The NAS is only here for storage, the PMS (Plex Media Server) are on 2 others servers (using the UHD 770 to transcode).
At the beginning the NAS was running on a 14900K, but since I decided not to run any apps on it, I switched to something less overkill, also not concerned with the hardware/microcode “issue”.
When I was saying “upgrade”, I was thinking of changing the MB, because I couldn’t find any 48 GB stick, to add more 32 GB sticks if required.
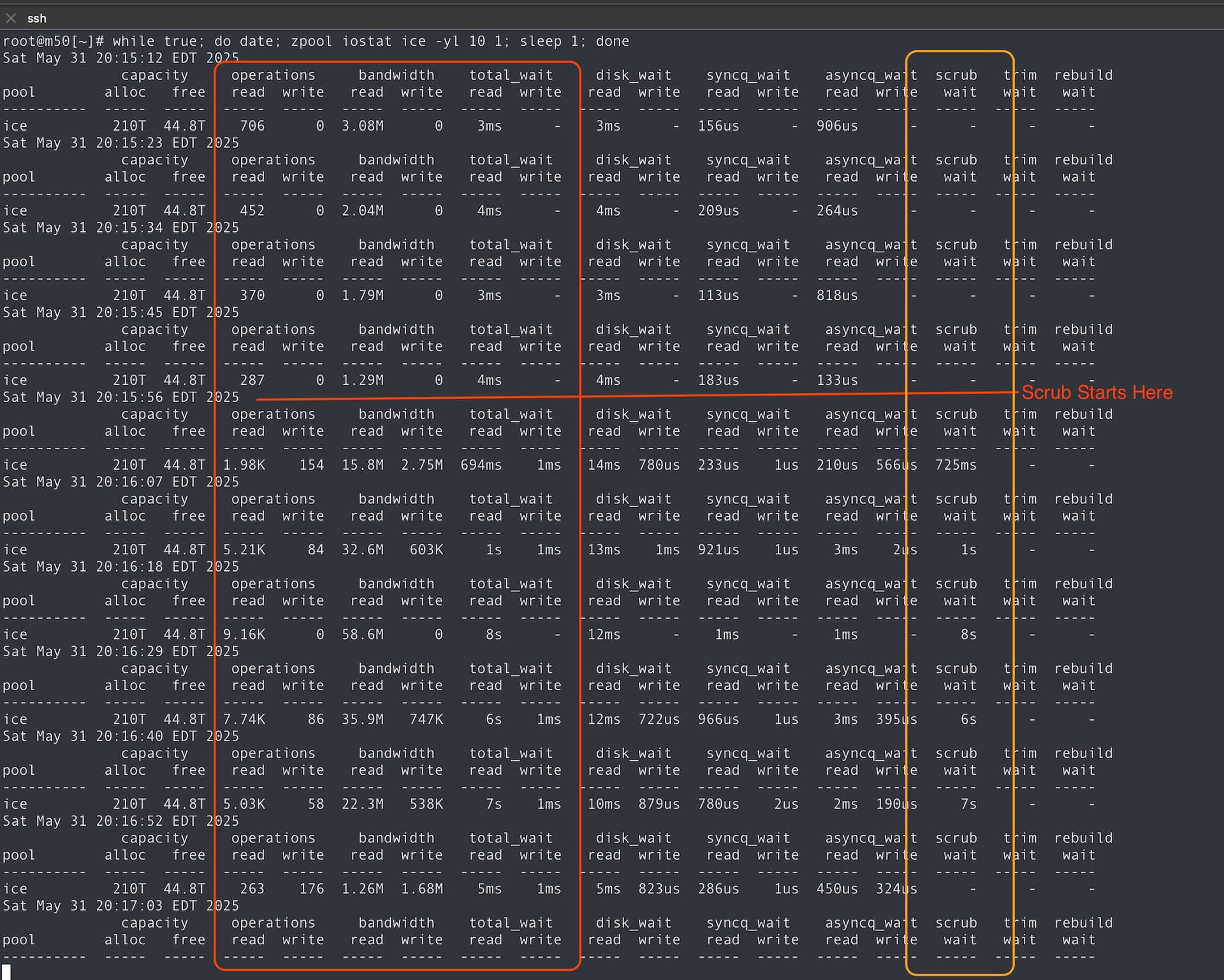
I cannot plan the scrub at a “good” timing, since it takes several days (between 2 and 4 days, I think).
Slow in what way? Well, it takes a lot of time to load pages or to be able to start a stream, once the stream is started, it’s likely fine. Also, everything is laggy, because for now, the VM drives are in the NAS, I plan to go on local SSD for better performance.
That’s the full setup :
Serveur 1
OS : Proxmox VE 8.2 (clusterisé)
Boîtier : NZXT H5 Flow
CPU : Intel Core i5-12600K
Ventirad : Thermalright Peerless Assasin 120 SE
GPU : Nvidia Quadro RTX 4000
Mémoire vive : Crucial Pro 64 Go (4x16 Go) DDR4 @ 3 200 MHz
Carte mère : Gigabyte B760M DS3H DDR4
Carte réseau : TP-Link TX401 - Ethernet 10 Gigabit
Stockage - SSD M2 : Western Digital Black SN850X 500 Go
Alimentation : Corsair CX650 - 80PLUS Bronze
Serveur 2
OS : Proxmox VE 8.3 (clusterisé)
Boîtier : Corsair 4000D Airflow
CPU : Intel Core i9-14900K
Mémoire vive : Corsair 64 Go (4x16 Go) DDR4 @ 3 200 MHz
Carte mère : Gigabyte B760M DS3H DDR4
Carte réseau : Chelsio TC520 - Ethernet 10 Gigabit
Stockage - SSD M2 : Crucial P3 2 To
Alimentation : Corsair CX550 - 80PLUS Bronze
Cooling : Be quiet! Silent Loop 2 280mm
Serveur 3
Mini PC : Insoluxia Intel N100 CPU, 16 Go de RAM, 512 Go de SSD sous Proxmox 8.3 (clusterisé)
NAS
OS : TrueNAS Scale
Boîtier : Fractral Design Define 7 XL
CPU : Intel Core i5-12600K
Carte mère : ASUS Pro WS W680-ACE IPMI
Carte réseau : Chelsio TC520 - Ethernet 10 Gigabit
Carte HBA : LSI 9302-8I
Mémoire vive : Kingston Server 128 Go (4x32 Go) DDR5 ECC @ 4 800 MHz
Stockage - SSD M2 : Samsung 970 EVO PLUS 500 Go
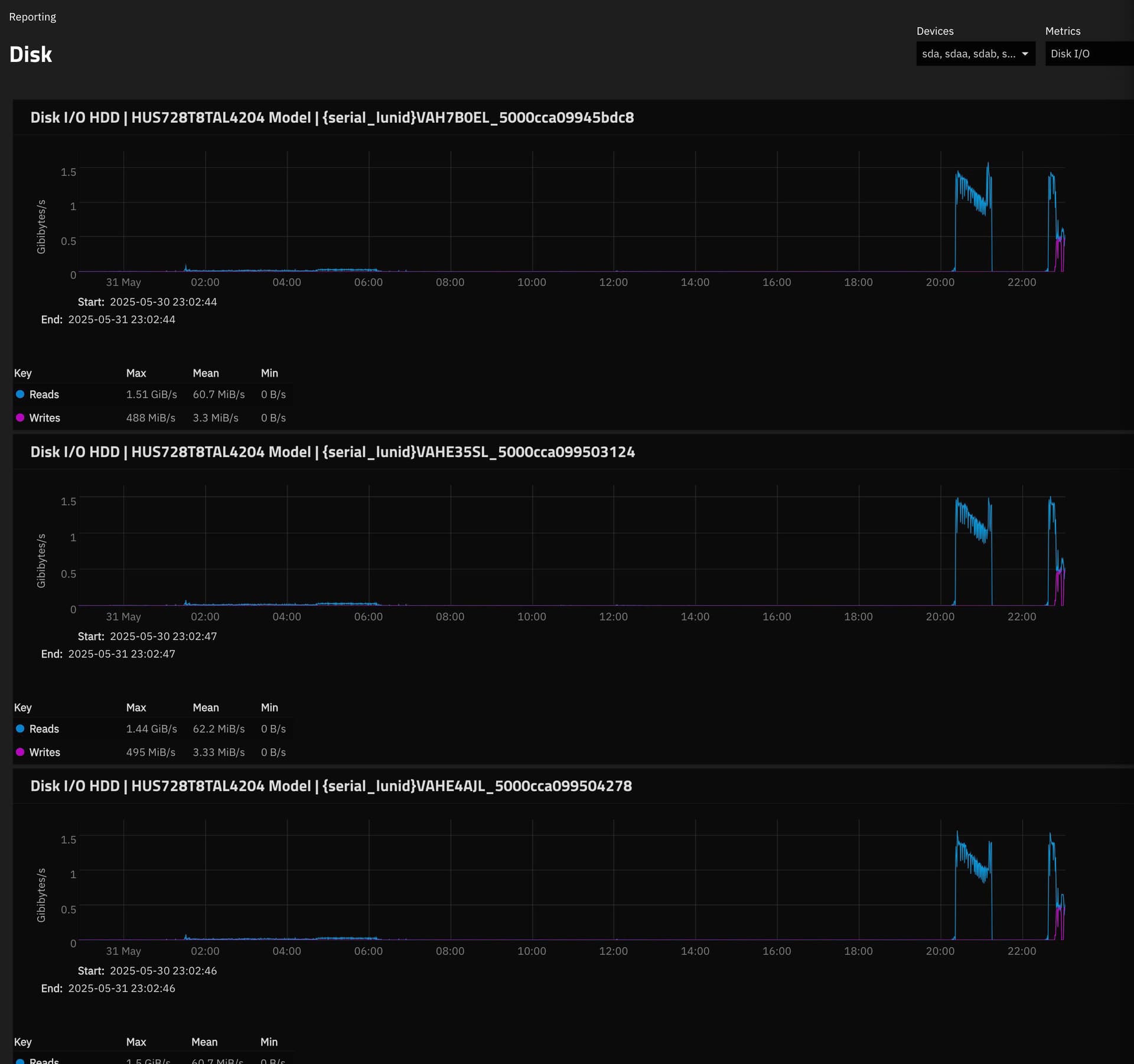
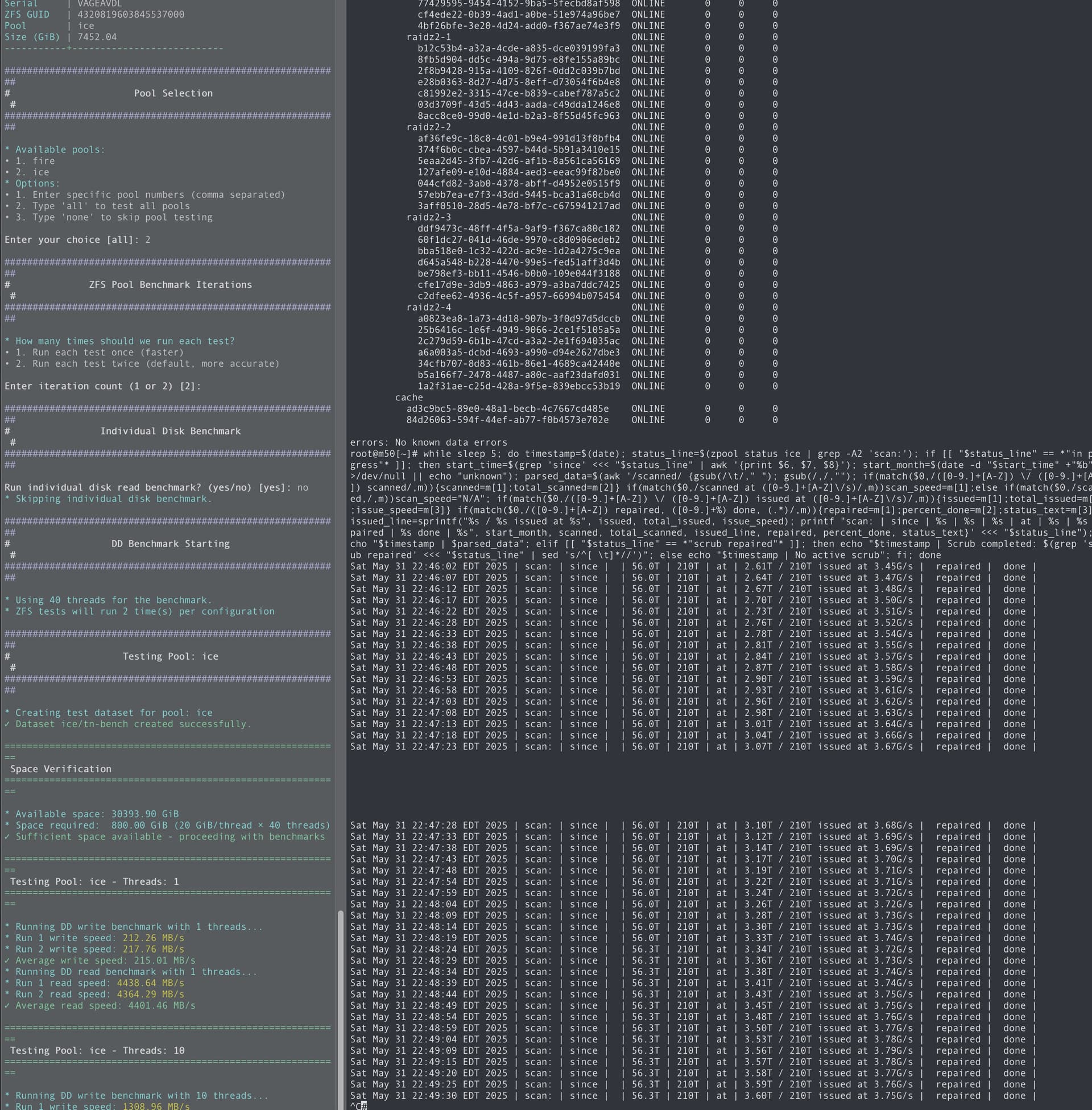
Stockage - HDD : 16 x Toshiba MG10 20 To en 2x RAIDZ2 pour un total de 210 To
Alimentation : Corsair 850W - 80PLUS Gold
Cooling : Be quiet! Silent Loop 2 280mm (avec 2x SILENT WINGS PRO 4 140mm)
Switch : TP-Link TL-SX105 - 5 ports Ethernet 10G
Onduleurs : 3x Eaton Ellipse PRO 1600 FR
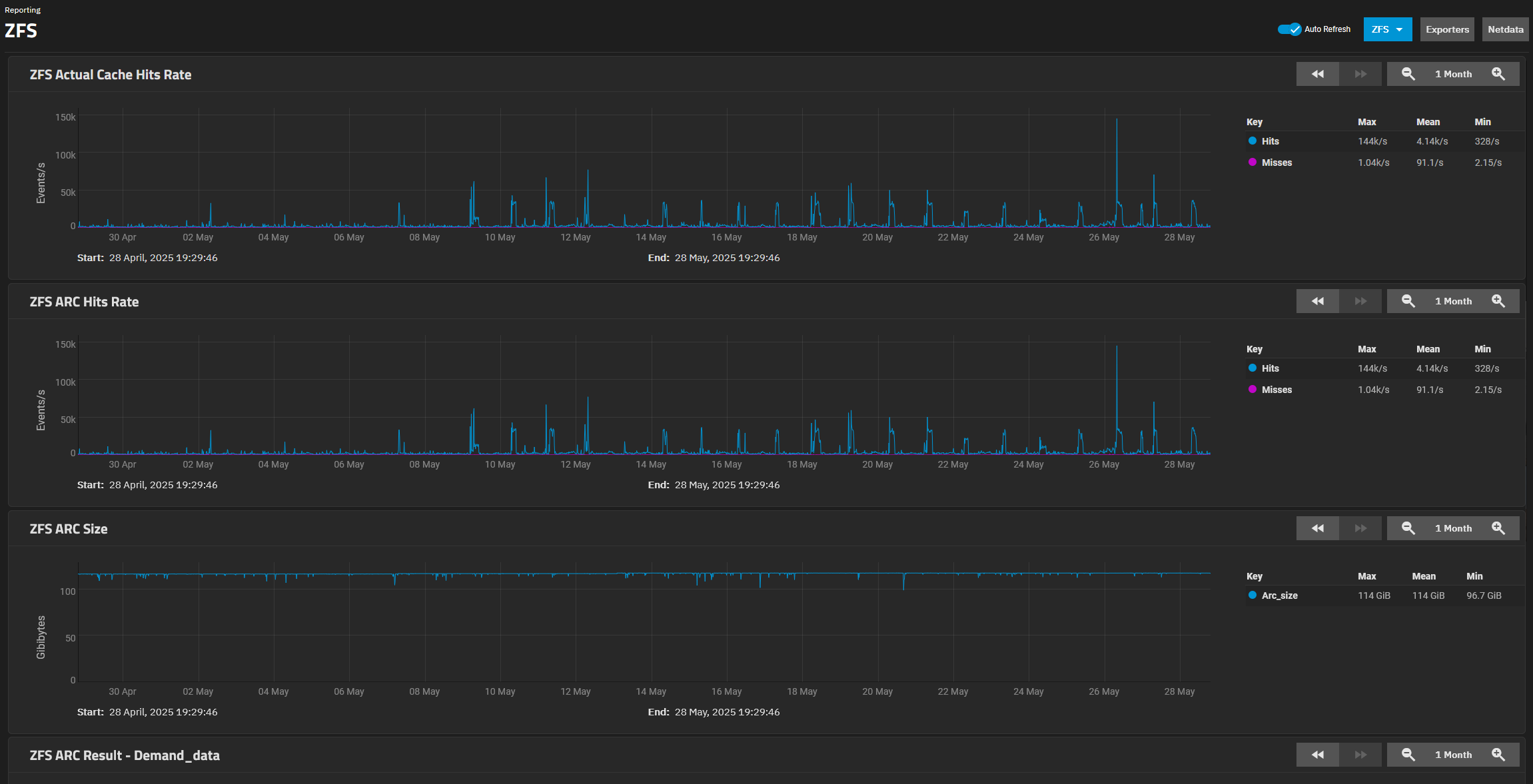
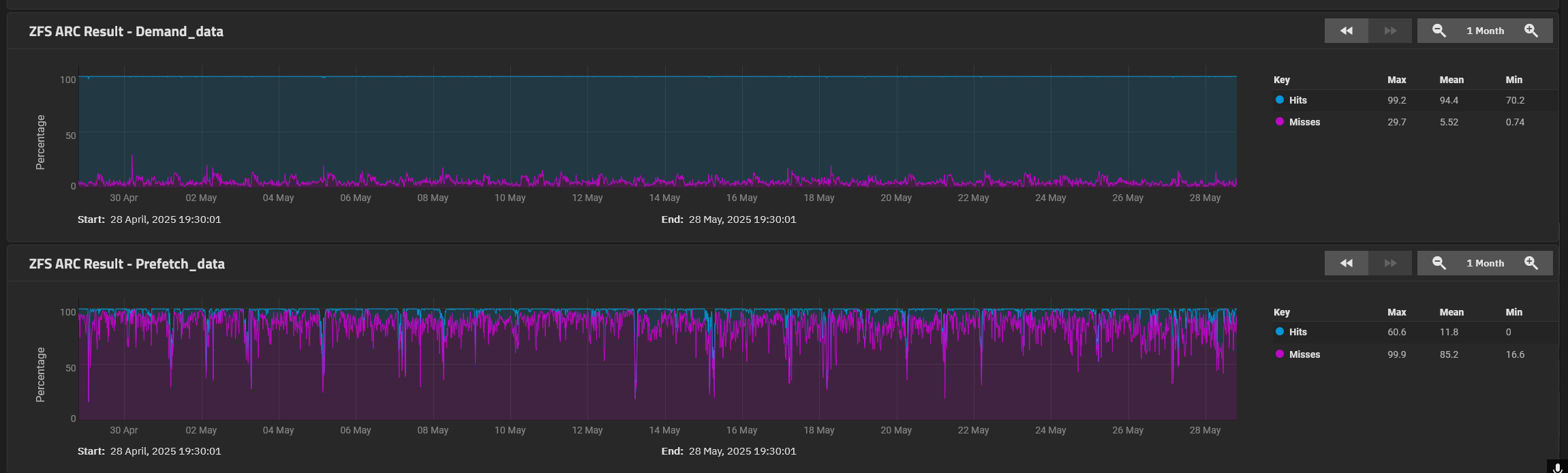
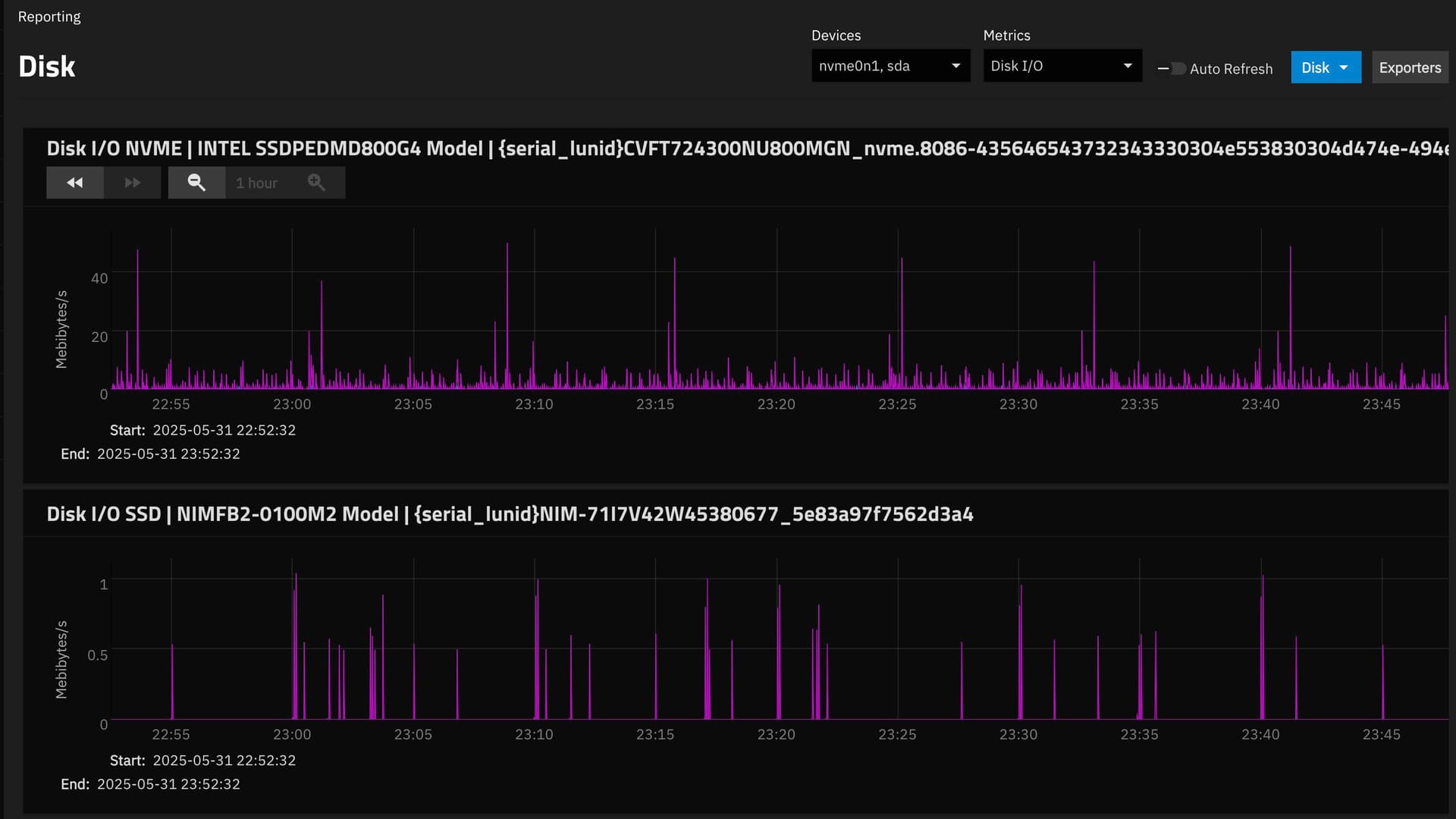
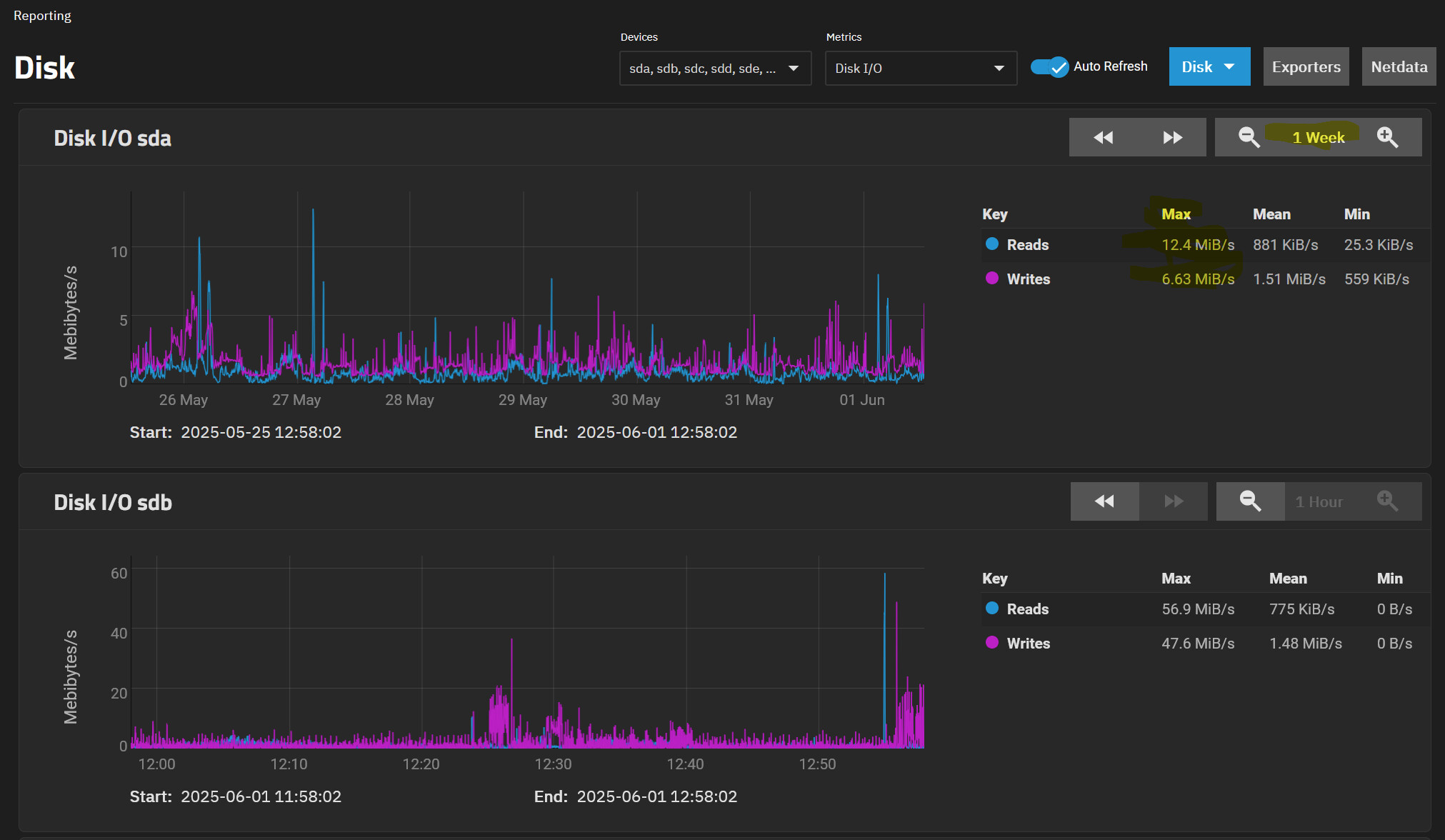
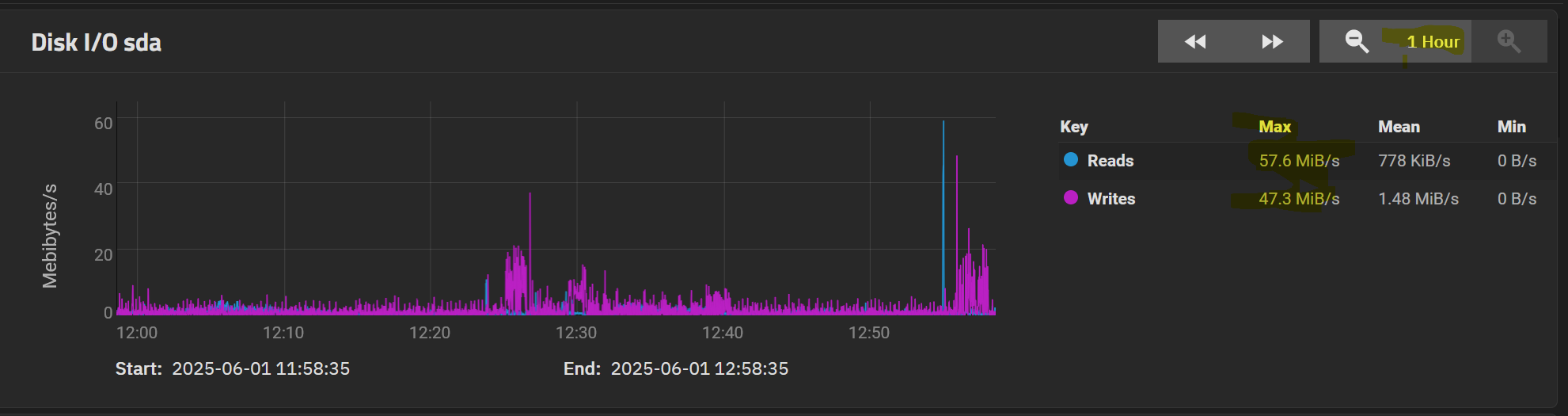
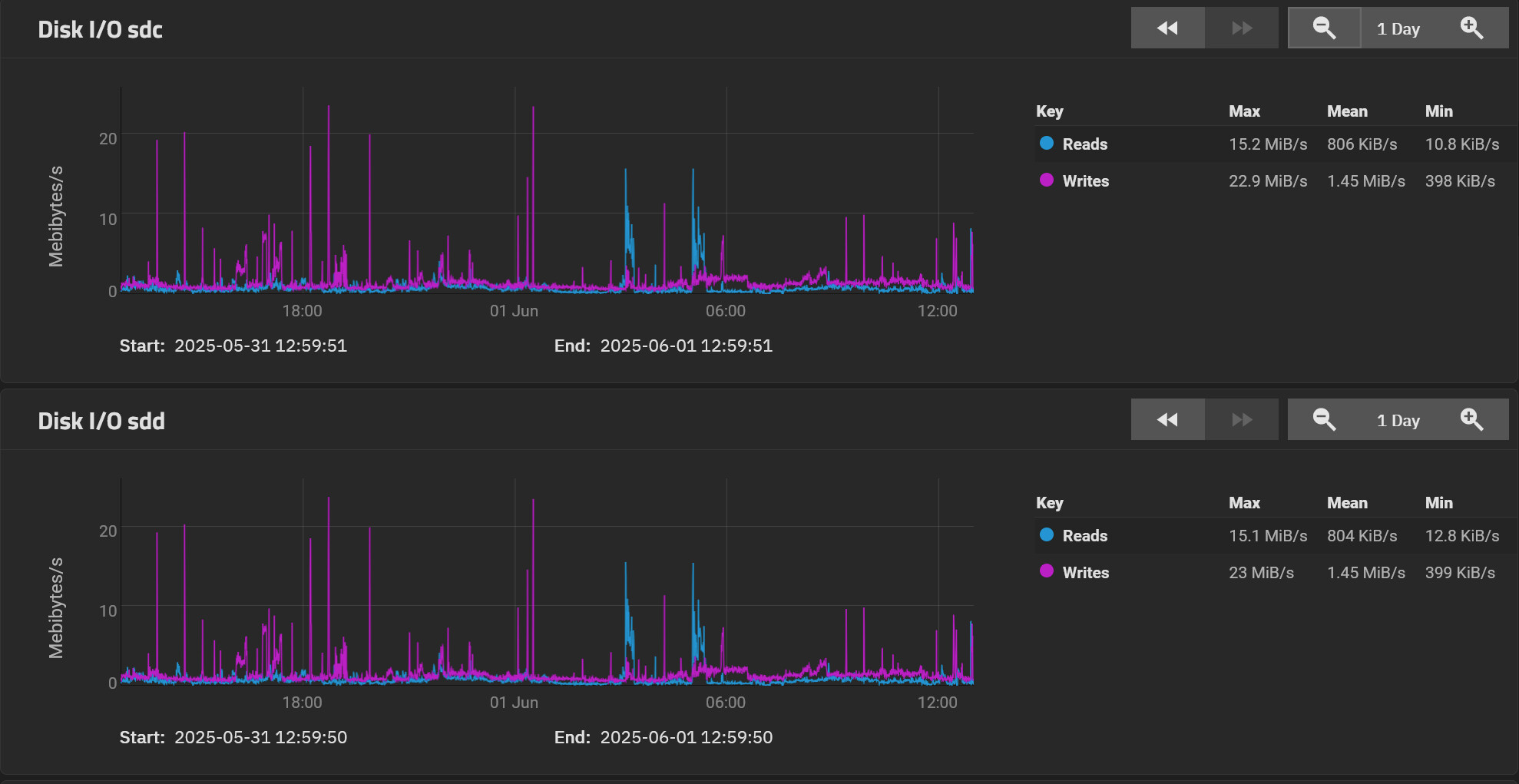
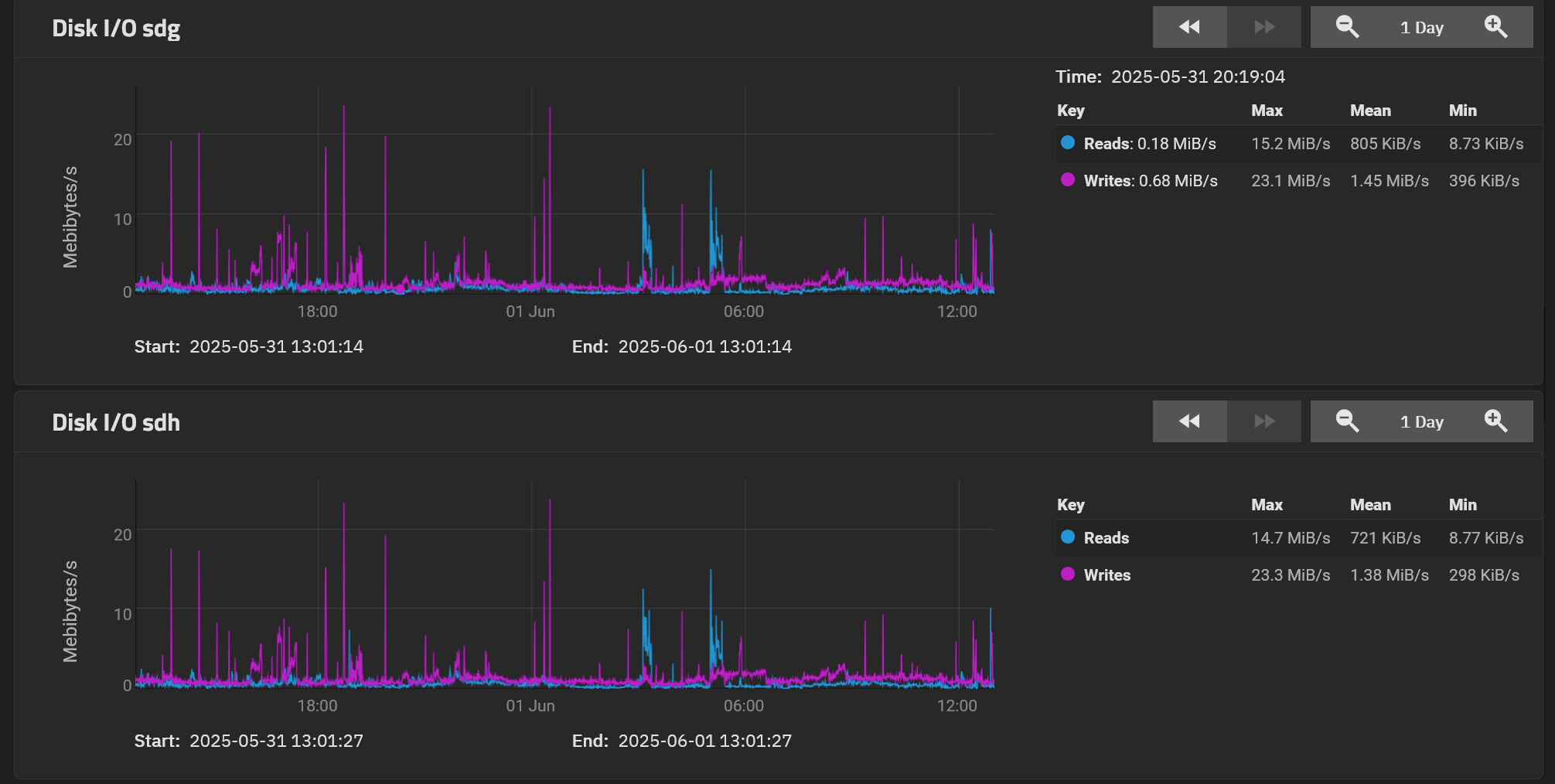
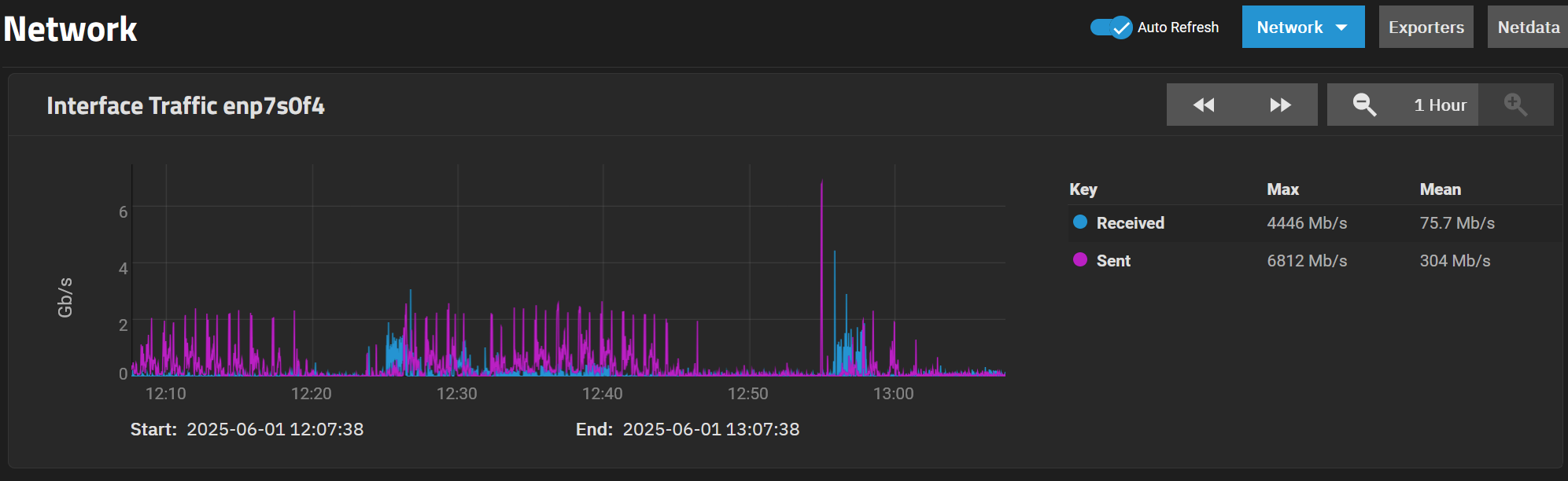
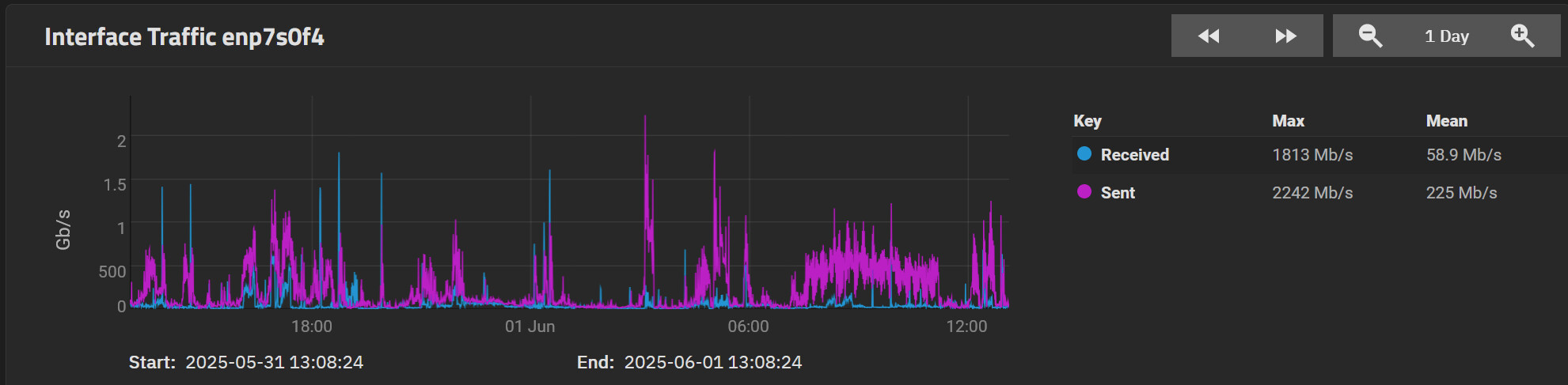
The ZFS report for the last month :