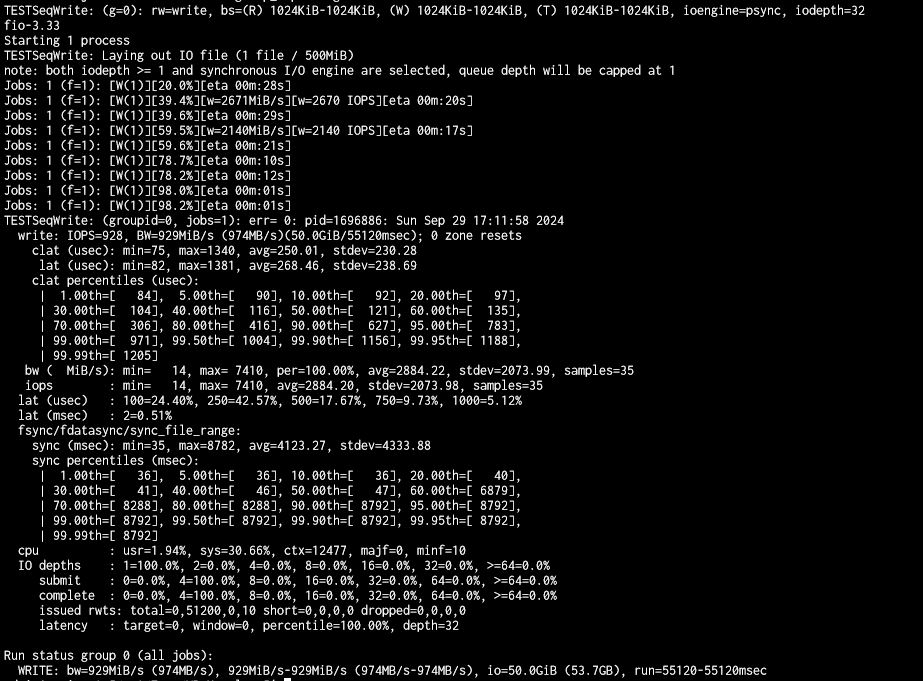
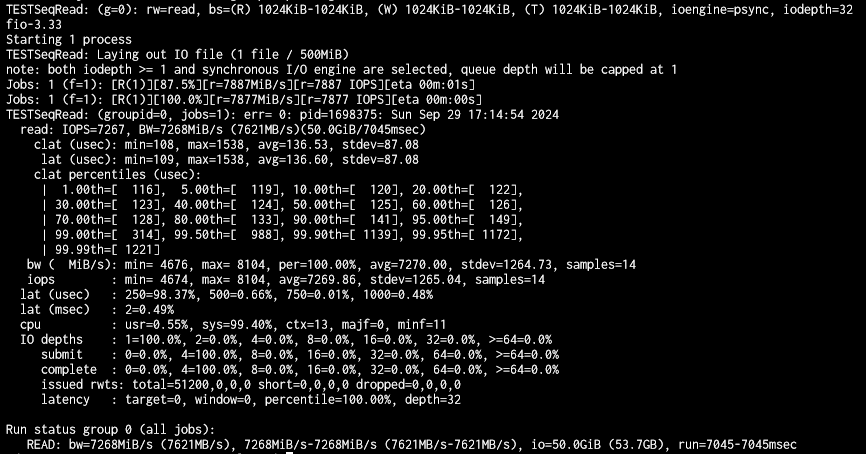
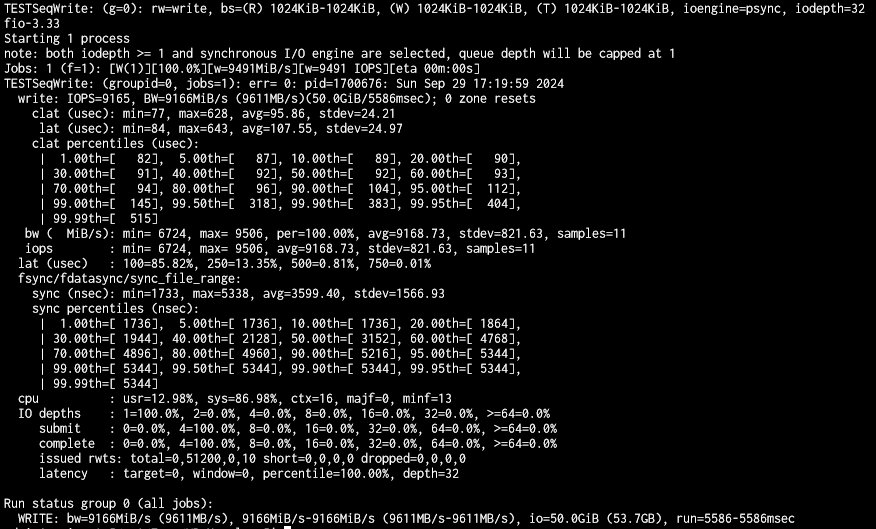
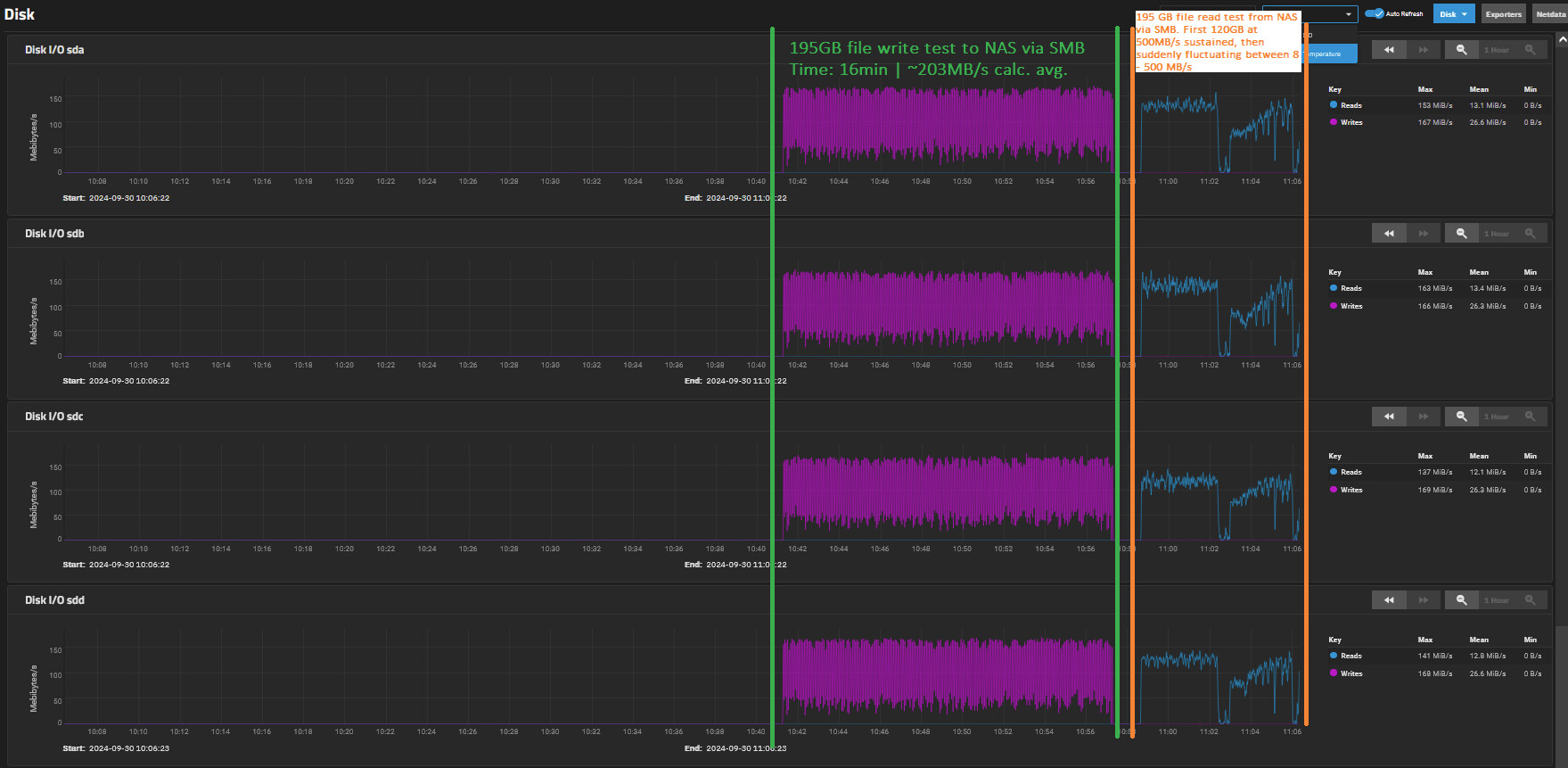
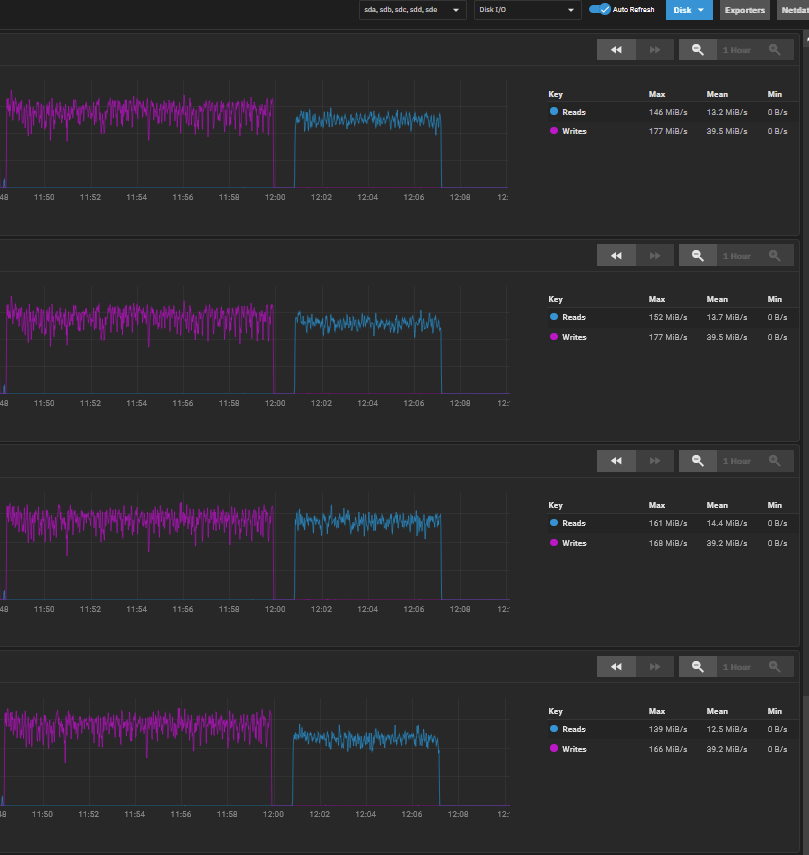
To better quantify the performance, I took the leap and spent the whole day deleting my pool, setting up different STRIPE/MIRROR/RAID/RAIDZ configurations and testing read/write performance via SMB.
For the tests I used a large 195 GB file which should mostly contain random contents (so is likely mostly incompressible). I copied this file to/from the NAS to the same Windows10 VM via SMB as described earlier and taking notes of the duration it takes to copy with an empty, new pool. From that I calculated average read/write speeds.
The results are quite interesting, see below:
Read/Write speed tests via SMB to TrueNAS SCALE bare metal server for different pool/disk configurations.
Note: the 195 GB file should have near random contents, so is likely mostly uncompressible.
WRITE speed tests TO NAS using 195 GB file (from Windows 10 VM on NVMe via SMB, via 10 Gbit/s network, standard SMB config, pool encrypted)
Config Time Calc. avg. speed Comments
- 1 disk STRIPE ~15 min, 48 sec ~206 MB/s NAS pool used space 0%. Disk used: sda
- 2 disks STRIPE 7 min, 50 sec ~415 MB/s NAS pool used space 0%. Disks used: sda, sdb
- 4 disks STRIPE 7 min, 42 sec ~422 MB/s NAS pool used space 0%. Disks used: sda, sdb, sdc, sdd
- 2 disks MIRROR 15 min, 21 sec ~212 MB/s NAS pool used space 0%. Disks used: sda, sdb
- 4 disks MIRROR ~22 min, 47 sec ~143 MB/s NAS pool used space 0%. Disks used: sda, sdb, sdc, sdd
- 4 disks RAIDZ2 ~18 min, 2 sec ~180 MB/s NAS pool used space 0%. Disks used: sda, sdb, sdc, sdd
- 4 disks RAID10 (striped mirrors) 17 min, 20 sec ~187 MB/s NAS pool used space 44%. Disk pairs used: Mirror1: sdb, sdd | Mirror2: sda, sdc. This is the config I had yesterday still.
- 4 disks RAID10 (striped mirrors) ~11 min, 30 sec ~282 MB/s NAS pool used space 0%. Disk pairs used: Mirror1: sda, sdb | Mirror2: sdc, sdd. This is same layout but on newly created, empty pool today, and disks ordered differently in the pools.
READ speed tests FROM NAS using 195 GB file (to Windows 10 VM on NVMe via SMB, via 10 Gbit/s network, standard SMB config, pool encrypted):
Config Time Calc. avg. speed Comments
- 1 disk STRIPE ~13 min, 21 sec ~243 MB/s NAS pool used space 0%. Disk used: sda
- 2 disks STRIPE 7 min, 3 sec ~461 MB/s NAS pool used space 0%. Disks used: sda, sdb
- 4 disks STRIPE 5 min, 7 sec ~635 MB/s NAS pool used space 0%. Disks used: sda, sdb, sdc, sdd
- 2 disks MIRROR 11 min, 15 sec ~289 MB/s NAS pool used space 0%. Disks used: sda, sdb
- 4 disks MIRROR 6 min, 22 sec ~510 MB/s NAS pool used space 0%. Disks used: sda, sdb, sdc, sdd
- 4 disks RAIDZ2 7 min, 24 sec ~439 MB/s NAS pool used space 0%. Disks used: sda, sdb, sdc, sdd
- 4 disks RAID10 (striped mirrors) 8 min, 28 sec ~384 MB/s NAS pool used space 45%. Disk pairs used: Mirror1: sdb, sdd | Mirror2: sda, sdc. This is the config I had yesterday still.
- 4 disks RAID10 (striped mirrors) 6 min, 26 sec ~505 MB/s NAS pool used space 0%. Disk pairs used: Mirror1: sda, sdb | Mirror2: sdc, sdd. This is same layout but on newly created, empty pool today, and disks ordered differently in the pools.
Does this look as expected to you?
A few things that seem noteworthy to me (no expert, though):
- With 4 disk STRIPE, I was able to get a sustained ~635 MB/s read and ~422 MB/s write speed. That should mean that my network can handle at least up to that speed fine. I don’t expect the network to be the issue for any lower speeds therefore. (It might possibly be the bottleneck above these high speeds, but that’s not the main concern at the moment)
- When I did the first test this morning (with the configuration I had when I started this thread) the RAID10 performance was 187 MB/s write and 384 MB/s read. After I deleted the pool and created a new, empty pool in RAID10 again it has gone up significantly to 282 MB/s write and 505 MB/s read. I am not completely sure why this is, the only difference seems to be that before the pool was 44% full, now it was 0% full. And that I now had the four drives in a different combination in each mirror pool.
- My RAID10 reaches only about 45% / 68% of the write speed that the 2 disk STRIPE reaches. 2 disks STRIPE has great write (415 MB/s) and read (461 MB/s) speeds. RAID10 speeds are (187/282 MB/s) write and (384/505 MB/s) read. I would expect the RAID10 write speed to be roughly similar to the 2 disk STRIPE write speed, or not? (and read speed, theoretically, even double that)
- 4 disk STRIPE write speed is the same as on 2 disk STRIPE. That seems unexpected to me. Normally 4 disk STRIPE write speed should approach 200% of the 2 disk STRIPE, right? (The read speed with 4 disk STRIPE is 137% of the 2 disk STRIPE. That’s better, but shouldn’t that also normally approach more towards 200%?)
- Mirroring more disks seems to decrease write speed. I was a bit surprised that it went as low as 143 MB/s sustained write speed when mirroring 4 disks.
In the end what matters for me is RAID10 performance. Curious what you all think! If this looks reasonable and my expectation on speeds is off let me know too