Hello everyone
I am a beginner TrueNAS user and it still has many secrets for me. I would like to build a large data warehouse, but the two 8TB disks that I want to use to build a large pool are already occupied and I need to “stuff” this data somewhere for a few days. I came up with the idea of using old disks with BAD sectors. I built such a temporary pool of ~8TB = 3 x 3TB in RAID Z1 and 6 x 0.5TB in RAID Z1, but after loading the data, I was shown a message that one disk in VDEV (3x3TB) has the status FAULTED and the other two DEGRADED.
Therefore, I have a question. If the pool is working and visible as a network disk, can I normally copy data to it and from it? Is the data integrity not compromised? The question is whether the data I saved there will not be damaged after copying it again to another, good disk.
Please reply.
I would say that the data is only good if it Scrubs with no uncorrectable errors.
I guess “large” is relative. The hard drive on my first laptop was 128MB; my next desktop one was 3GB - and against these measures 8TB is pretty large. OTOH, professionally I have implemented EMC RAID arrays with several PB of disks, and ZFS and TrueNAS are absolutely designed to handle pools which are way larger than 8PB much less 8TB.
If this data is valuable and you don’t want to use it, then trusting it to a pool which starts from the basis of using known failing drives and yet only has single redundancy (RAIDZ1) is IMO pretty darned risky.
So my first advice for a “beginner TrueNAS user” is to run your ideas past more experienced users BEFORE you put them into practice. Ideally, rather than just confirming the sanity of your proposed solution, you might find it better to present your starting situation and ideal finish point and let them synergise the best plan.
My second advice is to STOP all attempts to modify anything or fix anything and to wait until there is a consensus on how to proceed before you do anything and risk making a delicate situation worse.
But we are where we are, and we need to try to help you recover from it…
The GOOD NEWS is that, from the sound of it the pool is degraded rather than lost - but we need to see the output of some diagnostics to get the details and to be sure.
So please post the output of the following in a reply here:
lsblksudo zpool status -v
My next thought is to ask whether you copied the data and still have the original data on your 8TB hard drives or whether you moved it to the dodgy drives and that is the only copy - because the next steps will depend on what your answer is to this. Also, if a move, what disk writes have you done on the 8TB drives since then (just in case we need to try to unerase the files from these in order to recover them).
Once we have this information, we can then advise on how much your data is currently at risk, and what strategy and actions might be besto to get back to a position of safety for your data.
P.S. I would say that you should NOT do a scrub yet. A scrub will put your disks under stress and this may cause data which is not yet lost to then be lost.
Please wait until we see the output of some diagnostics before doing anything that might put your data at more risk that it already is.
Sorry it took me so long to answer. Busy week.
Answering a few questions earlier:
- the data is only copied to check if its integrity will be maintained on damaged disks. I have the originals in a different place.
- the “scrub” process started and lasted about two days until TrueNAS finally hung and I had to reset it.
As for the command results, I can’t copy the result from the shell but I’ll try to upload screenshots.


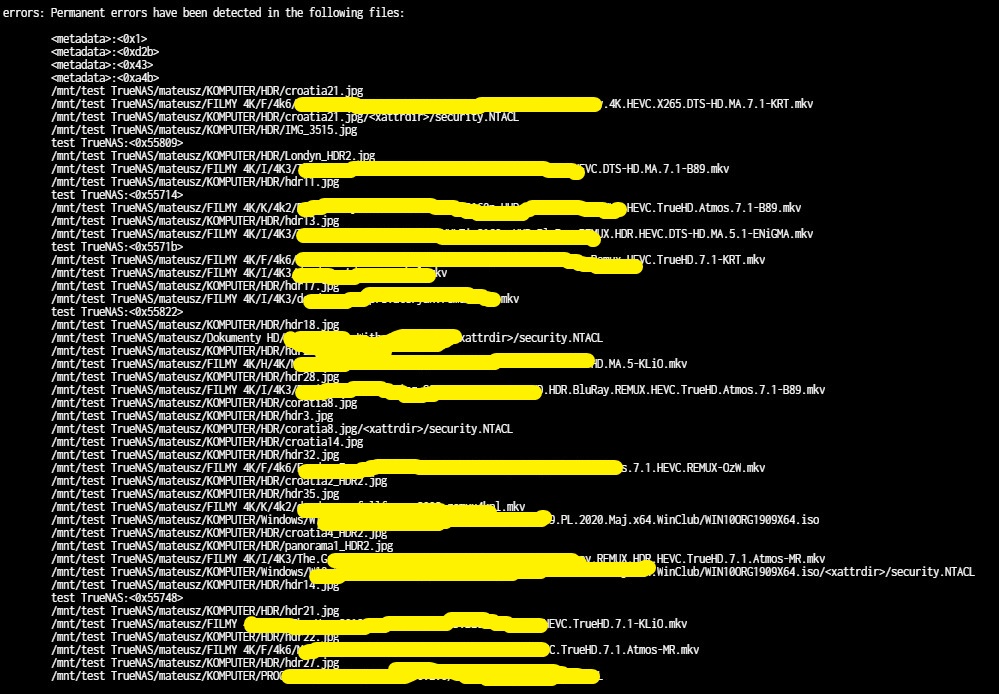

If you have the data safe somewhere else, then it seems to me that you have probably come to the end of the learning exercise on redundant vDev recovery.
It looks like the pool is toast and you now need to move forwards.
The first thing it seems to me that you need to do is to establish what devices are reliable and reusable. And this is an opportunity to experiment with testing that your hardware, empty of data, is reliable.
-
Establish which physical drive matches each of the drives in your pool, and especially establish the drives shown with 3 errors (too many errors), 0 errors (too many errors) and 399 errors (resilvering).
-
Destroy the pool
-
Run conveyance and long SMART tests on each drive (on each drive you can do one test at a time, but you can run tests on all drives in parallel).
-
Scrap any drives which fail SMART tests. Pay particular attention to the three drives in the raidz1-0 vDev - if they pass the SMART tests then you may need to run further stress tests on these drives.
-
When you have established a base of reliable drives, ask here again for advice on what vDev design you should use (listing your hardware).
Additional questions:
- Are those drives SMR? If you don’t know, please post the model number.
- What is your hardware: we need to at least know the motherboard and PSU models.
- How are you connecting your drives to the motherboard?
test bez rideis the pool where the original files are stored, and the one that contains the HDDs you want to put inside another pool, correct?- If so, why does your temporary
test TrueNaspool contains L2ARC and SLOG VDEVs? - How did you transfer your files from pool A (assuming
test bez ride) totest TrueNas? - Please share the output of
zpool list -v test TrueNasafter the scrub is complete.
The fact that you got permanent errors in so many files even with a parity disk points out to a deeper issue in your system. Those files are compromised and will have to be restored from backup.
Without knowing your hardware specs and the outout of the SMART data after a long test we cannot diagnose further.
Good advice from Davvo there, however, as someone who is asking for advice here, presumably because you think that others here may have more experience or knowledge, I am not that clear why:
- when I say “don’t run a scrub” because it will put more stress on your drives,
- you decide to ignore that advice and do a scrub anyway.
This is IMO not really a great response to those of us spending our own valuable time to try to help you.
Thank you very much for your help so far, but every time I started trueNAS the SCRUB process started automatically, I couldn’t stop it (zpool scrub -s [pool] - doesn’t work, didn’t find the zpool command), and after one full day it practically hung the system. The only option I knew was to delete the pool. This wasn’t easy either because every time I got an error that the pool was busy and that the process had failed. Only after the third or fourth attempt did I manage to delete the problematic pool with disks.
Answering the next questions:
- They are probably not SMR disks, all the disks I have are WD purple (PURZ)
- The equipment I bought is rather economical
- HP elitdesk 800 G2 SFF computer with i5-5600 processor; 32GB RAM, the system is on SSD WD Red SA500 (500GB)
- LSI Logic 9305-24i controller (china)
- PCIe-X1 adapter with two NVME ports + two Lexar NM620 256GB drives in RAID 1 - SLOG
- PCIe-X1 adapter with one NVME port + one Lexar NM620 512GB drive - L2ARC
- Intel DELL X520-DA2 0942V6 2x10Gb SFP+ network card
- first power supply built into the computer and the second Crosair RM750 - 750W to which only the drives and fans are connected
-
The drives are connected via an LSI Logic 9305-24i controller imported from China - additionally the computer has two free SATA ports - so in total it is possible to connect 26 drives and that is almost how many I would like to connect eventually - 9x8TB (raid z1) + 10x6TB (raid z1) + 5x 4TB (raid z1). At the moment I have all the data on the computer with 10x6TB and 5x4TB (without any raids), today the last 8TB disk arrived and I would like to slowly build pools on TrueNAS and transfer data. At first I wanted to build a pool with (9x8TB which should give me about 64TB in RAID Z1) then transfer data from 10x6TB to it, and finally build vDev from free 6TB disks and attach it to this pool. Then I want to repeat the whole process with 5x4TB disks. Additionally L2ARC and SLOG disks to speed it up a bit.
-
“test without raid” is an additional pool also with damaged disks - I just wanted to check the speeds of copying over the network using a 10GB network card. There was nothing on this pool and there were only 3 disks 120GB, 250GB and 1TB.
-
I transferred data from another computer over the network (SMB)
-
SCRUB never finished and the only way I found was to delete the pool.
At the moment, all the disks have arrived and I would like to build one large pool described in point three on the equipment described in point two.
Would you have any advice? What to look for? What to avoid?
After building the first pool (9x8TB) should I test the disks in some way before I start transferring data from 10x6TB?
I have one more question. After adding the Intel DELL X520-DA2 0942V6 2x10Gb SFP+ network card, suddenly trueNAS started showing me that I have 16GB RAM and not 32GB - could it be its fault?
Thank you very much for your help.
That’s strange, did you try with sudo?
Flashed in IT mode?
ZFS is incompatibile with hardware RAID.
You want at least RAIDZ2. With the 4TB drives as well, but they are less a risk being smaller in both size and Number: if they will be part of the same pool as the other drives, you should go RAIDZ2.
You don’t have enough RAM for L2ARC (at least 64 GB) and you likely don’t need a SLOG.
Before creating the pool, run the following script to all disks for a few days, then run a long test.
Remove it and check, seems strange but it’s not impossible.
-
- That’s strange. Have you tried sudo?
![]() no, but it’s too late now
no, but it’s too late now
-
- Did you flash in IT mode?
no. I bought it, connected it and it works. I haven’t done anything else with this card or with this card.
-
- The ZFS system is not compatible with hardware RAID
I meant more “mirroring”
-
- You need at least RAIDZ2…
Is RAIDZ2 necessary with so many disks? This is not a company server with data that the company’s operation depends on, but only home, family data, which I also don’t want to lose (except family photos, losing them = divorce ![]() , but I think I’ll put them in two different locations). It won’t work 24/7, but only in the evenings a few days a week. I am building RAID because the computer I am working on is on almost all the time, but I do not need the contents of the disks at that time and, as you know, electricity is getting more and more expensive, and because I would like to have time to react if something bad happens to the disks.
, but I think I’ll put them in two different locations). It won’t work 24/7, but only in the evenings a few days a week. I am building RAID because the computer I am working on is on almost all the time, but I do not need the contents of the disks at that time and, as you know, electricity is getting more and more expensive, and because I would like to have time to react if something bad happens to the disks.
Does your or your experience show that two disks can fail at the same time (RAIDZ2)? and you can lose everything because of it? Or maybe after the above specified number of disks in vDev, RAIDZ2 is already required and I did not read it?
The data contained on these disks will be sent to the server and streamed over the home network (there may be transcoding on the fly), hence the 10GB network card.
If you think that RAIDZ2 is needed here, then I will do so, because I am just starting my adventure with TrueNAS and my knowledge is still small.
-
- You do not have enough RAM for L2ARC (at least 64 GB) and you probably do not need SLOG.
L2ARC - can I create L2ARC memory now? In a month or two I would buy another 32GB RAM and then I would be able to use it
SLOG - if I create a 5x4TB vDev (raidz1 or raidz2) at the end, wouldn’t the read and write speed (that’s why L2ARC is needed) of the entire pool slow down to the slowest vDev in the pool? Wouldn’t I be able to speed it up a bit by using SLOG and L2ARC?
-
- Before creating the pool, run the following script on all disks for a few days, then run a long test.
A few days? OMG… I don’t know if I will have such a possibility, but if so, I will, but the link you provided is inactive: “http://ftp//ftp.sol.net/incoming/solnet-array-test-v3.sh”
And wouldn’t a long SMART test be enough?
-
- Take it out and check. It seems strange, but it’s not impossible
I’ll try to check as soon as I get home…
Thanks for your help
It is always tempting when you read about how L2ARC and special vDevs and SLOG can massively improve the performance of your NAS, but the one-line descriptions of these technologies do not explain why the special solutions were designed to fix specific special situations, many of which only occur in large scale TrueNAS / ZFS installations in large enterprises where the NAS is heavily used and where performance is critical for specialised applications.
The reality is that for a home / family business (many of which are SMB with Windows PCs and media serving with Plex / Jellyfin) you are pretty unlikely to have either the heavy use or the specialised use cases that require these solutions.
As an example, my NAS is a dual core ancient Celeron with 10GB of memory, a 1Gb ethernet connection, 5x4TB drives and a single 256GB SSD used for both boot pool and an apps pool. This is almost the minimum specification possible for TrueNAS SCALE and yet it performs brilliantly, sharing data at 1Gb speeds with a 99.9% ARC hit rate, able to stream full-HD and effectively limited by the LAN speed.
If my low-spec system is network bandwidth limited, why do you think you need SLOG or L2ARC to speed up your system?
Yup.
It is not, you have to simply paste in the SSH/terminal fetch ftp://ftp.sol.net/incoming/solnet-array-test-v3.sh.
SLOG is only useful with sync writes, which do not happen with home systems. And do note that sync writes with the best SLOG money could buy is still an order of magnitude slower than async—it just sucks less.
As for L2ARC, if your system already has an ARC hit ratio around 99% it won’t do anything.
Resist featuritis and the urge to tick as many boxes as possible with ZFS advanced features…
I have tested all of my drives for 7-10 days before deploying. Some do one month of burn-in before anything else…
Of course, if you’re doing a temporary pool with known bad drives, you may skip such tests, but do no skimp on redundancy because ZFS WILL notice that the drives are in bad shape.
The drives themselves WILL notice: they LOVE screwing you up when you have no parity in place. Drives are evil, don’t trust them: protect your data.
This is an oversimplification.
As an example, macOS is used at home. It uses sync writes with SMB.
![]()
![]()
![]()
![]()
Which is a good thing.
Better to know a file is corrupted and recover it from backup, or redundancy than to only find out when you look at that photo in 20 years time.
-
I would absolutely agree with @Davvo on the need for RAIDZ2 when you have 60TB or 72TB in the vDev. With that number of drives and that size of drives, resilvering after you lose one drive is going to take a significant time during which all the drives in the vDev get very stressed. There is little point in having RAIDZ1 if the stress of the very lengthy resilvering after you lose one drive is going to cause a second drive to fail during the resilvering process.
-
The case for RAIDZ2 on the 5x4TB drives is less black and white, though I fully agree with @Davvo on this too and here is my reasoning:
- If the 5x4TB drives were in a separate pool, then I might well be inclined to use RAIDZ1, because the smaller drives and the smaller number of drives both mean a shorter resilvering time. That said, this was my reasoning when I set up my own NAS (5x4TB) - I didn’t want to have a 40% redundancy overhead - but now I wish I had chosen that anyway. However…
- This vDev is going to be in the same pool as the other RAIDZ2 vDevs. And although the risks of losing the vDev is the same as if it were in a separate pool, if the vDev fails you lose the data from the whole pool i.e. instead of losing the data from 16TB of useable space, you will be losing the data from 120TB of useable space. So the consequences are far greater. And this is why I agree with @Davvo that you should use RAIDZ2 on the 5x4TB vDev despite this being a significant overhead.
…for TimeMachine background backups which no-one should care to speed up.
I stand by my oversimplification.