I don’t think that my concern there is unreasonable (and I note that I’m not the only one affected by whatever’s causing it), particularly when that appears to be the root cause of the apps problems[1],[2]. And I’m aware that it’s assigned, and I presume more is happening behind the scenes than is noted on the ticket. I’m referring more to the first several comments on that ticket, which went straight to “TrueCharts” even though I thought the pool import issue was pretty clear even then[3].
And yes, I’m also aware that at least some on the TC side don’t play well with iX. I think it’d be in everybody’s best interests (especially the users’) that iX and TC work better together, and I suspect there’s background that I’m not aware of, so I’m not assigning blame anywhere on that question. But I’d very much like to see the situation improve.
And I’ll freely admit I’m not an expert in the inner workings of these things, but “apps pool isn’t imported when the system finishes booting” and “k3s can’t start because the relevant datasets aren’t available” sure seem like they’d be related. ↩︎
That TrueCharts have decided that only Dragonfish will be a supported platform is an aggravating factor, but definitely not your fault. ↩︎
Again, I could be wrong–but if the thinking is that I am wrong, I think addressing that would have been helpful: “I see you’re concerned about the time to import your pool, but I don’t think that’s the fundamental issue here because…” As I don’t have any such explanation, I’m left thinking that’s where the issue is. ↩︎
This was enlightening and I understand your point of view a bit better. Your ticket is assigned to someone else but I’ll keep an eye on it. Your particular problem (zpool import taking > 20mins (I looked at the logs on the ticket)) is perplexing and to make matters worse, there really isn’t too many people reporting the same problem (unless I’m missing something). However the other user that reports similar issues seems to also have different sized vdevs in a zpool. I have 0 clue if that’s even remotely related, but it’s an obvious similarity that I’ve seen.
Thanks to everyone for the guidance in addressing these performance issues in Dragonfish. I read the release notes before upgrading from Cobia and noticed the removal of the ZFS ARC 50% RAM limit. After upgrading to Dragonfish and noticing extremely slow performance after a couple days and swap full, I had a suspicion that something went horribly wrong with the ARC limit removal. Sure enough, setting the limit back to 50% solved my performance issues.
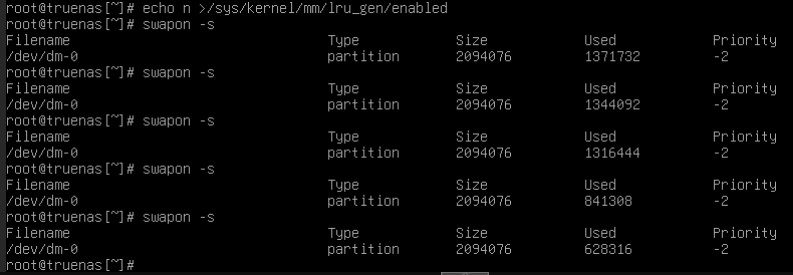
It’s good to hear that the multi-gen LRU changes in the 6.6 kernel seem to be the cause here. I’ll try with swap re-enabled, ARC 50% size limit removed and multi-gen LRU disabled. It seems like that is the preferred resolution to these issues, correct?
I know it’s off-topic to this thread, but just to respond to your point, DragonFish is the only version of SCALE currently eligible for support from us, but our apps are still working fine on Cobia at current.
Prior to DF’s release we made available a legacy, Cobia-specific branch of TrueCharts’ apps for people staying on Cobia longer-term to use. Nobody has been forced to move to DragonFish yet to ensure apps continue getting updates etc. but once apps stop working on Cobia, users wanting to remain on there longer-term (for whatever reason) can move to the legacy apps branch.
I’m not personally encouraging people to migrate to DF until the .1 update drops and resolves the already-discussed issues with it.
Just to be clear, this involves removing and re-adding the TC catalog, right? I don’t see a way to edit the existing catalog to use a different branch.
3 Days and all fine here - in fact rather than going back to Core, im planning to stay with Scale. Writes appear to be faster, ISCSI connections are more solid. Pretty happy with Scale after the initials problems.
Thanks for everyones help, and work on this - I also learned quite a bit too.
This would bias memory reclaim against anonymous pages and towards file pages. Isn’t this the exact opposite of what we would want for a NAS use case?
IMHO, for a NAS under memory pressure, it would be better to reclaim unused anonymous pages instead of file pages that could hold file data that could be needed.
Oh right, that makes sense. Thanks for pointing that out. It begs the question as to what changing swappiness from the default will even accomplish then. Why bother to bias swapping against anonymous pages then?
Generally we want to avoid swapping, it’s better to rather have ZFS ARC prune itself to avoid memory pressure as it has better knowledge of what’s least valuable and can be discarded.
We don’t want to never swap, as swap is preferable to “OOM, start killing processes” and IIRC it was back in kernel 3.5 where vm.swappiness=0 was changed to mean “NEVER swap” so 1 is the lowest we can go while still having swap be present as an “emergency pressure release.”
Probably the biggest reason we haven’t caught this issue is that the majority of our QA is done on TrueNAS appliances. We disabled swap for our appliances many years ago because of the performance variability. We only sell appliances with adequate RAM.
During BETA and RC.1 we had about 5,000 users and no clear pattern of issues. As you indicated, in hindsight there are some relevant bug reports, but the symptoms are diverse and there is always a possibility of hardware issues.
I am running with 16GB memory on two HP microservers. I use one as NAS only to backup my primary with smb shares and plex and transmission truecharts apps. I have seen this 2GB swap used up only on the primary. Reboot sorts and can get into gui again. It’s happened twice. About 2 weeks apart. It happened today again. So I have swapoff -a in the cli on primary. I can report back in a month if it prevents the issue. I have a docker truecommand instance running that loses it’s session to the primary when this happens so if you wanted to setup test rigs that could be used to identify suspects. The secondary records 0 swap used.
In the aforementioned (previous post of mine) retrospect, hopefully this results in iX perhaps changing some QA parameters for future SCALE releases. Presumably, there’s a handful of iX machines that are reserved for QA use, so perhaps changing the setup on some of those to reflect how things are done on DIY/Generic SCALE systems would help to avoid this in the future.
I get only wanting to do first-party testing on hardware and software combinations that iX actually sells, but if I had to guess I’d say the vast majority of SCALE’s userbase is on DIY/Generic systems, so how those are setup and run/maintained should ultimately be accounted for as part of the QA or validation process.
Alternatively, align SCALE’s minimum/recommended specs to match those of hardware that iX can reliably ensure performance on (this would have ultimately meant the responsibility for this issue still fell on iX QA as there wouldn’t have been a scenario where adequate RAM wasn’t available to the system, since ZFS appeared to just be using all available system RAM minus 1GB), or (hot take) drop DIY/Generic SCALE support or branch it out to “SCALE for DIY” if it’s simply too much work for iX to validate against.
I don’t want to derail the discussion, but maybe swap should be disabled by default for everyone? It could be optionally enabled for users that don’t provision enough RAM and then you don’t have to provide support for such users by flagging such unsupported configurations. I don’t see much benefit for degrading performance so badly that it is completely unusable (with swap) vs. the OOM killer kicking in to free memory (no swap).
For users with plenty of memory, the pattern shows up as a huge ARC with swap 100% used. I could see something was wrong when my system with 128 GB RAM had 80-90 GB of ARC but swap was 100% used and the system was very slow. Hindsight is 20/20 but just a pattern to consider for the future.
Understand that, but the point was brought up that problem reports were discounted by iX because swap was involved while they explicitly disable it for their systems. If there is a common, supported configuration without swap, that issue becomes irrelevant.
It would have been pretty obvious something was very wrong if no swap was configured, 90 GB out of 128 GB total RAM was used for ARC and the system was repeatedly invoking the OOM killer, right?
They could optionally enable swap and then iX can selectively ignore their problem reports then.