At 2AM a scheduled scrub started, at 2:03AM a disk was “removed by the administrator”?
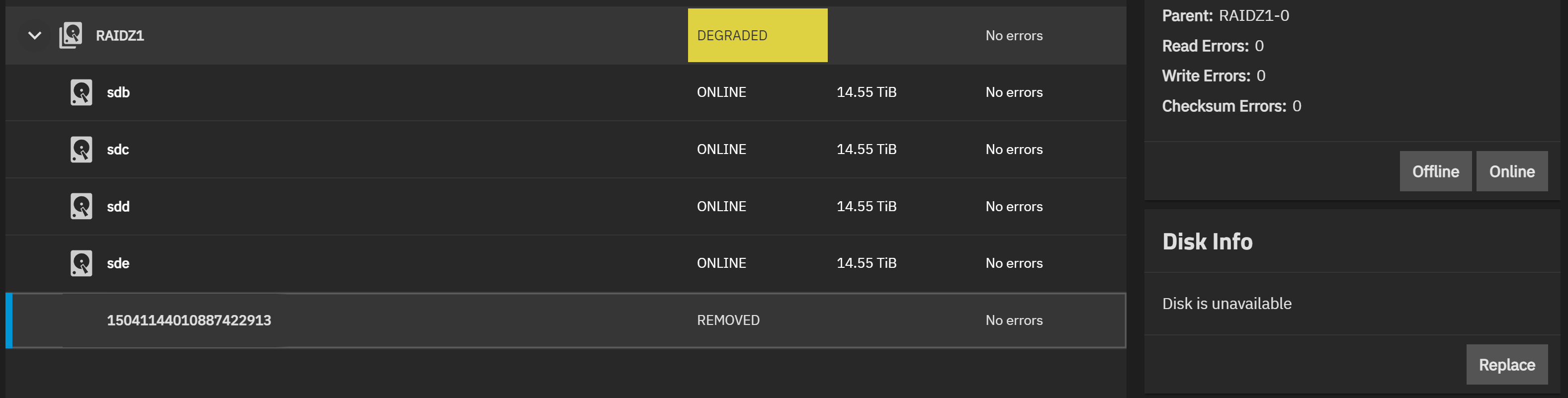
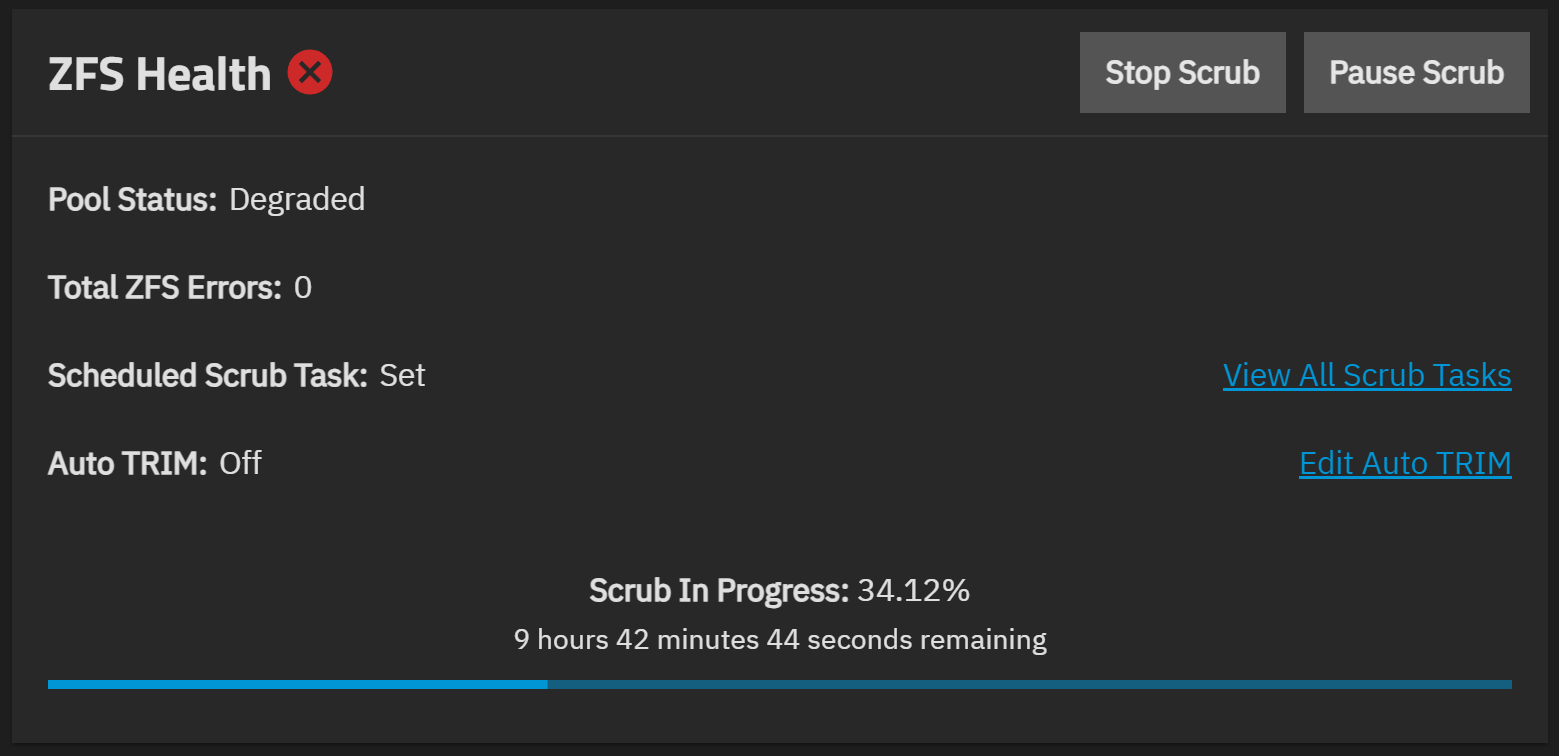
Pool spinning state is DEGRADED: One or more devices has been removed by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state.
The following devices are not healthy:
Disk ST16000NM001G-2KK103 ZL2A9K4Z is REMOVED
Running Fangtooth 25.04
So:
- I did not remove the disk as I was asleep when this happened.
- The disk also seems to have no errors (unless the errors got cleared when the disk was “removed”)
- The scrub is still running, shouldnt it be stopped when a disk drops out to not put more strain on the pool, at least until the disk can be replaced?
From syslog:
May 27 02:03:17 NAS kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
May 27 02:03:17 NAS kernel: sd 1:0:4:0: [sdf] tag#3412 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=4s
May 27 02:03:17 NAS kernel: sd 1:0:4:0: [sdf] tag#3412 Sense Key : Medium Error [current]
May 27 02:03:17 NAS kernel: sd 1:0:4:0: [sdf] tag#3412 Add. Sense: Unrecovered read error
May 27 02:03:17 NAS kernel: sd 1:0:4:0: [sdf] tag#3412 CDB: Read(16) 88 00 00 00 00 00 03 40 f7 40 00 00 08 00 00 00
May 27 02:03:17 NAS kernel: critical medium error, dev sdf, sector 54590048 op 0x0:(READ) flags 0x0 phys_seg 44 prio class 0
May 27 02:03:17 NAS kernel: zio pool=spinning vdev=/dev/disk/by-partuuid/3959a140-9fb9-4c0b-857e-f5f68d24fd41 error=61 type=1 offset=27948646400 size=1048576 flags=2148533424
May 27 02:03:53 NAS kernel: sd 1:0:4:0: task abort: SUCCESS scmd(0x000000004259685f)
May 27 02:03:54 NAS kernel: sd 1:0:4:0: [sdf] tag#3445 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=30s
May 27 02:03:54 NAS kernel: sd 1:0:4:0: [sdf] tag#3445 Sense Key : Not Ready [current]
May 27 02:03:54 NAS kernel: sd 1:0:4:0: [sdf] tag#3445 Add. Sense: Logical unit not ready, cause not reportable
May 27 02:03:54 NAS kernel: sd 1:0:4:0: [sdf] tag#3445 CDB: Synchronize Cache(10) 35 00 00 00 00 00 00 00 00 00
May 27 02:03:54 NAS kernel: I/O error, dev sdf, sector 0 op 0x1:(WRITE) flags 0x800 phys_seg 0 prio class 0
May 27 02:03:54 NAS kernel: zio pool=spinning vdev=/dev/disk/by-partuuid/3959a140-9fb9-4c0b-857e-f5f68d24fd41 error=5 type=5 offset=0 size=0 flags=2098304