My two cents…
While your cooling methods are not good, I do think the heat is causing the your issue, just not where you think it is.
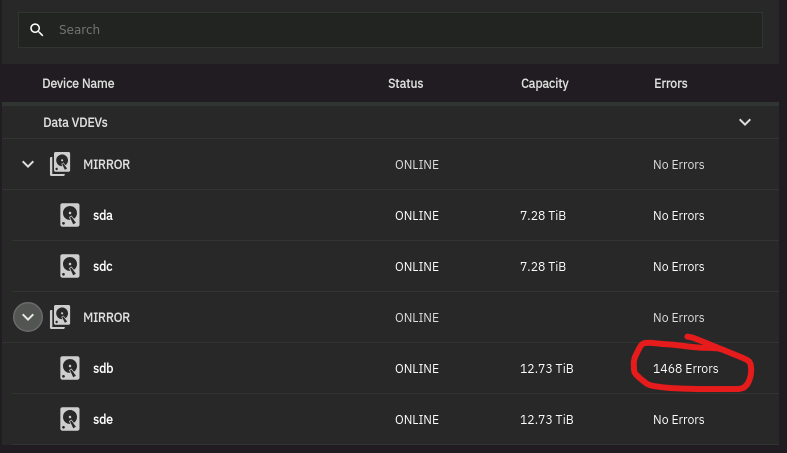
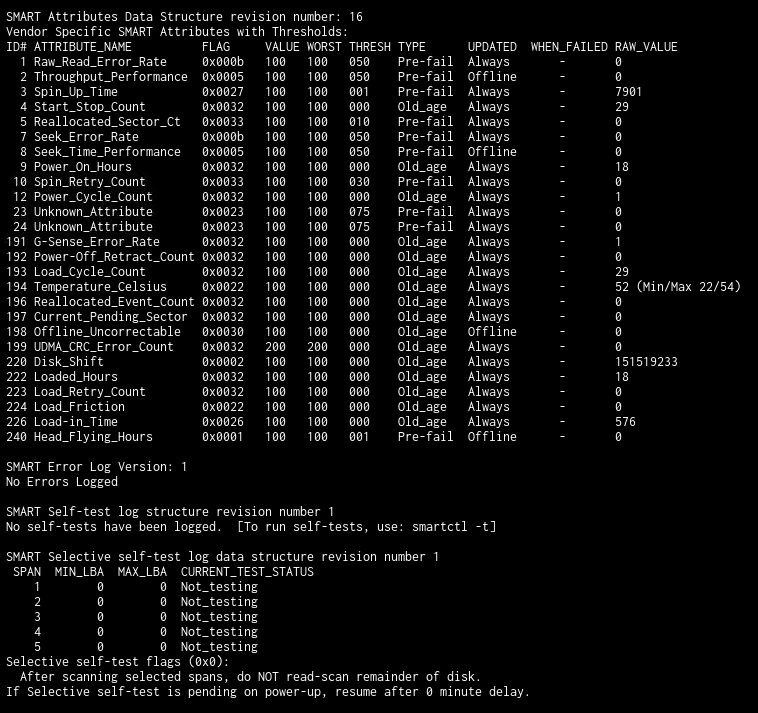
First lets attack the HDD since you are moving in that direction already. You have no SMART errors, you did not run a SMART Long test however you were provided advice to run the test so commence that test. When you start the test odds are it told you to poll the drive again for results after XX minutes. If not or you do not recall that value, run smartctl -a /dev/sdb and near the top if the data that spits out, look for Extended test time and the value is likely within parentheses. Could be well over 600. Anyway this is how many minutes the Long test should take, assuming no real activity on the drive, but I’m going to ask you to give it some activity. You can also check the test status using that same command, just read the data it generates, you will find it. And one more thing, If your drive hits that 54C value, you do realize that you have likely voided your warranty, right?
I suspect the drive will test just fine, so going off that premise and looking at the actual error messages you are having, these are likely ZFS errors.
Go ahead and enter zpool -v status and provide all the data, do not assume you can provide less of it and that this is good enough. It often isn’t and delays fixing the problem. What I am looking for in particular is the pool name so you can use it in the next step below, however it may also provide other information that will narrow down the problem.
Let’s say you have some errors that show up getting this status message (I expect it to), next is to run a scrub by typing zpool scrub poolname where poolname is the name of the pool with the suspect drive.
The goal here is to have the scrub pass and you have zero file errors. You may have checksum errors or other errors, but so long as the scrub reports no file errors then your data should be fully in tact. And we can discuss the next step if things work out as I expect.
Do not get ZFS errors confused with Drive Errors, they are not the same and the majority of the time the drive is not at fault. It could be the controller/HBA, an unstable system (too hot), bad power supply. I’m leaning towards the too hot myself.
Oh yes, you can run the scrub commands (I highly advise it) while the drive is performing the SMART test. The SMART test has a lower priority so the SCRUB will finish first. Just do not power off the system or reboot it or the SMART test will abort and you will need to start all over again. You could use tmux here with the zpool commands or since you are only dealing with a single drive, it will not really benefit you.
If you have any questions about the instructions, ask before you do anything. Be smart, it is your data and we suspect you will want to retain it. If I don’t answer, there are many others here who are smarter than me that will help out.
And a question: How did you get that screen of the drive errors? I must be blind today as I cannot locate it on my TrueNAS 24.04.2 system.
Cheers!