I recently did a fresh install of TrueNAS SCALE and noticed a problem. There is continuous writing activity on the boot disk every second. I’ve already set the “Storage Settings” in System Settings → Advanced to use a zvolume instead of the boot disk, but the issue persists.
Everything worked fine with TrueNAS CORE. Does anyone have any suggestions on how to fix this? Any help would be greatly appreciated!
It would be good to know what your version is, and what kind of services / workload you have configured. But in general SCALE tends to do much more logging / auditing of things, so you can expect to see a bit more disk noise to the boot device. Not necessarily a bug. But we need to know those other details and so if we can see if those writes are beyond norms.
Yes, correct, of course, it doesn’t mean that “everything is broken”.
I haven’t configured a timeout for the disks to go to sleep.
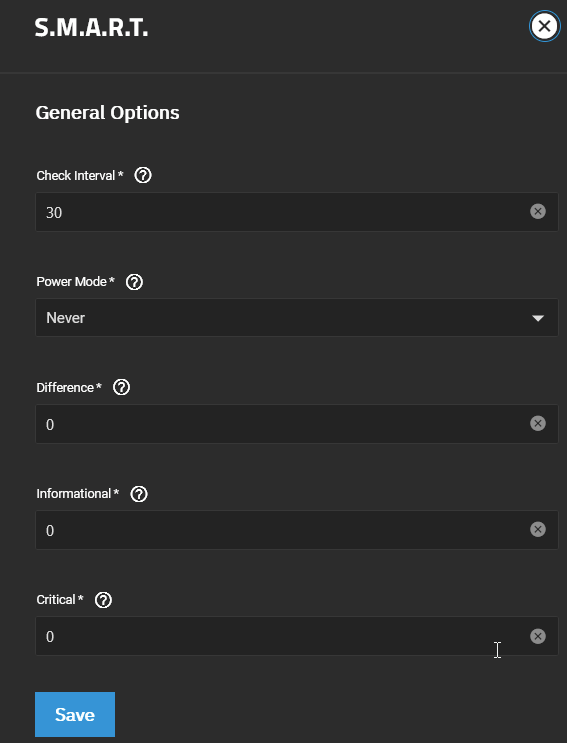
I also haven’t changed the default setting of the SMART service.
That’s why I mentioned that in the CORE version is fine, and I don’t see any activity.
But here, it’s not occasional activity; it’s constant writing.
Is there any way to fix this?
I’m also curious to know if this problem is observed by everyone or only in certain setups.
That comes out to just over 14GiB of writes per day if the mean stays the same.
It’s a home lab install with SMB up as well as Jellyfin and a couple other apps running (no heavy apps like arr’s or similar), no VM:s at this point in time.
I can’t say I feel worried my boot drive is going to die because of it but it does feel excessive.
Is that data useful? I think it’s reports data, but that’s really just speculation.
14GB a day does seem really excessive, even for the logging we typically do. We’d need more context or a debug from your system to figure out if something is writing a lot more than it should be in your case.
I understand what the logs are for.
I’m worried that at the moment I don’t need them and I don’t know how to make them smaller in order to prevent unnecessary wear on the disk.
We already are pretty sure we know the culprit in this case. But I will always tend to error on the side of more data than less. Often we find one issue easily. But with additional data we are more confident if the fix will work universally or if there are additional factors which need accounting for in a proposed solution.
My writes are 500 KiB/second over the course of a day, average, assuming you believe the reporting system. So, if I convert right, that’s about 44GB/day. I have 4 VMs and 19 apps. MY syslog level is set to info though, not sure if that’s the default or not.
Just a follow-up. We’re still looking into it, but so far the evidence seems to be pointing at a reporting issue specifically. Actual writes going to boot we see on our systems, as well as the debug from @ars is really low, like in the XX MB day, not GB’s a day. That said we’ll keep looking to see if there’s anything else major to fix here. Keep an eye on that ticket and we’ll update as we have a proper resolution, but for now nothing to really panic about.