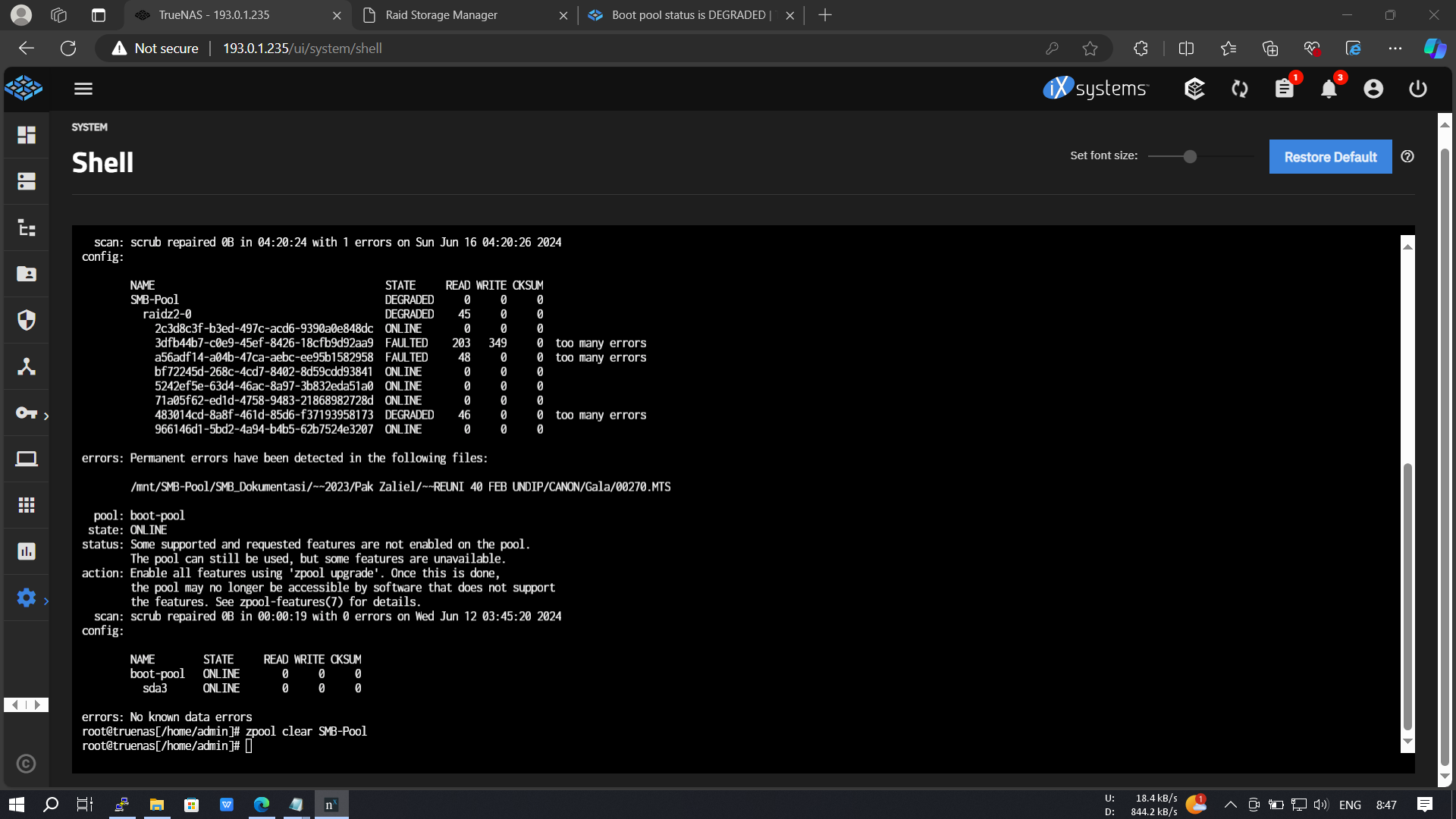
I have a server with 6TBx8 with raid-z2 and using areca controller with JBOD mode. I have a problem with 2 disks faulted, 1 disk degraded. Help me solve this problem and can the data on the server still be safe?

That does not sound promising. I don’t know the specific controller but it looks like a raid card. You would be better off with an appropriate HBA in it mode I think.
Your boot pool is not degraded, it’s your data pool. You can do long smart tests and post the results here, to see if the drives are actually dead or if it hints to another issue. From the errors alone I would lean towards the drives are actually failing.
It may be the actual drives or it is the controller. Hard to tell from the information given. Add your complete hardware please.
How old are the drives?
With three drives faulted / degraded your data is at risk. You would need a working replacement drive for the faulted ones immediately.
Do you have backups? If not, backing up essential data is your first step right now.
The file, in which permanent errors have been detected is gone. You would need to restore that one from backup.
Is there a possibility to attach all drives directly to the main board?
Server installed since 2018.
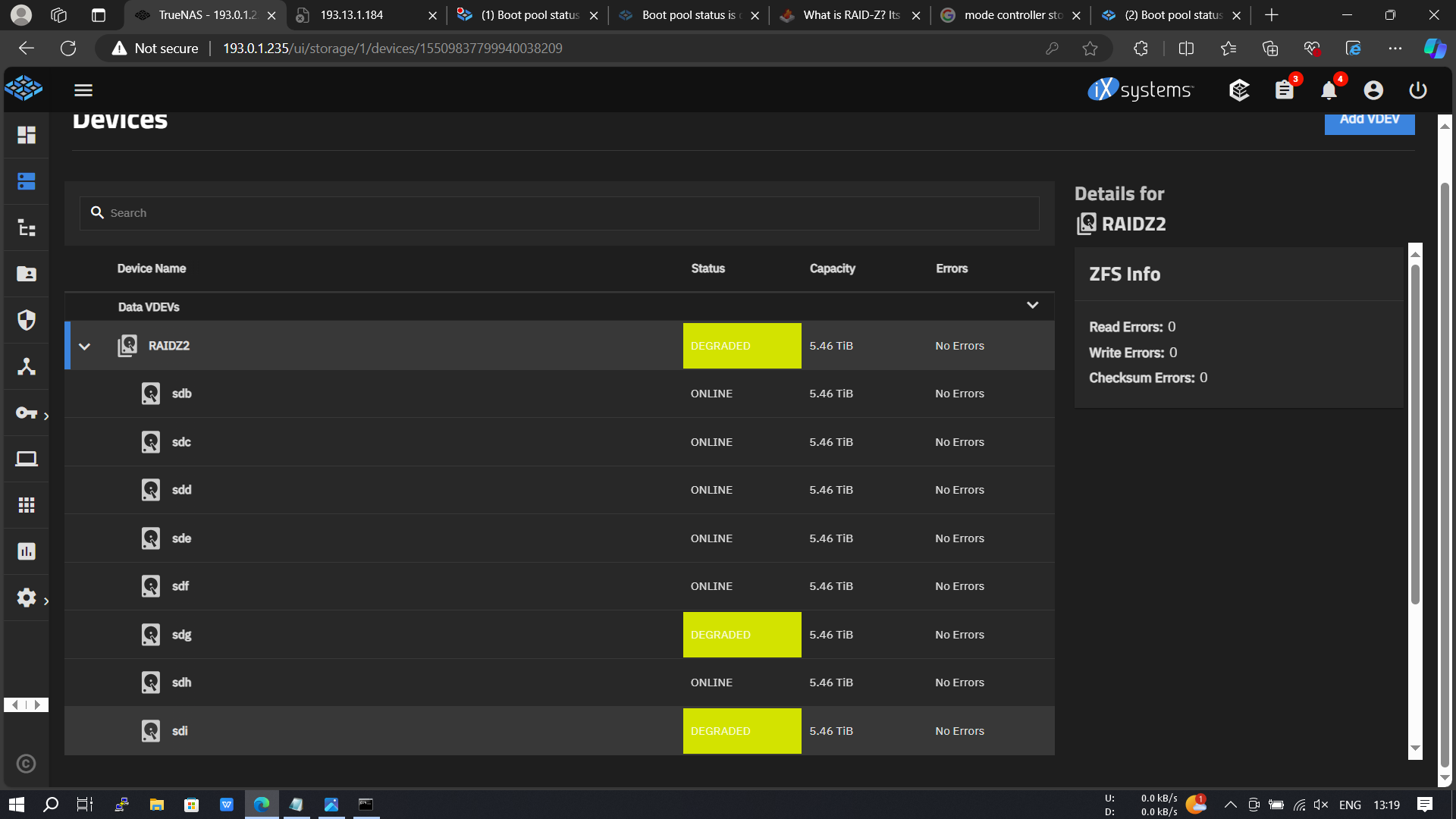
I turned off the server, then I waited a while and turned it back on and there were 2 degraded disks, the sdi disk had lots of errors
Should I replace the HBA card to run truenas?
I would think so, yes:
It may be that getting a proper HBA may resolve (some of) your issues however I doubt (without any further information) that his is the sole source of your errors). Considering the drives are 6 years old, I would think they are dying. Start looking into replacement drives.
In any case you should get on top of your backups. Do you have the results of the last long smart tests of your drives?
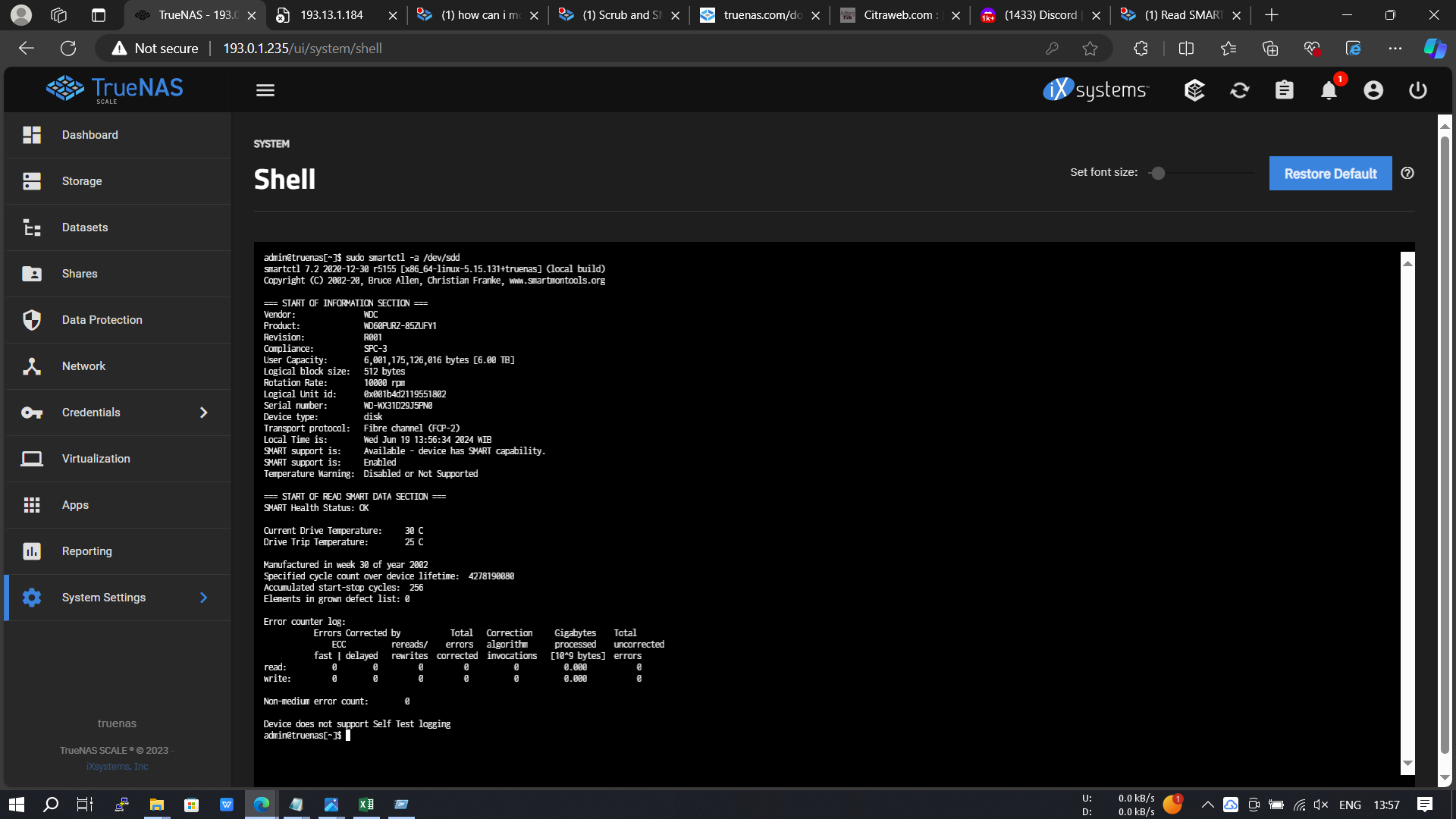
smartctl -a /dev/XXX
I haven’t tried the smart test, with raid-z2 and 2 failed drives at the moment I can still access my data, but I’m worried that if there are additional drives that are degraded then my data will be lost
what HBA card is right, do you have any suggestions on the type of HBA card?
Don’t you have any period smart tests scheduled?
Did all drives degrade at once?
Honestly I’m surprised the pool isn’t dead yet. If the third drive faults your data is gone. Hopefully you’re already on the backup.
Today I replaced 1 degraded disk. There is still 1 disk that I can’t replace.
Will the presence of a disk problem cause the TN Scale operating system to cause an error and not be able to be opened via a browser?
I haven’t period smart tests scheduled, i’m new to using TrueNAS. Helpme how to make a good smart test schedule


While I was waiting for the resilvering prosess. I looked at vdev and found something ilke the following, how can it be like that?
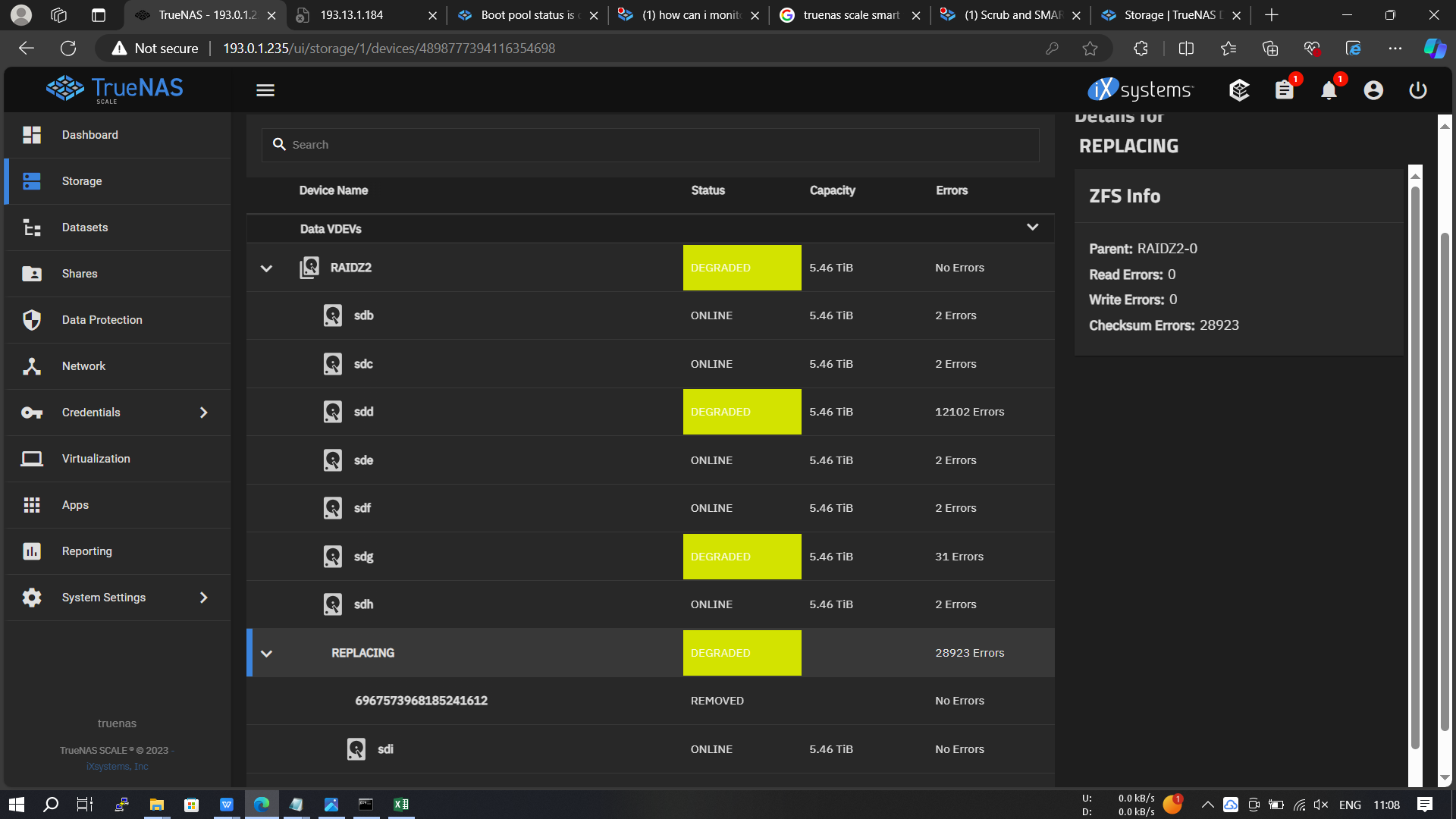
Plz follow what @chuck32 wrote in his 2 replies.
Otherwise your data is gonna be toast real soon.
- Backup your data
- Get a HBA
- Run long smart tests
1 Like
6TBx8 with raid level-z2. I’m currently replacing 1 disk with a problem, but during the resilvering process a new problem emerged, 1 disk was degraded. resilvering time which was previously 4 hours has been reduced to 10 hours. While resilvering I did a little data backup but the data transfer performance was very slow and probably resulted in the resilvering process taking longer
Resilvering puts alot of stress on the other drives and there will be lots of I/O going through the controller.
I would not try any more resilvery before you determined, where these errors are coming from. It could be bad drives, the controller, bad RAM, cabling issues, etc…
Can the server be turned off during the resilvering process? because the server will have additional RAM memory. Currently the server only has 8GB RAM, the plan is to upgrade it to 16GB
What server ?
Supermicro motherboard-X11 series X11SCQ
Intel Core i7-8700 CPU@3.2GHz
8GB RAM
1x 64GB SSD (Bootpool)
8x 6TB WD Purple (SMB-Pool Raid-z2)
(ARC-1203-8i) controller with JBOD mode
Yes, the server has to be on for the resilvering process.
You can shutdown, install more ram and resilvering should resume when you restart.
Obviously, no recovering when turned off!
I’d guess that this is the cause of the errors, and I would replace with a cheap 8i LSI HBA in IT mode.
1 Like
With your latest screenshots which show errors on almost all drives this is the way.
Backup, get a new HBA, replace disks (if needed).
Just for clarification, truenas is not running since 2018 on the server, you just recently installed it?
I just tried it about 10 months ago. Previously I used this server as a VMS server