I have 2 TrueNAS Scale servers that I manage remotely (both on version 24.10.2). The main server has a pool of 6 x RAIDZ1 | 10 wide | 18.19 TiB. The second server is used as a mirror, and the pool is set up as 3 x RAIDZ2 | 20 wide | 18.19 TiB. I can have physical access to them next week; in the meantime, I can only work on them remotely.
They’ve been running for 3 years without any issues. We recently moved the servers to a new room and then, after that, we upgraded from Core to Scale. We also wanted to use ZFS replication for the mirror instead of rsync, so we wiped the mirror (we also have offline backups, by the way).
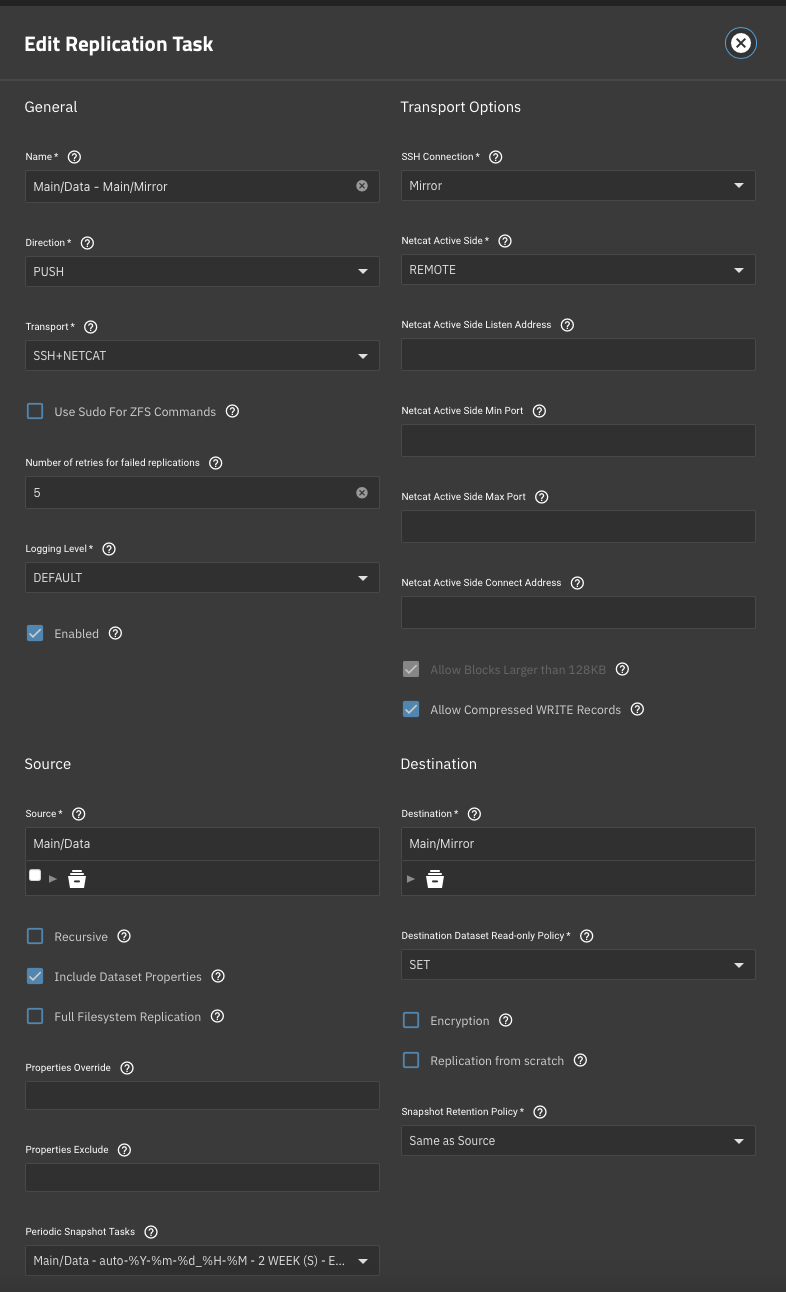
After upgrading to Scale, we initiated a brand new replication task (no encryption). Please view the attached screenshot.
Since we were mirroring 250TB, it took about 5 days.
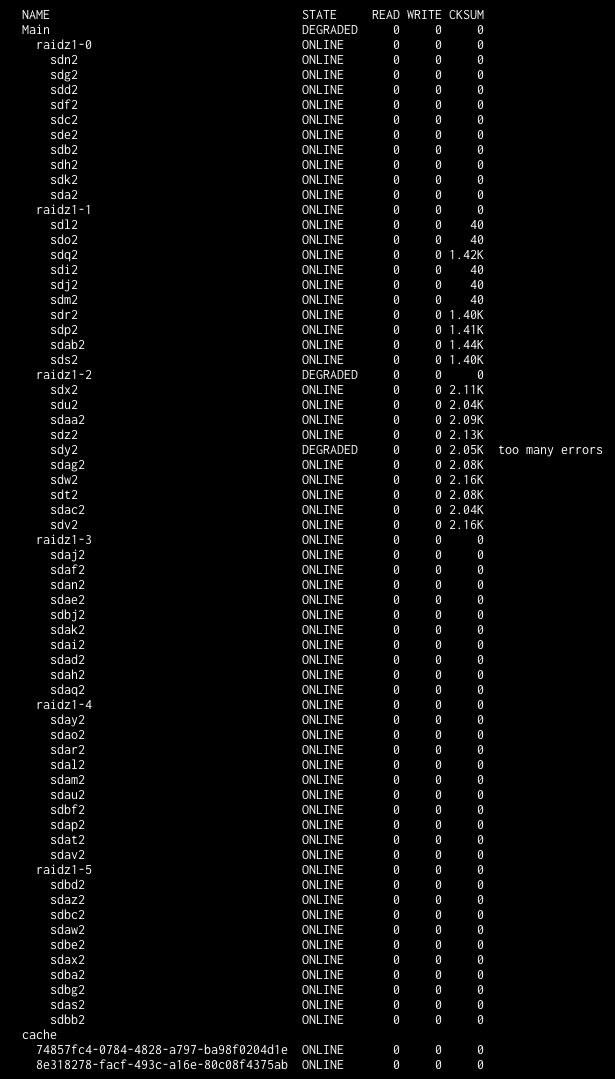
The first problem: 2 days into the transfer, a scrub task on the main server started to run and began finding tons of checksum errors on a cluster of drives, which are all under the same LSI 9305-16I HBA card. There are 4 x LSI 9305-16I cards. My guess is that there is something wrong with that card, or it needs to be reseated or replaced? I attached a screenshot of the errors. If I run zpool status, I get a list of about 30 files with permanent errors.
What happened next is that the ZFS replication failed right at the end, with this message: Partially received snapshot is saved. A resuming stream can be generated on the sending system by running: zfs send -t 789c636064000310a.... If I try to run this, I get this error:
Error: Stream cannot be written to a terminal.
You must redirect standard output.
And if I try to start the replication task, it keeps giving me the “Partially received snapshot is saved” error.
The second problem: On the mirror server, I can see the Mirror dataset usage is about the size of the Main, so almost all the data has been transferred. But I can’t access that data. If I go to /mnt/Main/Mirror, there is nothing in it. Also, when clicking on the Mirror dataset, I get this error: [EFAULT] Failed retrieving USER quotas for Main/Mirror. Is there a way I can access the data that has been transferred?
Any pointers for both issues would be welcome! Thank you!