/4 is awesome
Now back to the main thread, my 2 cents.
Scrubs do take time and do cause load and all those ARC cache misses are hurting also. ARC cache means hey you get to stream from RAM and I don’t need to dig around in disks to deliver the content. Low ARC hit ratios means it is spending a lot of time digging for things that aren’t cached. 128MB would do wonders here but that depends on how closely aligned everyone’s tastes are. Since the initial read from disk is straight into the ARC cache (if there’s room), each subsequent read of the same file will come out of the ARC resulting in higher ratio hits and fantastic performance. But running 10 streams, and it’s all different stuff (let’s say everyone is watching Attack on Titan but each person is on a different episode) there’s not much to gain from the ARC at that point. Still, more RAM has had a profound impact on my system I wasn’t expecting. A typical scrub on my 55% full pools with my 64gb of ram would take 24 hours. After doubling the ram, that time came down to 15 hours. Can’t guarantee you will have such great results especially because your pools are overstuffed, but it will help with the ARC at least.
We also may be looking at one of those rare instances where an additional fast cache drive for ARC may come in handy. An NVME drive contributing to caching vs. all your hot spinning platters, it’s no contest. I’m no expert here but Techno Tim (youtube) has some really interesting experiments and results with his Truenas box and using these unusual drive types.
2 Likes
The ARC caches both demand based data and predictive (read ahead) data. So even with 10 different streams, if you have enough ARC, it should be pre-reading based on the sequential read pattern.
Under 25.04.1 see /usr/sbin/arc_summary especially the sections on ARC accesses (demand, prefetch, etc.).
1 Like
Ahh I was missing the predictive bit. Will a dedicated arc cache and maybe an slog do any good here or just throw more ram at it?
What do you mean by dedicated ARC cache, the ARC is shared among all zpoolsan L2ARC (what TrueNAS calls a CACHE vdev) is per zpool. If you do mean an L2ARC, it can help, but note that almost any device deployed as a L2ARC (CACHE vdev) will be slower than system RAM and every entry in the L2ARC also has a pointer in the ARC. If your L2ARC is too big compared to the amount of RAM, there will be no data cached in the ARC, just pointers to the L2ARC, which is slower. From TrueNAS Hardware Guide | TrueNAS Documentation Hub, Add approximately 1 GB of RAM (conservative estimate) for every 50 GB of L2ARC in your pool. Attaching an L2ARC drive to a pool uses some RAM, too. ZFS needs metadata in ARC to know what data is in L2ARC.
SLOG (separate log device) is only useful for SYNC WRITES, it will make no difference to the performance impact of the SCRUB. A SLOG will make all SYNC WRITE operations faster. If you are loading your data via an SMB share, then it depends on whether your SMB client and the program calling it flag the write as SYNC. If you are using NFS then a SLOG will help as almost all NFS clients use SYNC WRITES.
All SYNC WRITES are committed to the ZIL (ZFS Intent Log) to meet POSIX SYNC specifications. If you have a SLOG then the ZIL is located on the SLOG, otherwise it is written at the start of the zpool itself. Note that a SLOG of 16 GiB is generally considered adequate for any zpool as it only needs to be able to hold 5 seconds of write activity. Unless the system crashes during a SYNC WRITE the ZIL is never actually READ.
3 Likes
Long way to say throw more ram at it but very informative, thanks for the technical details.
Do you have any idea of the recommended / ideal / minimal amount of RAM?
So 128 GB isn’t enough ?
Would it change anything to the scrub ?
I don’t know. Take a look at the arc_summary output and see how many hits and missies (and the ratio, what percentage are hits). Any hits are requests that do not have to go to the disks, but are coming out of the ARC. I have not looked at these ratios on a streaming server, so I don’t know what is rational. The more RAM you add the higher your hit rate will be.
If the read is satisfied out of the ARC then it does not have to hit the disks. So the more reads coming from the ARC the smaller the impact of the scrub.
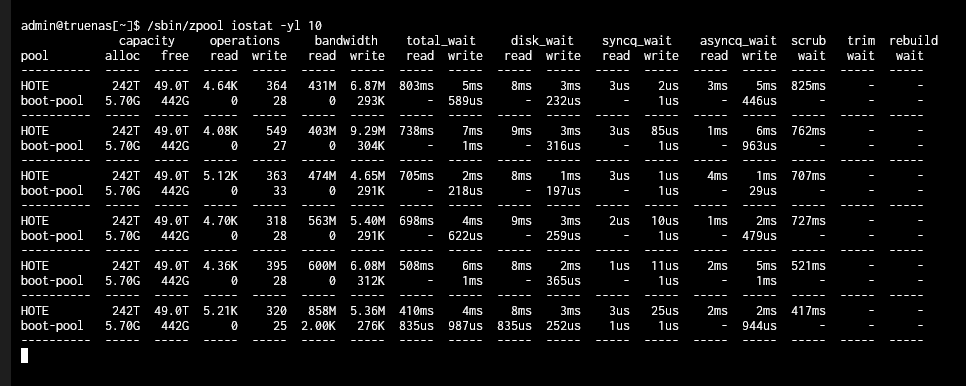
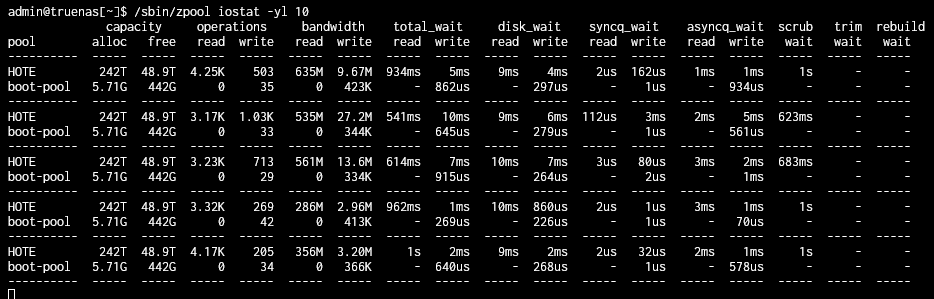
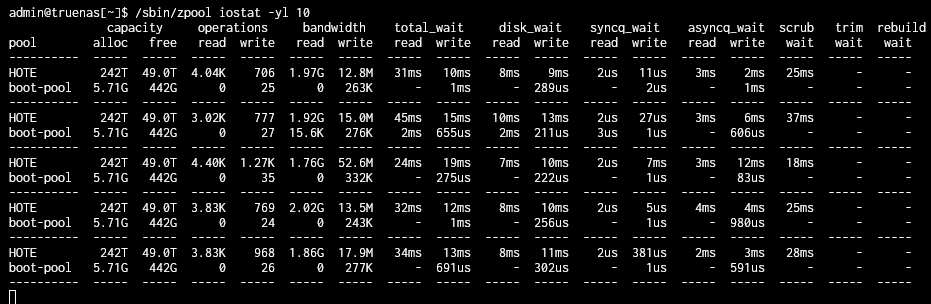
Have you looked at /sbin/zpool iostat -yl 10 during a scrub to see how much time you are waiting on the scrub (the wait scrub column)? Feel free to use 1 second update or 60 second update for different sample intervals.
Minimal: Officially 8 GB, but many would prefer 16 GB.
Recommended depends on your uses.
With 10G networking and/or some apps, make it 32 GB—or more depending how heavy your apps/VMs might be.
For iSCSI, 64 GB and up.
To play with dedup ![]() with a metadata L2ARC, 64 GB.
with a metadata L2ARC, 64 GB.
To play with dedup on RAM alone ![]()
![]()
![]() , 128 GB is a bare minimum… for under 20 TB of dedup’d data (personal experience).
, 128 GB is a bare minimum… for under 20 TB of dedup’d data (personal experience).
Ideal is always “more”… until it really does you nothing.
1 Like
Just my usual question: Are your HDDs CMR drives or SMR drives?
The Thosiba are CMR (and FC-MAMR).
The WD are UltraCMR (and ePMR)
OK, it is good news, so it is not the root cause of the long scrub times.
These are, however, large drives, which is a very valid cause for long scrub times if the pool is filled accordingly.
Based on the output from /sbin/zpool iostat -yl 10 it looks like the scrub code is doing the right thing. As the amount of data being read goes up the amount of time spent waiting on scrub goes down (the scrub job is throttled).
Going back to your original issue:
It looks like the degree of slowdown due to scrub is worst when there is little going on.
The largest scrub wait time I saw was about 1 second, it sounds like your are seeing much longer delays. Perhaps the scrub is not the root cause of your delays?
Could you be CPU performance bound? Memory bandwidth bound? Network bound? Limited by your drives?
To test the last one, run /usr/bin/iostat -x 10, you will need a very wide window. Look at %util (the last column on the right), if any drives show above 90% for more than one sample at a time (more than 20 seconds) then you are just hitting the limits of what your drives can do. %util is what percentage of time that drive is busy servicing a request.
If this is the case, the typical fix is to add vdevs. You only have 2 vdevs. You are also using RAIDz2 which is better for capacity than performance. If you can afford it, I would rebuild using 2-way mirrors. Going with more, smaller (cheaper) drives also gets you more vdevs for the same net capacity.
The largest I saw was about 3s scrub wait (I have no screenshot of it). But for now, everything seems to be fine.
Note the main server in now in local (NVMe), the disk is no longer in ZFS on the NAS, that’s likely the main reason of the “lags”.
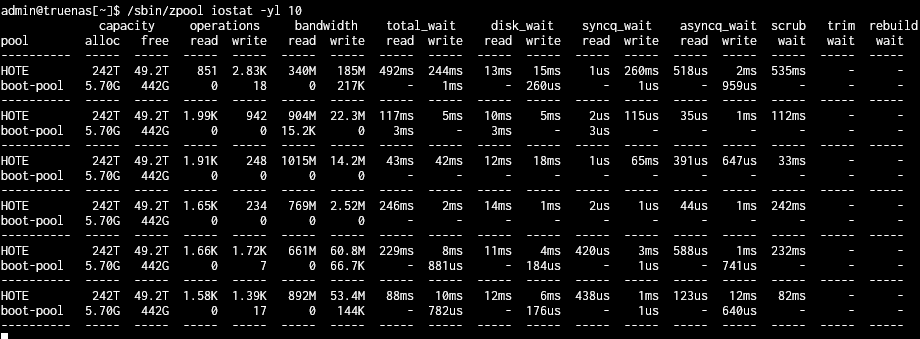
scrub at 96 % outpout of iostat :
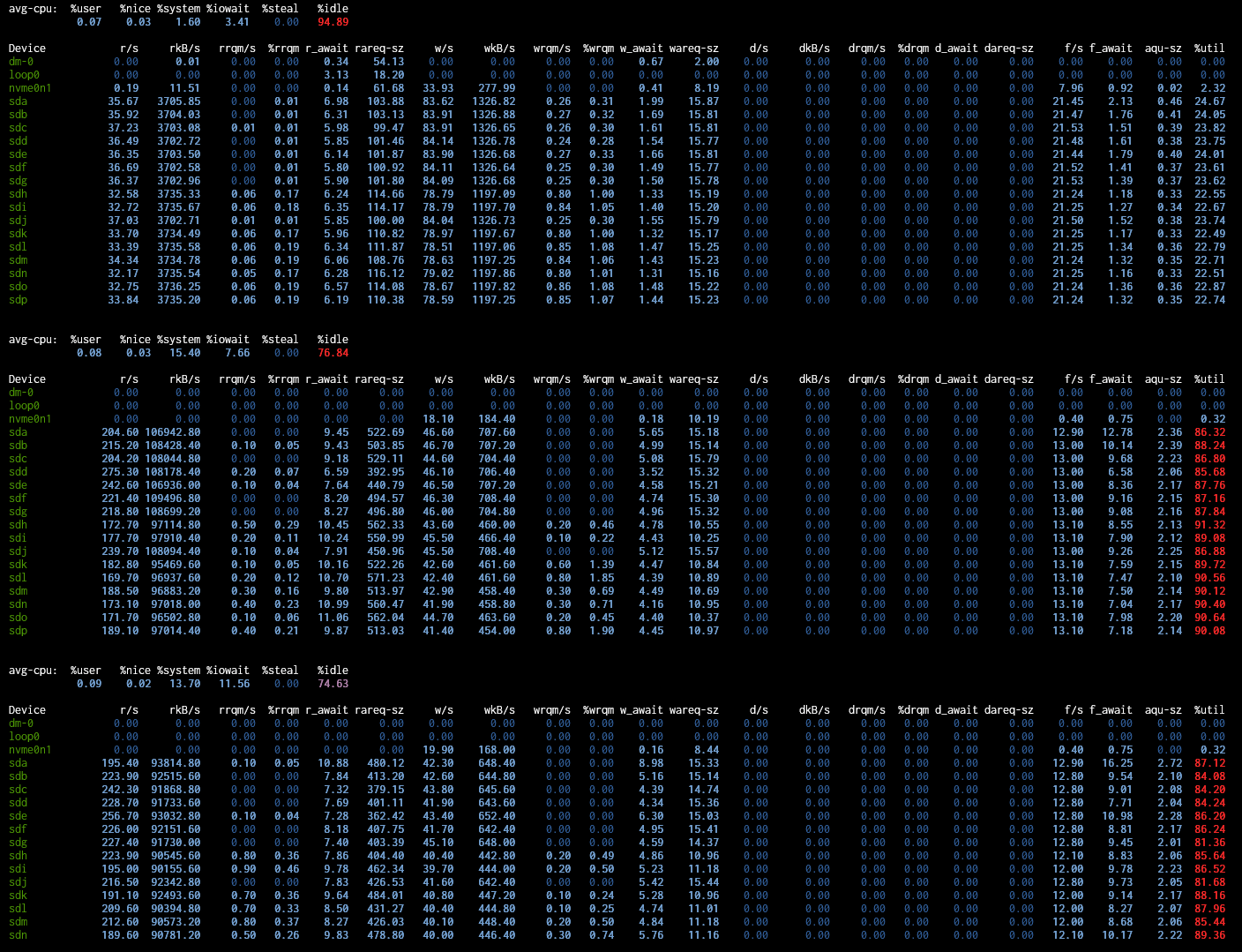
Those disk are very busy, although not completely saturated. I would expect some performance degradation, but nothing like 50% drop in bandwidth or 5x increase in latency.