You need to post all your details on your truenas setup. Software version, all hardware details, pool info. Dedupe is a huge cause of problems if not set up correctly, uses a lot of RAM and is useful only on certain data.
Probably should just search the forums for Dedupe and see all the feedback from experienced posters.
Why do people answer questions that were not asked?
Its a yes or no question.
I am aware of the potential problems with dedupe.
I am aware of the memory requirements.
I do not want to have a conversation about the pros and cons of dedupe.
If you do not know the answer just ignore the thread.
I will repeat the question so it becomes obvious what I was asking.
Can I use the same disks for both metadata and dedupe?
This seems like it is possible in the openzfs documentation, but its not in the gui and not outlined explicitly.
The dedupe will only be used for a small subset of vms so the DDT will never be very large and the goal is to use intel 670P disks for the write endurance.
So no I do not need a lecture on pros and cons of dedupe.
What I actually need is clearer documentation so that I dont have to ask the internet since people are more interested in giving lectures than answering a direct and explicit question.
Its less aggravating to just buy a motherboard with more pcie slots and a new case than to have to deal with people who either cannot read or cannot follow directions.
TrueNAS Scale doesn’t support partitioning volumes via the Web UI. While you could possibly partition them at the command line, it’s unclear how you would make the middleware utilize a partition instead of just reformatting the whole device when you assign it a role. I haven’t found a way to do that on my system; the middleware wants the whole disk.
The real issue is that anything the middleware doesn’t do may not persist. If you can partition your device the way you want and assign multiple vdevs with roles to it, once it’s part of the pool it may be fine, but I suspect the middleware’s behavior for self-healing and other activities in this scenario may be undefined. So, performance issues aside, the best way to test would be to try to get the partitions added to the appropriate pool, reboot, and then test what happens to the disk/pool if you offline the disk.
Obviously, don’t do this on a pool that isn’t backed up. However, I can’t think of any other way to test it on Scale 24.10 if the configuration or recovery behaviors for this scenario aren’t documented, which they currently are not.
It’s not technically necessary in ZFS but everything in TrueNAS (UI, middleware) assumes one drive per role.
So you can argue all you want - you can do whatever you desire on the command line - the only configuration that is guaranteed to be supported in the UI and survive TrueNAS upgrades is a dedicated drive per role.
You asked about TrueNAS, not about ZFS, Linux, or whatever in general.
This definitely seems to be the case as recently as Electric Eel. For the enterprise market, this definitely makes sense. However, considering the growing size of SSDs and the currently-inherent limitations on the use put to a SLOG role and others it would be nice not to have to dedicate one or more whole drive slots or a mirrored pair of multi-TiB SSD devices in smaller enclosures. iX handles this by dedicating slots for what I believe are 128GiB drives in the iX Mini (they no longer sell the larger mini-towers) to avoid wasted drive space, but that leaves you with only only 5 full-sized slots.
I agree that complaining about how TrueNAS middleware currently works is not constructive. However, I for one would love to be able to provision roles on slices of an SSD rather than the whole thing. Since an SSD doesn’t have the seek overhead of an HDD, this seems like a net win, but even if it can be done you’d probably need to warn people about the performance impact they’d likely face with spinning rust.
Partitioning on arrays works with other file systems and enclosures. It may even work on ZFS without TrueNAS middleware. But, to reiterate your point, it doesn’t work on Electric Eel, and the non-enterprise market may not be of sufficient interest to iX to support it. If so, this seems like mostly an FAQ or documentation problem (or possibly a feature wish-list item) than anything else, but I can see how the current state of affairs can be confusing for SOHO or hobbyist implementations. TrueNAS is opinionated, and bakes in a lot of assumptions, and they can be pretty tough for some people to find those assumptions without spelunking into the forums.
There’s a bit to unpack here, so I’ll go bit by bit.
Quite simply, because not everyone has done the same degree of homework that you have. Deduplication carries a warning in the UI, and the other members of the community are wanting to make sure you aren’t going to accidentally put yourself into a situation or configuration that’s very difficult to get out of, because dedup can’t be applied or removed to data “in-place.”
Deduplication table data is placed first onto a dedicated Dedup VDEV, then a Metadata VDEV, and finally the data VDEVs if neither exists.
This is specific to the ZFS design around metadata handling. For other “split purposes” like “L2ARC+SLOG” or “boot+anything” - no, it’s not supported in the UI or middleware. If you hack it in yourself, it will work, because ZFS doesn’t prohibit it - but you may find Undocumented Features.
Side note: with the Intel 670p being a QLC consumer drive, it may not be ideal for special vdevs because of the small write sizes, but if you have three of them (I thought the 670p only came as small as 512G though?) then you will have some measure of redundancy there - although you may still experience significant write amplification at the NAND level.
I asked initially because the user profile was new and there was nothing giving the level of experience and knowledge with dedupe. There was no mention of the size for the backup dataset nor how much RAM is on the system.
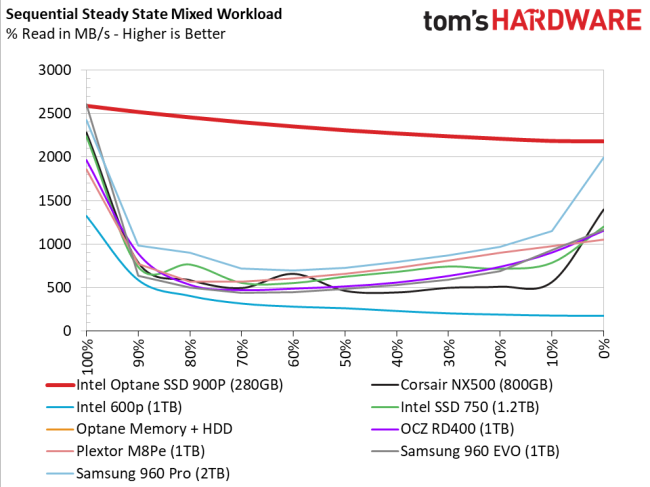
Yes and no. Have a look at this graph from Tom’s Hardware on SSDs:
As you start to mix the workload on an SSD, the response times increase, and bandwidth drops - it’s the classic “bathtub curve” - traditional NAND is at its peak when doing 100% reads or 100% writes. Ask it to mix the workload, and it suffers. Optane is the exception - it’s bit-addressable and maintains consistent performance. (Yes, I’m rather saddened by this product being withdrawn from the market.)
NVMe namespace support with QoS can potentially mitigate this, but there’s also the factor of handling failure domains, gracefully supporting device removal where possible, etc. It’s more complicated to support on an enterprise level than just splitting up a device into nvme0n1 and nvme0n2 and saying “okay, send it.”