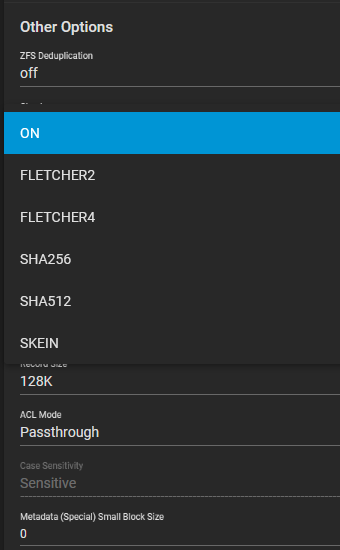
Updated to 13.3 from the BETA-2, and was interested in running the newly introduced BLAKE3 instead of the default (I assume SHA256) checksum algorithm in my pools given the higher performance.
In the WebUI dataset’s options however there is no mention of it: I assume I just need to manually set the feature via zfs set checksum=blake3, does anywone want to chime in?
Fletcher4 doesn’t meet the requirements for deduplication. (The extremely rare chance that a non-dup block is mistaken as a duplicate is still too great of a risk when using deduplication.)
SHA256 is beyond this (extremely-almost-impossible) risk of collision. So, too, is BLAKE3. But not Fletcher4.
Therefor, you’re already benefiting from the performance of Fletcher4, without the stricter requirements that a dedup dataset mandates. (Fletcher4 is still faster than BLAKE3.)
TL;DR
The benefit of BLAKE3 being introduced in OpenZFS is that those who use (or plan to use) deduplication can choose a faster algorithm which meets the cryptographic requirements of dedup datasets.
End-to-end checksums are a key feature of ZFS and an important differentiator for ZFS over other RAID implementations and filesystems. Advantages of end-to-end checksums include:
detects data corruption upon reading from media
blocks that are detected as corrupt are automatically repaired if possible, by using the RAID protection in suitably configured pools, or redundant copies (see the zfs copies property)
periodic scrubs can check data to detect and repair latent media degradation (bit rot) and corruption from other sources
checksums on ZFS replication streams, zfs send and zfs receive, ensure the data received is not corrupted by intervening storage or transport mechanisms
It could be argued that there would be a potential benefit to data integrity in a number of edge cases. Using BLAKE3 (or SHA256) could help increase the accuracy of scrubs and replications, as well as higher accuracy checksum error detection on reads, at the cost of reduced performance.
The likelihood of that is so rare that I would consider it “basically impossible”.
Unlike with a dedup dataset, you’re not trying to avoid a collision between multiple non-identical blocks that unfortunately have the same checksum. (This would result in outright data loss / file corruption.)
For this hypothetical issue of “undetected data corruption” with Fletcher + non-dedup:
You save a file (which is stored as blocks on ZFS)
One of these blocks becomes corrupted
Upon reading the file or running a scrub, the Fletcher4 function runs a checksum for this corrupted block, which (miraculously) matches the hash already saved in the pointer
A scrub or read will falsely assume “everything is fine, no corruption”
The chance of that spontaneously happening is 0.00000000000…00000…00000.1%[1]
Almost impossible.
With dedup, things are different. You want dedup to skip writes (and storage) of blocks that “already exist”. So you want hashes to be generated with very high cryptographic strength to avoid a “collision” of two different blocks that result with the same hash. This becomes more and more relevant the larger the pool/data is, as there are more “blocks in play”.
Even though this would also be very, very rare with something like Flecther4, it’s within the realm of probability that someone using deduplication with massive pools and tons of data might get unlucky with such a collision. (Of course, the risk becomes greater when you extend it out over all the dedup use-cases around the world. Because it then becomes more likely that some unlucky person out there will be afflicted.) That’s where SHA256 comes in (default for dedup), and now BLAKE3 (same safeguard, better performance).
Purely to be pedantic, and a pain in the butt:
In a world with QAT SHA256 acceleration, it may as well be “free”. But again, only matters in edge cases and for the .0001% of users who have installed a QAT supporting card or CPU. ZFS Hardware Acceleration with QAT - OpenZFS