Hello! I’m asking the community for help from anyone that is experiencing the dreaded “memory leak” or “using all swap” issue. If anyone has a minimal reproduction case or can give me access to their system while the system is in this bad state, I would greatly appreciate you reaching out to me directly.
PLEASE NOTE: I have reproduced the “high CPU usage” issue. I understand that problem fully and the next SCALE DF release will have that squashed (no work-around unfortunately). (For anyone interested in that particular problem see: PR #1, and PR #2)
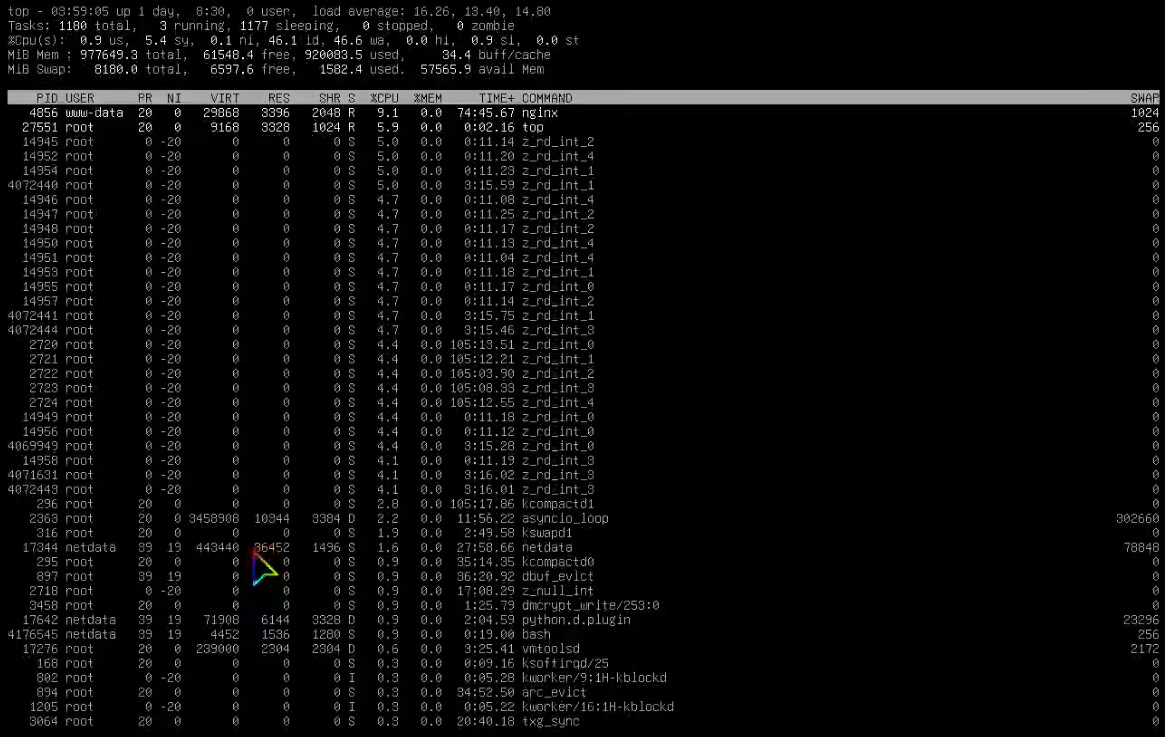
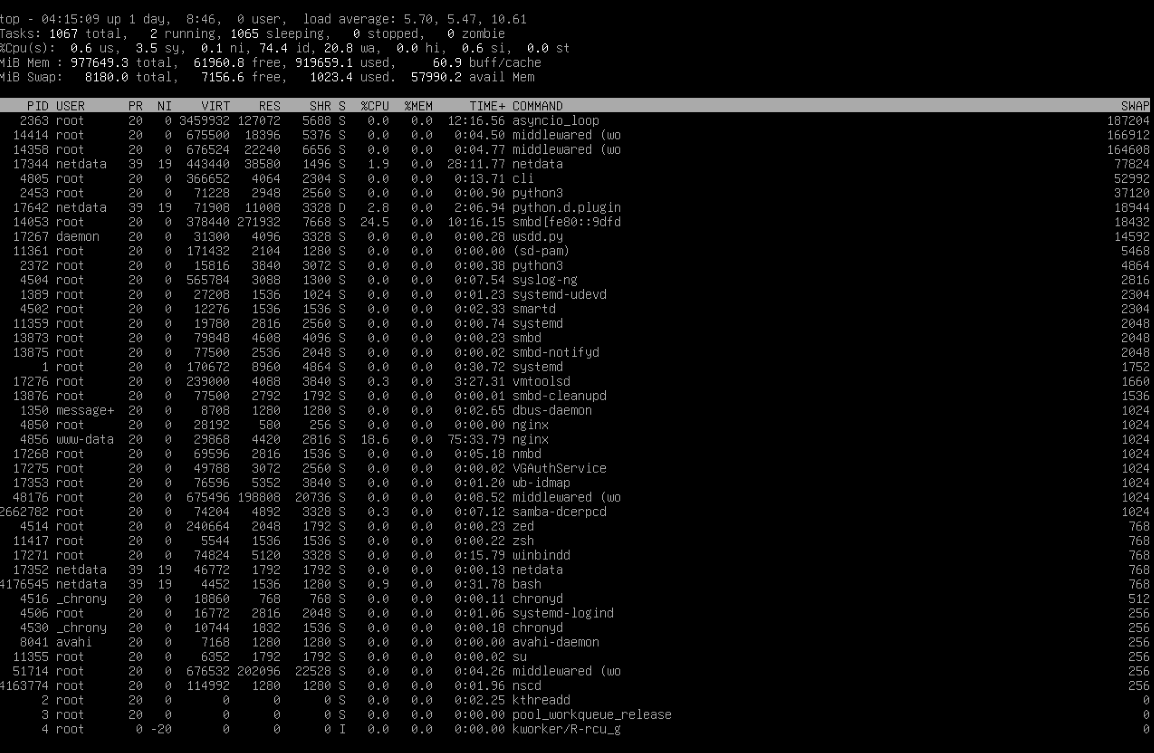
I cannot consistently reproduce my issue, but it happens rather frequently. I experienced it 3~4 times in 4~5 days. Consistents of high amount of mixture file transfer amounts to around 80TBs+. The highest swap usage was by “asyncio_loop”, swap was about 1.6GB/8GB when issue exists. I have 1TB of RAM, 900 ish for ARC, only 15GB for service, and still 65 ish GB free.
I have an identical system but potentially with less RAM to work with for my offsite backup(not yet offsite, still w me), so potentially I will again need to transfer 80TB+ data and may very well run into the same issue. If i do I am open for dev to lookin to my particular case if one’s interested.
btw, new to truenas, forum, and been a while in discord. How to reach out to OP directly?
I’m interested definitely. When you say asyncio_loop was the highest memory usage, how much was it using? Do you recall? If you suspect this is the memory leak, you can run top -em -oRES. That will sort the output of processes by resident memory use.
If you mean privately, on the left hand side menu, create a new DM to his user. If that’s what you are asking. Or, if you mean publicly, just use @ and his username.
didn’t reply my DM, so I am posting here. i took screnshot when issue happened yesterday, i didn’t do exact command u gave, i just added swap column and sorted it, the second screenshot is sorted, first was not, first was web UI lockup as you can see the swap is 1.6G used; and CLI typing will have HUGE delay, let’s say i type “1234qwerasdfr” the characters won’t appear and the cursor would be idle, and suddenly “1234q” appears after 5 seconds in chunks, second ss is degraded performance, but web UI is accessible, while being slow.(all file transfer stopped)
Sorry here’s the right thread to share my experience:
62 Truecharts apps and 256 GB RAM.
Update to DF yesterday and I’m having terrible performance issues, pretty much the same as it was on Cobia. I cleaned all my snapshots and my system is stable apart of the apps. Editing and Saving an app is taking a lot of time. Often the whole ui crash and is stuck for 5 minutes on the login loading page.
I have migrated another server with fewer apps and 32 GB RAM and this server is snappy responsive.
Please IX, hear me out: Fix the rubbish gui. It doesn’t make any sense with 256 GB and 72 cores to have something that feels such broken.
Replying in here because apparently I’m limited to 3 replies in the same thread for some reason:
It has now been about a day and a half since I applied the fix to limit ZFS RAM usage to 50% of total available system RAM.
It has completely solved all of the performance issues I was experiencing with my system.
Middlewared is now nowhere to be seen in the “top” processes list in a shell window
Swap hasn’t been touched at all since I made the change
CPU usage is entirely back to normal
There has been no sporadic dumping of writes to the SSD housing my SCALE install
The UI is back to being instantly responsive, as was the case on Cobia
I can only conclude that whatever ZFS is forcing to be kicked out of RAM and run from swap, my primary culprit would be the iX middleware, causes the extremely poor performance. Something a bit less than “total system RAM minus 1GB” is probably a better way to go, perhaps allowing ZFS to use 75% of total system RAM or such, or alternatively something of an internal whitelist that says “when under RAM pressure, don’t evict these processes automatically:…”
@bitpushr Bumped up your permissions here, so you won’t hit that limit.
If you were interested in doing a bit more troubleshooting for us, I would be curious if you reset the ARC size back to default and disabled swap entirely, if that also ran stable for you. We are looking at different interactions and seeing that when swap is disabled, ARC does the right thing and will shrink as needed. (As it should). But with swap present, something is too aggressively pushing pages into swap, even when there is still plenty of free memory to go around.
Have been testing this with zfs_arc_max=0 & zfs_arc_sys_free=0 which I believe are the defaults. ARC does seem to shrink as needed (when testing with less than 10GiB free and running head -c 10G /dev/zero | tail). I’m running under an intensive workload so will keep ARC as is and update if anything goes kaboom
I’ve been watching this thread with interest. I too have had similar issues with slowness of the UI and when using an SSH terminal among others. I installed the nightly version of Dragonfish-24.04.0-MASTER-20240507-013907 hoping that it would fix my problems with the serious lag that I had been experiencing in my workloads. For the last 24 hours or so this issue has not returned for me and the performance is the same as Cobia 23.10.2. I will say that for both the release version 24.04.0 and this nightly, I DO have the ‘install-dev-tools’ developer mode enabled which disqualifies me from troubleshooting or helping here. In short, for me the slowness issues seems to have been fixed in the latest nightly build. I’d be happy to help troubleshoot further and share here if necessary.
Sure, have disabled the 50% ARC limit on my SCALE system. If you can confirm the correct way to disable swap entirely (if it’s not this post) I can reboot the system afterwards and test for another day or two.
Have been writing to disk for the last 6 hours with swap disabled, didn’t hit an OOM condition, and looks like it has been resizing itself properly which is great. No sparks or explosions to speak of.
I just tested this and it doesn’t look to disable swap after a reboot (which makes sense as I believe changing this only affects new disks, correct me if I’m wrong!), I’d just run swapoff -a as an init script.
Hmmm, I have been experiencing some puzzling issues with tdarr, but given I’m new to TrueNAS thought it might have been a Truenas thing I just hadn’t worked out yet.
My setup is such that I have my main truenas box with the files to be transcoded, which hosts a cache disk and then a separate box running opensuse has another 4 transcoding nodes, which also transcode to that cache disk connected by SMB / NFS. I have been getting random transcode failures with not much to go on in the tdarr logs. I moved from SMB to NFS to no avail. Repeat attempts at transcoding then succeed for some of the files while others still fail, until the next run which is another lottery.
Reading the above I realise I should have checked the system logs. This issue is extremely repeatable, so if you think this is likely the same bug (how do I check) then happy to help.
I haven’t noticed any GUI issues and I have 96GB RAM. I did notice one VM wouldn’t start with high RAM usage taken up by the new ZFS eats all the RAM design to match TrueNAS core which was annoying.
Indicator would be if you’re seeing an unusually high amount of system swapping with a good amount of free memory available.
Realistically you should be able to ignore that VM warning if the majority of your memory is in use by ARC as it should resize itself as needed, though I’ve found it one of the best ways to reproduce the memory/swap issues mentioned above without a fix applied ;).
If you’re looking to test, try disabling swap as suggested by iX and seeing if that fixes the issue.
After seeing this link, I’ve gone ahead and run the command as well as added it as a post-init script.
I’ve just gone and rebooted my SCALE host, looks to persist ok. Will report back in a couple of days. It’s worth noting that up until this point though, the system has now been running for >2 days entirely without any issues.
After this reboot just now, the ARC limit on my system (previously 50%) will be gone, and this will now be testing only with swap disabled. I’m wondering if at this point iX could just adjust the ZFS RAM behaviour to limit it to 75% instead and call it a day.
After deeper digging into the problem, it looks to me caused not only by increased ARC size, reduction which according to some people may not fix the problem, but also by Linux kernel update to 6.6, which enabled previously disabled Multi-Gen LRU code, written in a way that assumes that memory can not be significantly used by anything other than page cache (which does not include ZFS). My early tests show that disabling it as it was in Cobia with echo n >/sys/kernel/mm/lru_gen/enabled may fix the problem without disabling swap.