“Twelves-Day” (12/12) to be more precise is the targeted release date. ![]()
Just one doubt i have: are we talking about truenas scale version or zpool zfs version?
'cause we are on SCALE 24.10.2 atm with the zpool created in CORE and not updated.
Thanks
It’s a ZFS on Linux fix related to how exportfs interacts with ZFS. Zpool version is unrelated.
I think you mean 24.10.0.2 which is an entirely different thing to 24.10.2 (which is still a couple of months away at a guess).
1 Like
24.10.1 will be released toward the end of this week IIRC.
Expected to release this Thursday 12/12.
I’ve upgraded to 24.10.1. Still not solved this issue. My ProxMox Backup garbage collector job takes 25x more time to complete than with a TrueNas Core system with NFS. That’s now days instead of few hours.
Same here unfortunately.
I’m doing some tests with fio to compare.
I see, at the moment, only two possible solutions (without touching my layout/topology):
- keep samba and forget nfs
- try to downgrade from 24.10 to 24.04 to check if it has same issues
I will get back with fio test results though
Since it’s CPU bound for this workload, can someone get a profile / flamegraph of it? These sorts of things can usually be fixed / sorted out. If you need instructions feel free to PM me, but do note I’m not a forums mod and this is holidays time (response time may be slow).
I’m having a chat with @awalkerix (thanks again for help) to provide needed info
Anyway, for further info, i have exact same results on fio test both on 24.10.0.2 and 24.10.1: good write iops on samba and really bad on nfs.
Here are a few screenshots:
NFS (tried both 3 and 4.2, same results):
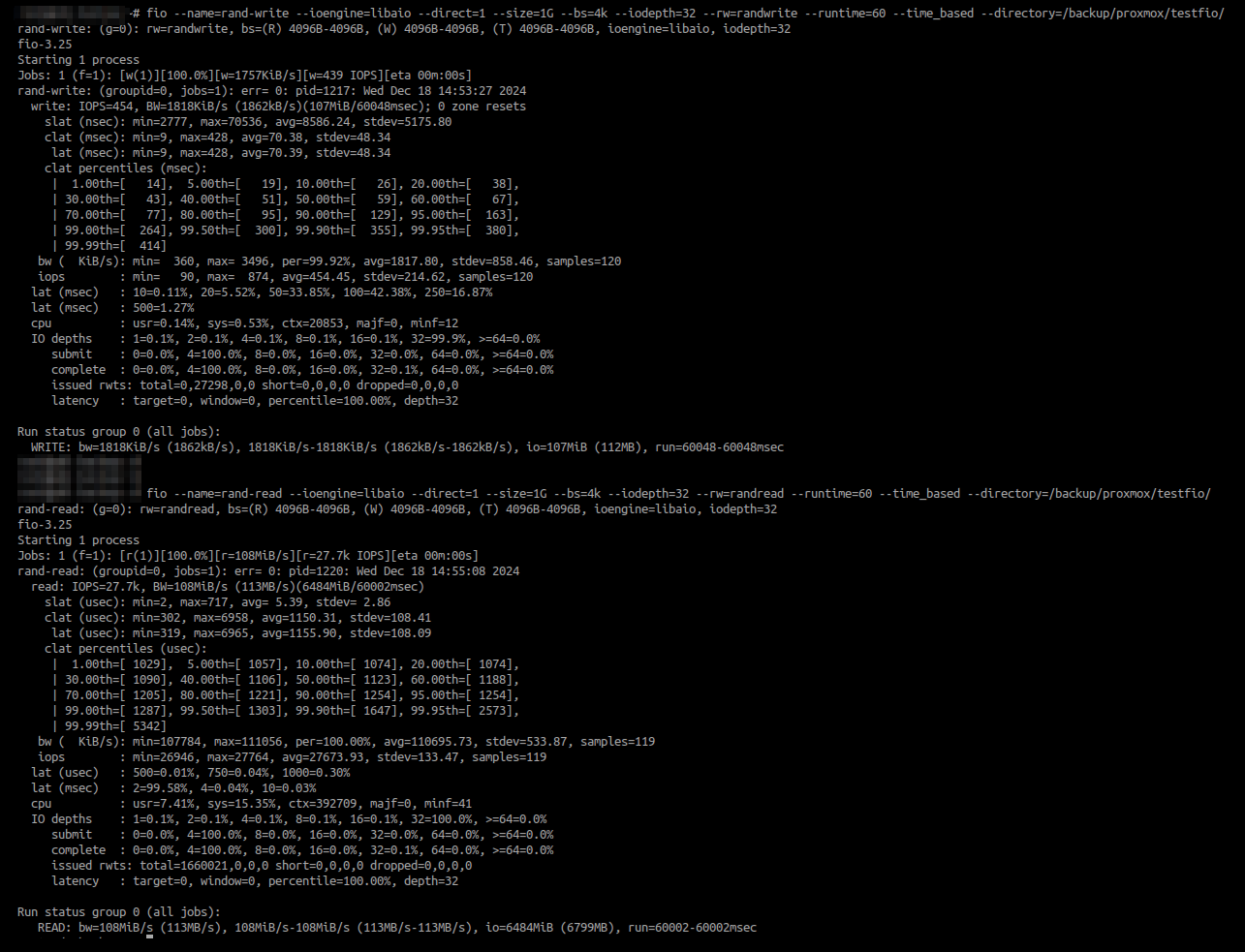
SMB:
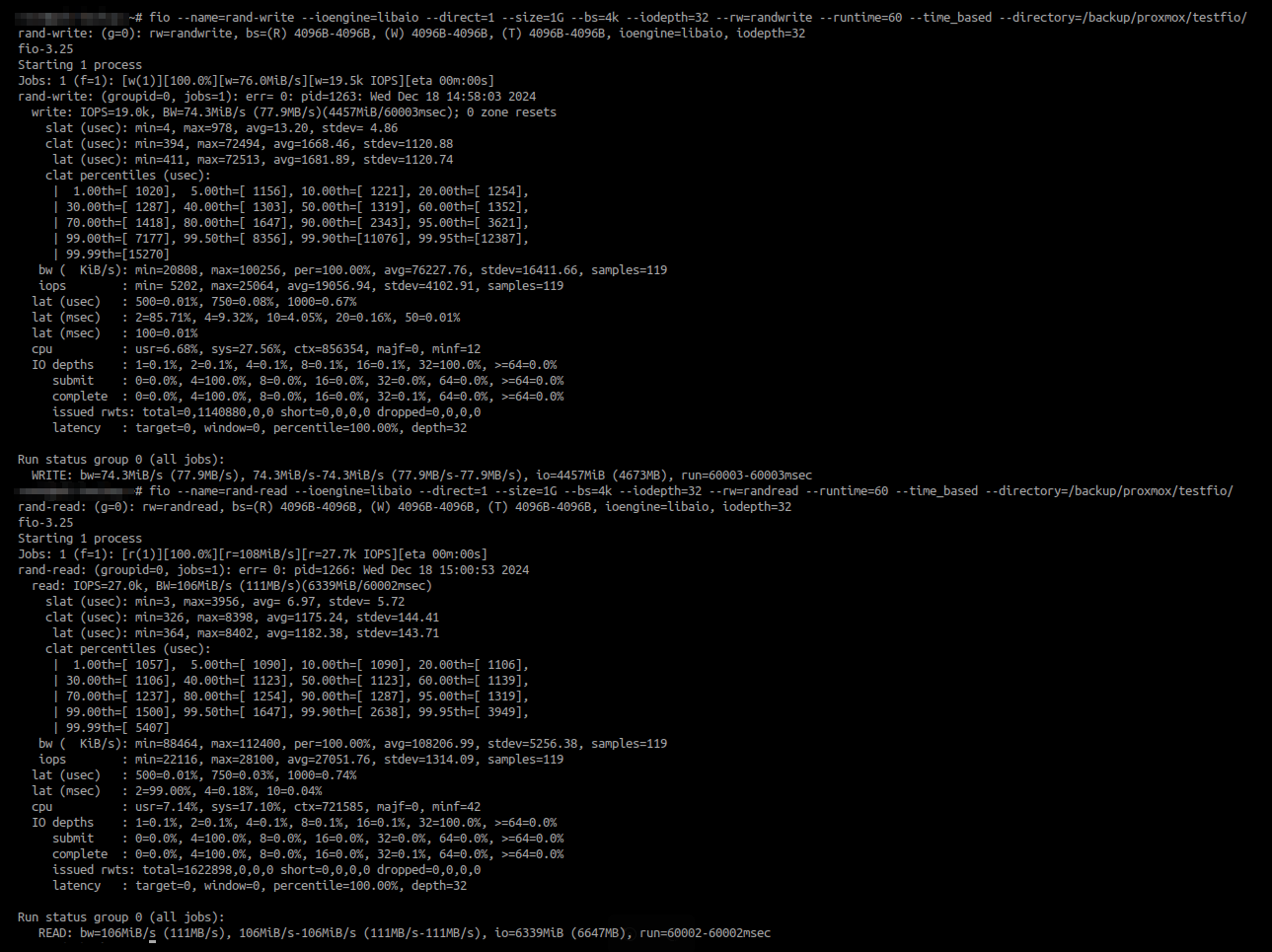
The most obvious potential cause for a difference between NFS and SMB is synchronous writes vs. asynchronous writes - so my advice would be to double check this and rule it out as a possible cause.
I can confirm the NFS is in async setting, both in our scale and core environments but i keep having really poor performances.
I see same outcome. SMB is just fine. NFS is way too slow compared to TrueNAS Core. It is also not related to ProxMox (Backup). So what’s the difference between NFS implementation of Core and Scale?
I can’t switch to SMB for my NFS storages. I’ve some other systems which can’t use SMB.
I have to agree. Switching from NFS to SMB, due to poor performance, is not a “solution”.
That does seem to be a problem. So lets do some troubleshooting here, if anybody is willing to give us a hand.
We do test NFS internally, and thus far we’re not detecting any massive performance slowdown in NFS compared to CORE. (If anything, we’re seeing some major improvements on our hardware).
But for sake of testing, lets do a few things if you can.
First, can you update to a nightly image of Fangtooth? (You can roll back once we are done testing)
We’ve updated to kernel 6.12, which has a lot of new NFS server changes, and it will be good to know if that impacts your performance one-way or another.
If it doesn’t, then that likely means we have some config knobs or tuning defaults that perhaps are specific to your setup that need investigation. SMB being snappy on the same setup sort of rules out ZFS as being “slow”, but I’m sure there are plenty of NFS specific tuning we can look at next. But ruling out changes in upstream kernel “fixing” this is a first important step.
No problem, i can test this.
I’m downloading the image, will let you know as soon as it’s installed and will launch a pbs garbage collection to see what happens.
Thanks
1 Like
Ok, nothing new, garbage is still super slow.
For info, with latest 25 nightly i have this in htop during garbage collect:

While garbage isn’t even at 1% after 15 mins:
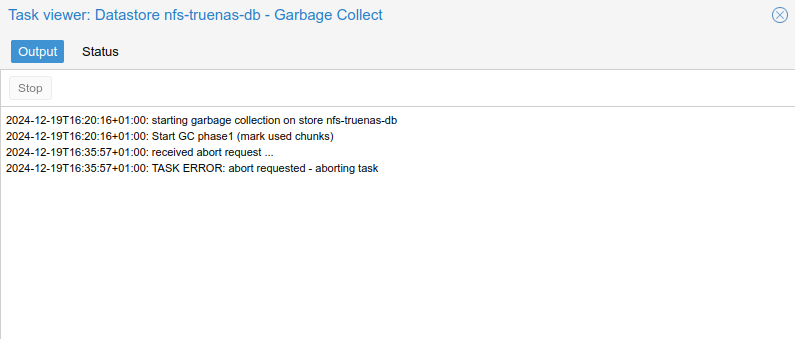
While on 24.10, garbage is like this:
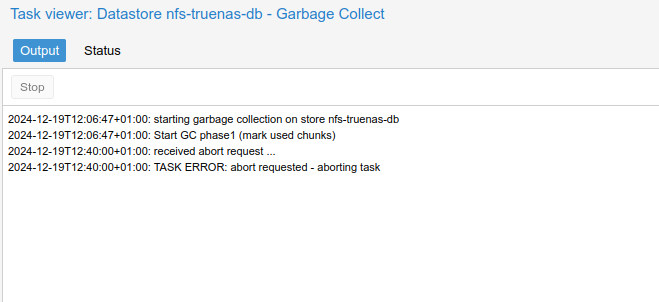
While, on core, garbage is like this:
As previusly reported, hw setup is exactly the same, just truenas os/version differs.
Last info: no other jobs except garbage collection is running on pbs or truenas
Ok, great to rule that out, one big variable eliminated. ![]()
Next would be having you, or somebody who can reproduce, work with @awalkerix to get flame graphs so we can identify where the bottleneck is and find the magic set of tunings or fixes to eliminate.
Ok, i’m already “pestering” him via DM ![]()
Will update with the flame graph, thanks
1 Like
While we wait for @awalkerix, i tried to follow this guide: CPU Flame Graphs
Especially this part:

I did 3 tests i did on truenas scale:
- First one without any work going on
- Second one with pbs garbage collection over cifs
- Third one with pbs garbage collection over nfs
You can find them here: flamegraphs.zip - Google Drive
Are they good/enought?
Thanks