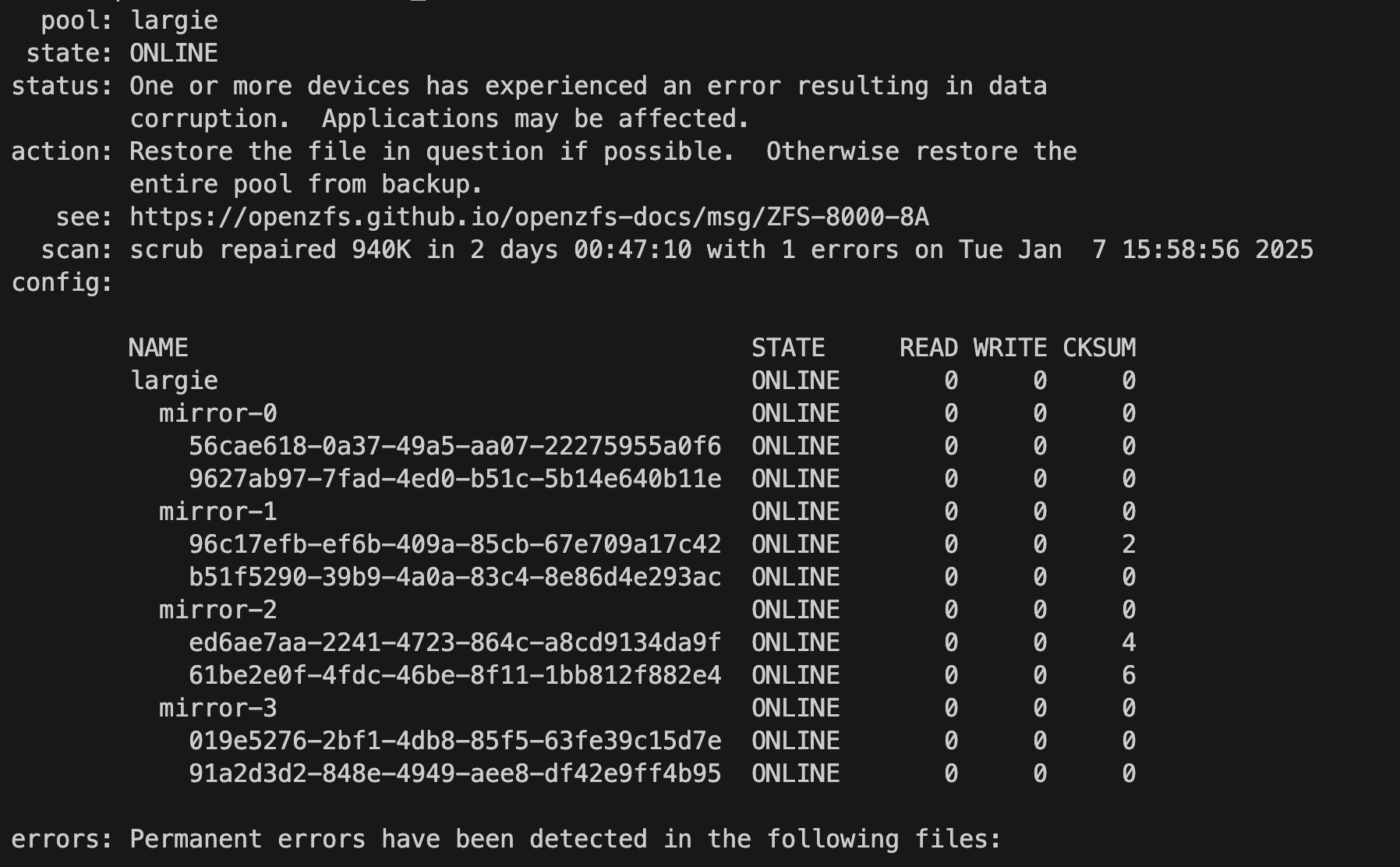
The second scrub finished. 3 disks reported checksum errors compared to the 6 in the first scrub. I ended up deleting the two files that showed in the first scrub before running the second. Interestingly, they still show in this scrub output. Is there a way to clear this other than ‘zpool clear’ since that didn’t clear them?
Thoughts on next steps? I assume there should be no errors, but how much of an immediate issue is this? I can try the remaining steps mentioned before. I just don’t know if I’m going to cause more issues taxing the disks by continuously scrubbing while troubleshooting.
It’s possible that these (supposedly corrupted) blocks are still referred to by snapshots. Until all pointers are released, the data blocks will remain in the pool.
Just an update in case others stumble across this.
I really honed in on the HBA, backplane, and SAS cables since my NVMe pool didn’t seem affected by this.
However, as time went on, I started getting system hard lockups. After moving PCIe cards around and troubleshooting, I finally ran a Memtest and was met with over 3000 errors within 1 minute of running the test.
Turns out, 4 DIMMs of DDR5 require significantly reduced speeds for stability. I read this before my build and made sure XMP was disabled and that memory was set to the Intel official non-overclocked speed of 4000MT/s. After reducing the speed to 3600MT/s, no errors registered in Memtest.
I am running a new scrub with the 3600 speeds and assume I’ll be met with checksum errors again on the first scrub since the RAM issues could have caused some data loss, but that a subsequent scrub should reduce no errors.
What does this mean for the data on the system - is it potentially all corrupt? Strangely, I have lots of Docker apps that never experienced issues. My SSD pools never had scrub issues.
I find it astounding that the system seemed otherwise fine aside from the few lockups and checksum errors on only 1 pool.
The line juuuust under the screenshot you shared would tell you. A single file is corrupt, but I am not sure which. When your system is healthy, You can try and initiate another scrub again to see if it clears up. zpool clear and zpool scrub a few times sometimes fixes these types of issues, assuming the underlying hardware issue that caused it is resolved.
It looks like you’ve got 3 potentially bad drives on your hands here. Start taking a look at SMART data and dmesg for drive issues, and then if all clear give another scrub a whirl.
WARNING THIS NEEDS TO BE RUN AS SUDO YOU TAKE RESPONSIBILITY FOR YOUR OWN SYSTEM
Post this back to the thread, feel free to sanitize the output if you need. cat /var/log/error && for d in /dev/sd?; do echo -e "\n=== $d ==="; smartctl -a "$d"; done
I guess my question is more that, how can I trust any of the data if it was written to disk with RAM errors? Since I’ve run scrubs before that it tried to repair, could that repair have caused corruption since it was the RAM breaking the checksum comparisons?
Probably not an issue, but I suppose it’s not impossible. The fact that you have checksum errors (as opposed to read or write) literally means ZFS caught someone “lying”. A few sequential scrubs may “figure out the descrepency”
If it doesn’t you would only have to delete that file to get HEALTHY in the pool again, and the rest of the pool is already safe if the memory sticks have been replaced/tested.
I am more concerned that the RAM errors may have masked (or contributed to) other hardware issues as well.
Can you elaborate on that last bit regarding other hardware issues - is that just a general concern or specific due to other symptoms I’ve listed? Thanks.
Edit: I assume you’re mentioning my last screenshot where only 3 drives have checksum errors. Each scrub is wildly different - typically all drives report checksum errors.
I believe it makes sense now that the RAM issue was discovered.
Only for data that was written like the first scenario in this post.
This would assume that the bad RAM saved a bad version of the file, but it also generated a valid checksum for the bad file. This means that subsequent scrubs will not catch it, since it will “pass” the checksum test.
You might be lucky and no data was ever written “wrong”.
EDIT: If you’re feeling paranoid, you can use rsync with the -n and -c parameters to check that the destination file integrities match the source’s. This will take a long time, since it will have to read every byte of every file on both sides.
Right, the scenario outlined is my fear - the data could have been corrupt on first write so a checksum would assume it’s good.
While I haven’t had any issues with corrupt files on TrueNAS, I am going to play it safe and restore all possible data from the initial source. I’ve been migrating from Synology to TrueNAS and the original data still exists on Synology, aside from some media files which don’t matter.
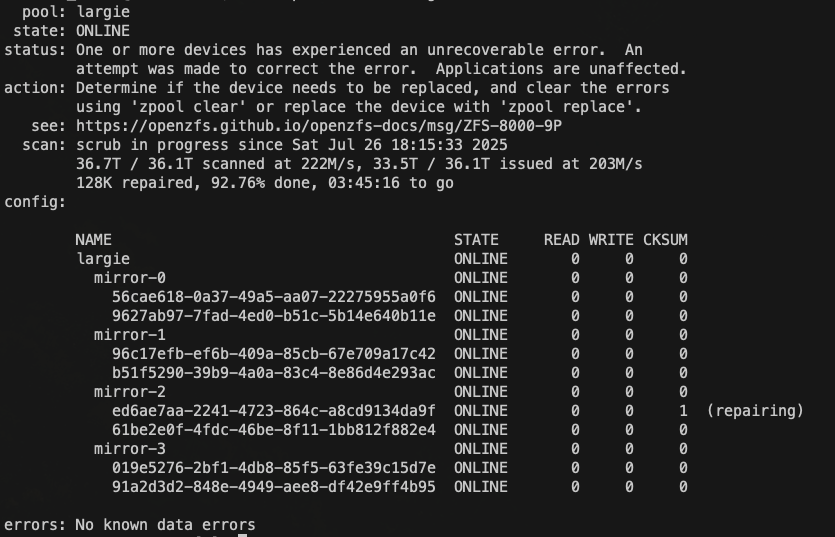
So far, the scrub has found 1 checksum error at 30%. I imagine it will find checksum errors on this scrub but after clearing, I will run another scrub and shouldn’t receive any errors then.
You can still get checksum errors because it’s also possible there’s a mismatch with the originally written block of data, but an improperly generated checksum.
This is why ECC RAM is recommended for NAS users. It’s not just a ZFS thing. For data integrity in general, it’s good to know that mistakes will be caught the moment they happen, rather than to find out about them much later.
This is also why “gaming” motherboards and components that appeal for “overclocking” in the consumer market are discouraged.
If a motherboard brags about integrated wifi, it probably shouldn’t be considered for building a serious NAS to manage important data.
Correct - I meant the first scrub with the RAM fixed will likely return checksum errors. But after letting the 1st scrub finish and clearing the errors, a subsequent scrub should look better and get things back to baseline.
I’ll look into ECC but I recall the options being expensive or limited. Is there a standard board, CPU, RAM combo you’d recommend for ECC?
Some ryzen ecc builds are reasonably cheap. Used server gear is also an option. Also, I personally found the Asus WS C422 DC mobo interesting. Have described it in this post.
It depends on what you call inexpensive and how much RAM you want. Go used servers with RDIMM ECC if you want a lot of memory. Price out ECC UDIMM, This goes in lower end servers and Ryzen types.
DDR4 is where you want to be. DDR5 UDIMMs are $$$, if you can even get them.
Your physical location matters as most of us post like you are in USA.
Resources List including Detailed Hardware and System Build Notes (plus new user advice / help)
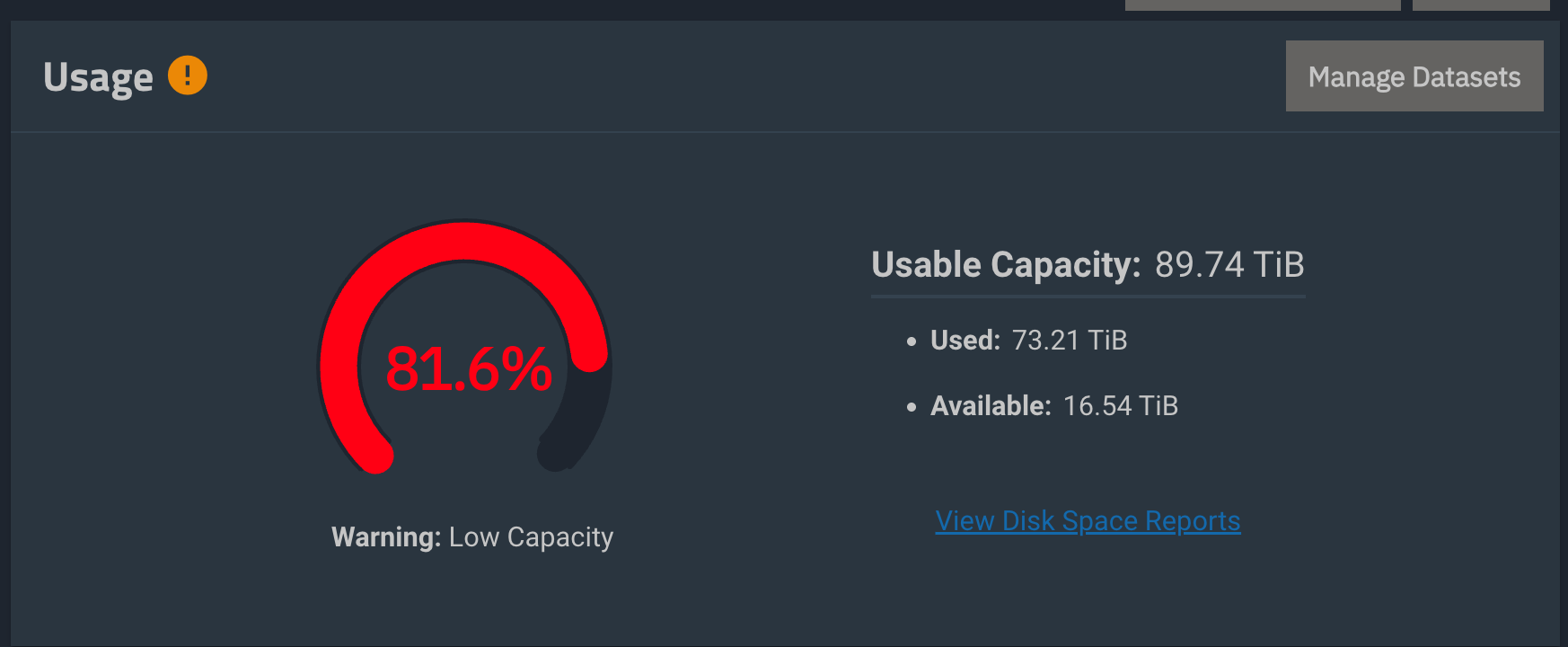
I am 93% into the scrub and only have 1 checksum error. However, TrueNAS is suddenly reporting wildly inaccurate pool usage information.
See screenshots below. What is going on here?
At some point during the scrub, scheduled snapshots were taken so I assume it’s related. However, I deleted all snapshots about 4 hours ago and the GUI still shows this.
Try these. If you had snapshots it might not update until finished
first it checking for block cloning, second is space. Post and paste results back using Preformatted Text mode </> on toolbar or Ctrl+e. Separate box for each command.
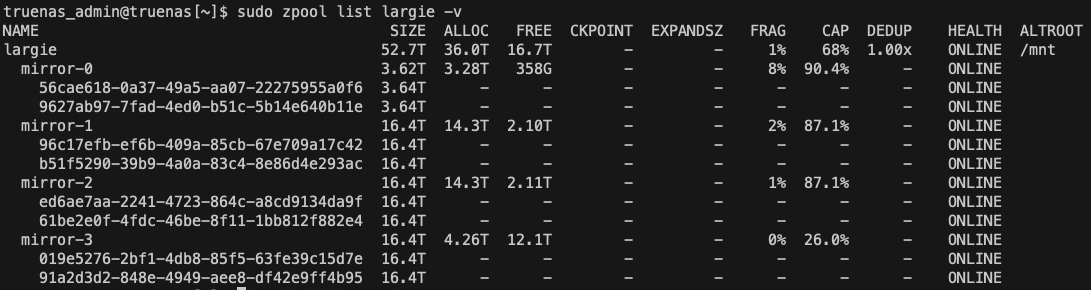
zpool list -o name,size,cap,alloc,free,bcloneratio,bcloneused,bclonesaved largie
zfs list -o space largie