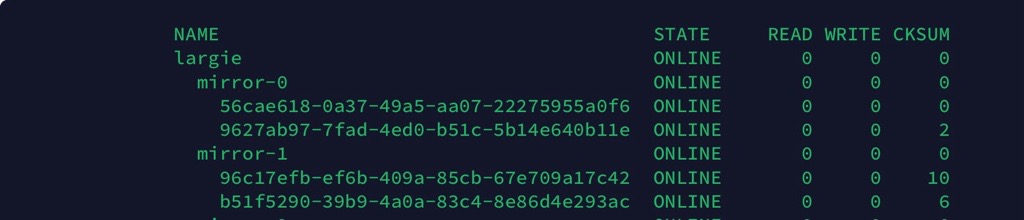
I created my first TrueNAS system in October and apparently didn’t run a scrub until now. First question - is there a way to view scrub history? ‘zpool status’ only shows the last scrub.
The scrub reported checksum errors, says it repaired 4.43M, and gave a list of corrupted files.
What should I do here? From reading around, it sounds like I should remove the corrupted files and run another scrub to see what happens. Or I should remove the files, manually clear the checksum errors, and run another scrub.
I’m not clear on whether I should clear the errors, and I don’t understand if all the checksum errors are caused from the two corrupted files or if there’s more to it.
Specs & further info:
Bare metal
Corsair RM850x
Core i9-12900k
96GB DDR5 4000MT/s
ASUS Z790-V AX Prime
Intel Arc A380
HL-15 chassis + backplane (connects to LSI)
LSI 9305-16i (effectively cooled by HL-15 mid row of fans)
Intel x520-DA2 10G NIC
2x4TB WD Reds CMR, 6x18TB EXOS (4 vdev mirrors < affected pool)
2x1TB NVMe SSDs (SN770 / SN850x - app pool)
1x1TB SATA SSD (dump pool)
2x256GB SATA SSDs (boot pool)
I copied about 40TB of files from another NAS to this system immediately after building it. I have 4 mirrored vdevs. Only two vdevs were in the system upon initial creation, the other 2 were added later.
8 disks total. 6 of the disks reported checksum errors in various amounts, with the highest being 13 and the lowest 1. Both disks in two of the vdevs reported errors while the remaining two disks were spread across two vdevs, meaning not all disks in a given vdev reported errors (not sure if that’s relevant).
Many forum threads mentioned cabling or LSI cards as a cause of checksum errors, particularly if it happens to all disks and across multiple scrubs. I’m not sure that fits my scenario quite yet, but this is the only pool using the LSI card & backplane of the HL-15. I have a number of Docker containers running on a separate NVMe SSD pool without issue. I’d suspect issues with PSU, CPU, memory would manifest in some way on that pool as well. So from a hardware perspective, the LSI, backplane, or SAS cables would be my first guess. The LSI was purchased off eBay. I know they run hot but I got stock fans with the HL-15 that run 100% 24x7 and it is truly blasting all my cards with good airflow.
Appreciate any advice!