Greetings community,
Disclaimer: I’m new to this community, I’m new to TrueNAS, new to ZFS. Basically I’m just out of my depth (or exploring my horizons?). I tried to be as thorough as possible in providing all data I believed necessary. Please forgive my ignorance if I have missed something critical or ask stupid questions.
I’ll also add that I did try and look for answers to the below on both the old and new TrueNAS forums, reddit and stack overflow - the complexity of ZFS and possibly my (pooly architected?) config may be to blame.
Background about me:
IT professional, self taught, mostly worked within Microsoft suite and software development for the past 10 years. Side hobby in hardware, but no experience in enterprise setting. Build my first server in January 2024 and after a lot of research ended up with TrueNAS Scale and ZFS.
Background about the issue:
Used the server friday evening for media playback, had a momentary “outage” but it recovered in a minute or so and I didnt get up to investigate.
Couple of hours later I go to check, everything looks fine.
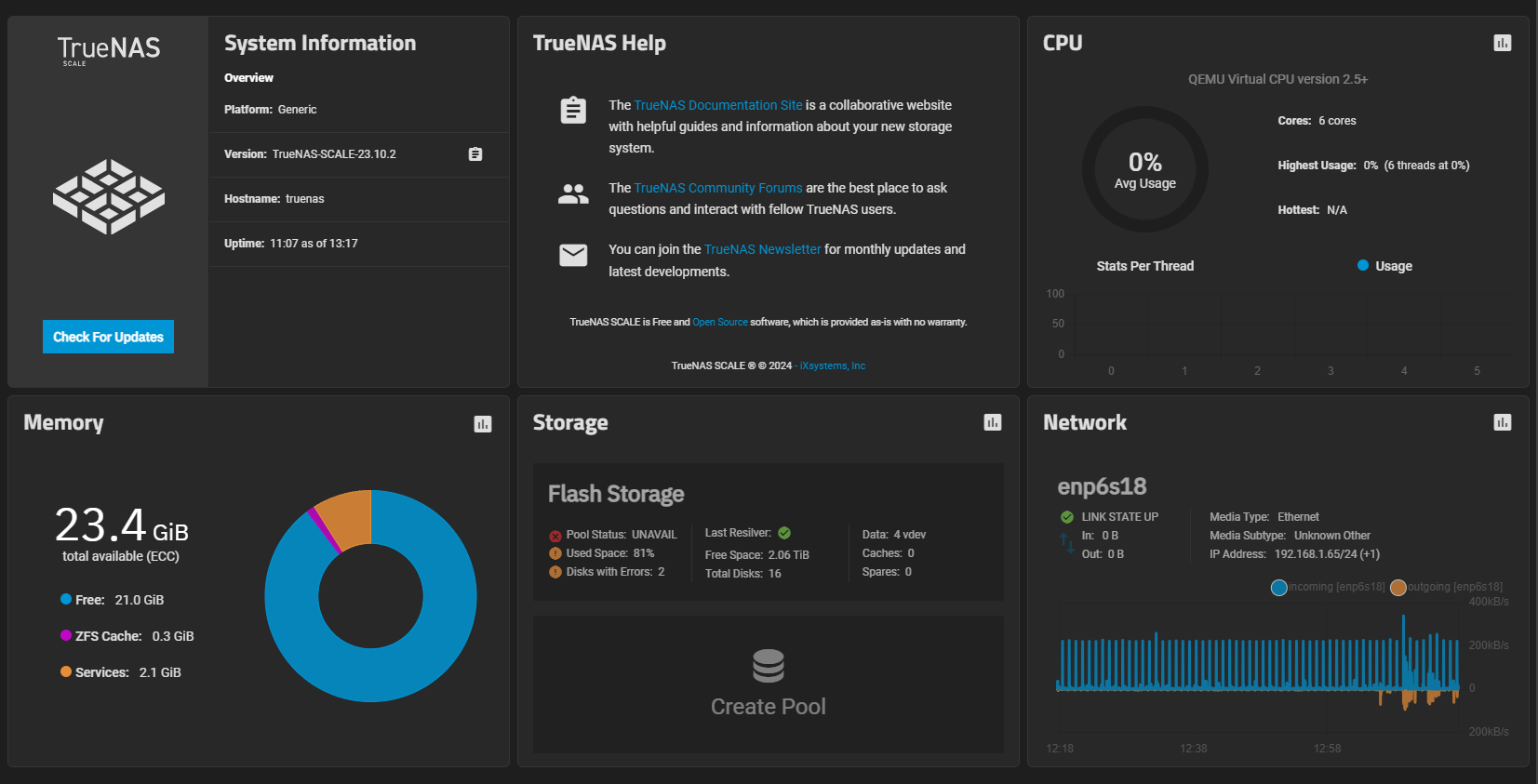
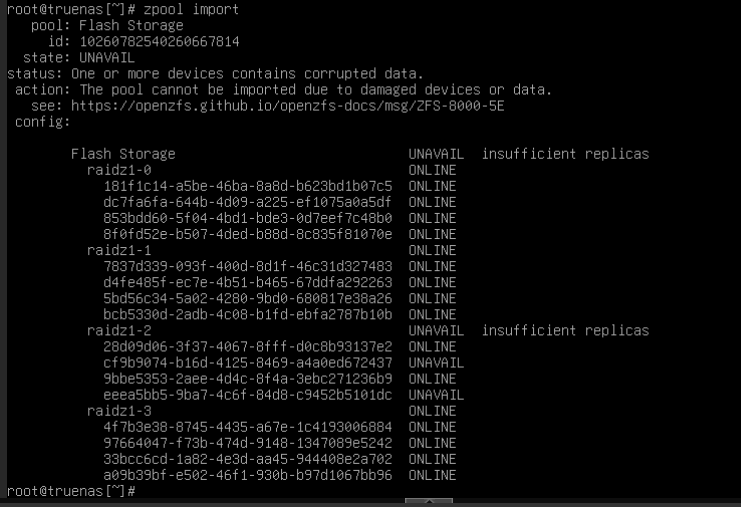
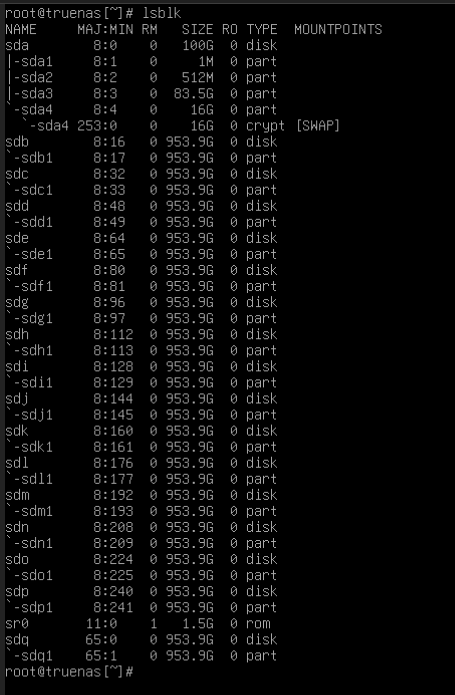
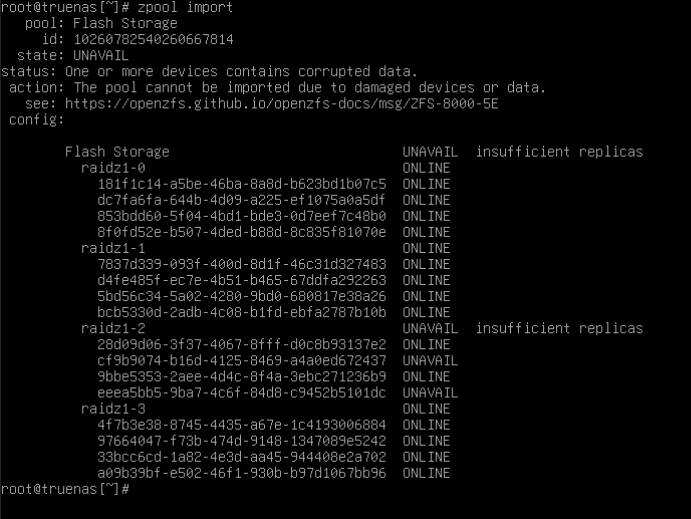
Suddenly I’m disconnected from all hosted webapps in TrueNAS, through proxmox console I see repeated restarts for 3-4 minutes. Once it settled down and booted my storage pool was deprecated. It said I had 2 unassigned disks. In my stupidity I tried adding these back to the pool which I believe may have wiped them.
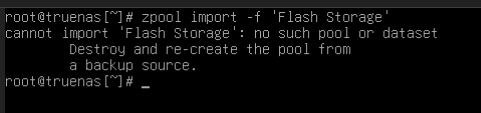
I followed up with trying to export the pool which then removed it from the interface and now import pool says “No options”
For the next hours I scour the internet for a solution. I have no idea why this happened.
Hardware:
Mostly consumer hardware.
ASUS Z270-a motherboard, Intel i7-7700 underclocked (6 core assigned to TrueNAS)
32GB DDR4-2400 (24GB allocated to TrueNAS)
1TB NVMe (100GB allocated to TrueNAS)
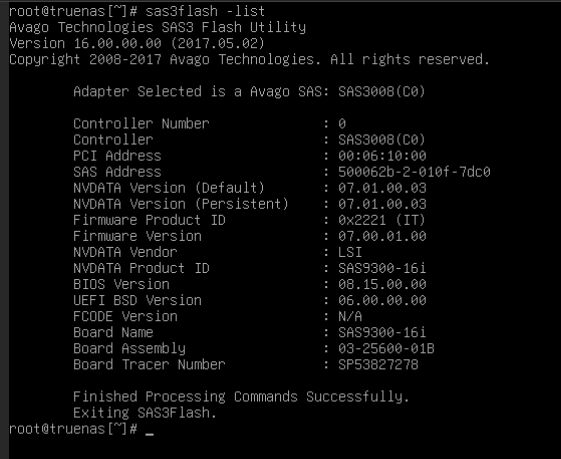
LSI 9300-i16 IT mode HBA
16x 1TB ADATA TLC SATA 2.5" SSDs
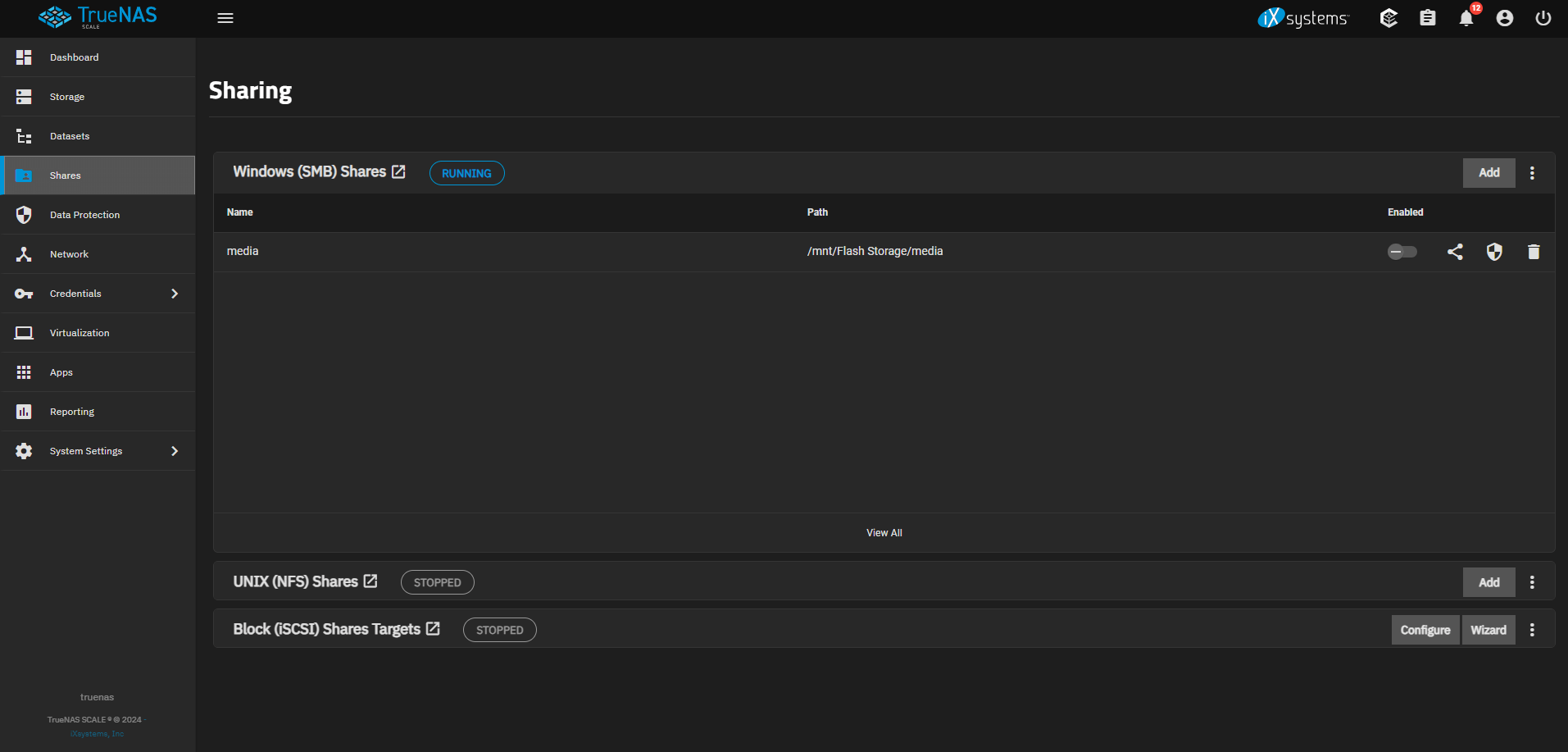
About my config:
TrueNAS SCALE virtualized on Proxmox
1 Pool, 4 vdevs of 4 disks in z1
About my data:
No backups
Nothing critical, mostly replaceable media.
I can afford to lose everything but it’s just a lot of work to restore (like a lot of work)
About my assumptions:
I realize ZFS even in any Z stripe is redundancy - NOT backup, I however believed that if two disks in a z1 vdev were losts this would only affect the vdev and that the pool would continue to be usable with only data on the vdev being lost.
Current situation:

Additional information:
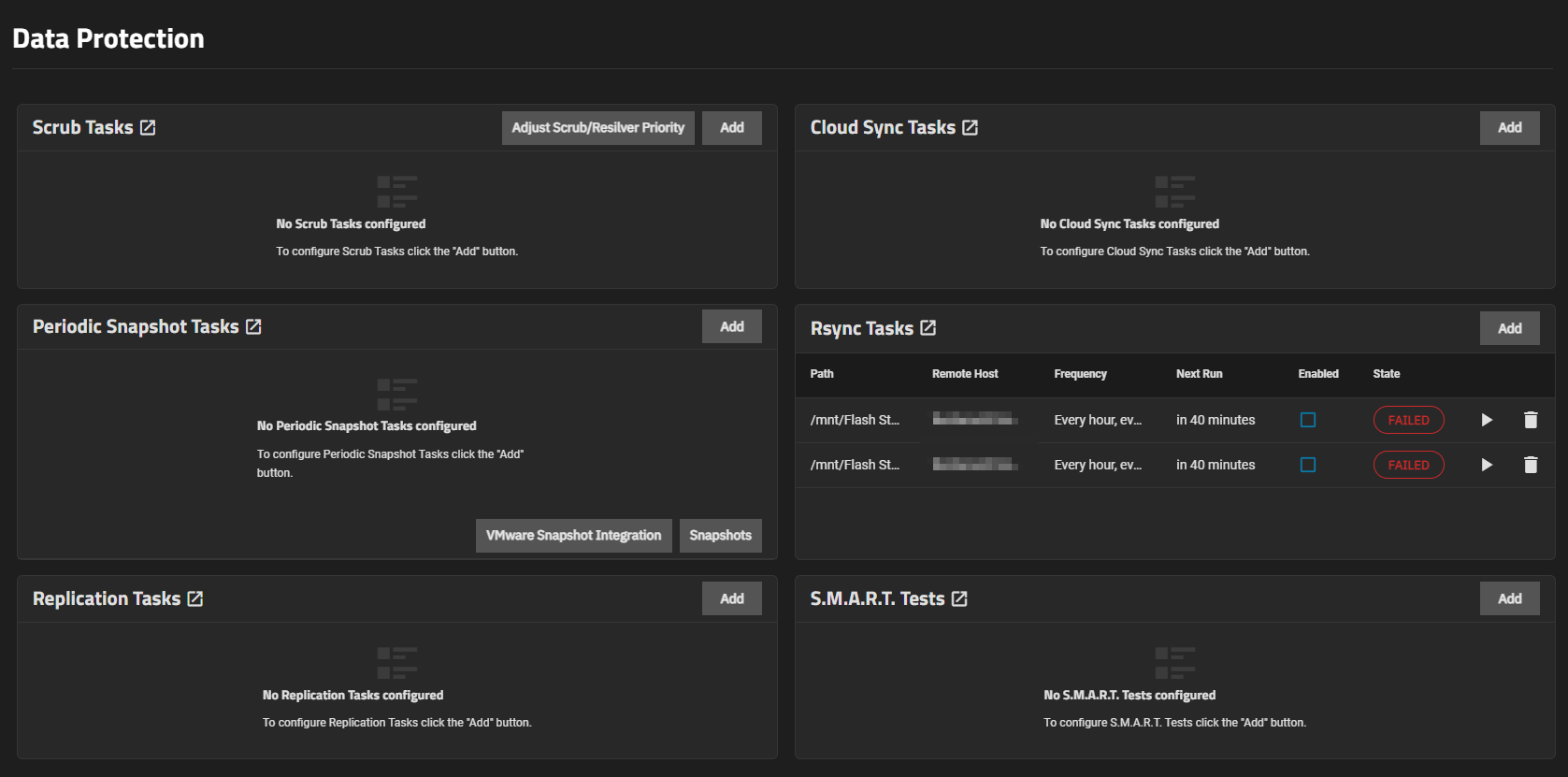
The time of the restart incident was around the time I have 2 rsync tasks running. I have had these running for a few weeks without incident but I cannot help suspect the timing. It’s possible that combined with a noob-underclock of the CPU triggered the issue
I was unsure about leaving “Scrub tasks” due to it being flash storage, however opted to just leave it ON as per default.
Desired outcome:
Main Goal:
- A final conclusion as to whether/if recovery of data on remaining vdevs is realistic (and any assistance you can provide if it is).
Secondary:
- Any validation or correction to my assumptions (see above)
- Some guidance on any changes I should make in the future of the pool - if any, for my current 16 disk pool
- Some guidance on leveragining my 16 sata SSDs for ZIL/SLOG/L2ARC. I’m currently building a DAS/JBOD for the server (24-bay) where I plan on buying 4x12TB WD Red Plus drives to start out. I want to potentially keep a flash pool of 4-10TB for VMs and other projects and leverage the rest for speeding up the attached JBOD HDDs. Should I consider Hot spares?
- To learn something about data management and restoration on Linux/ZFS