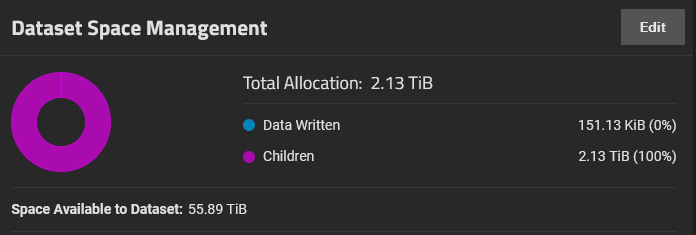
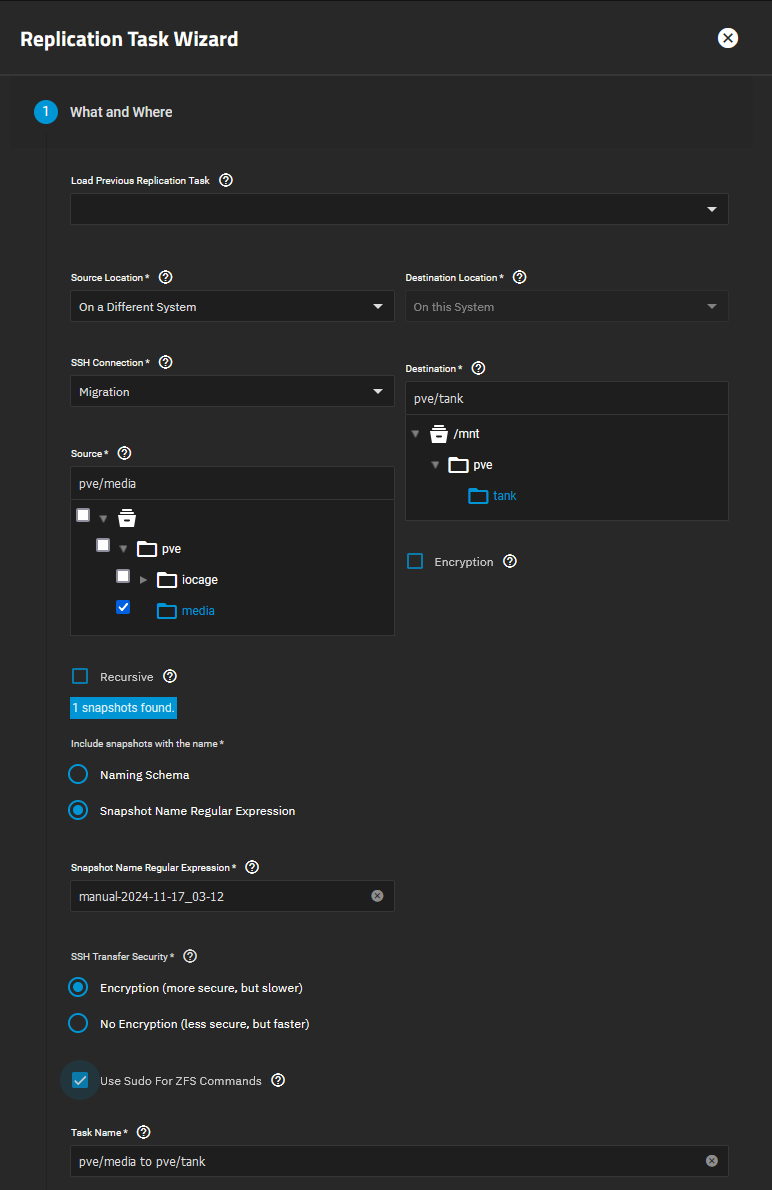
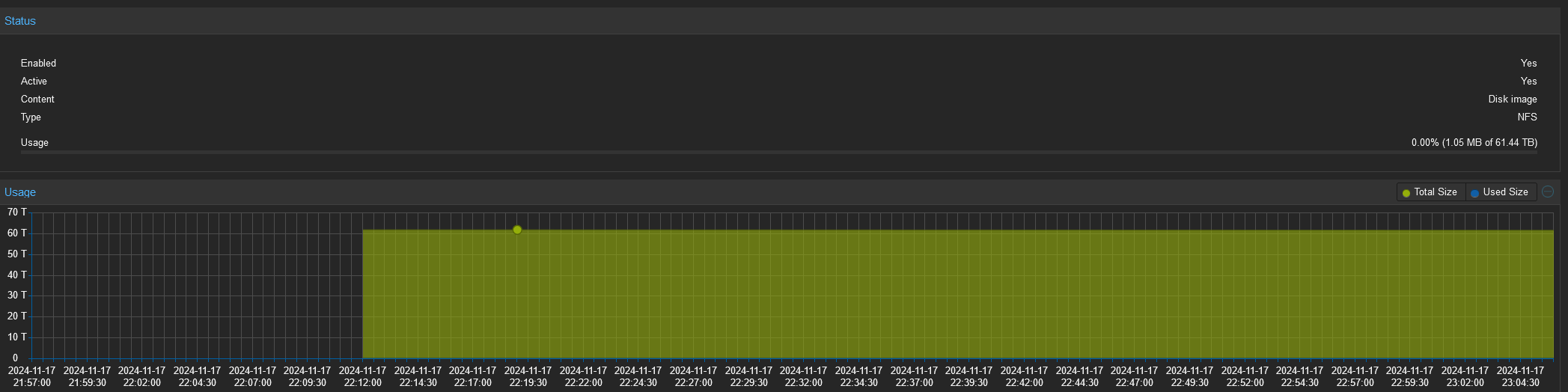
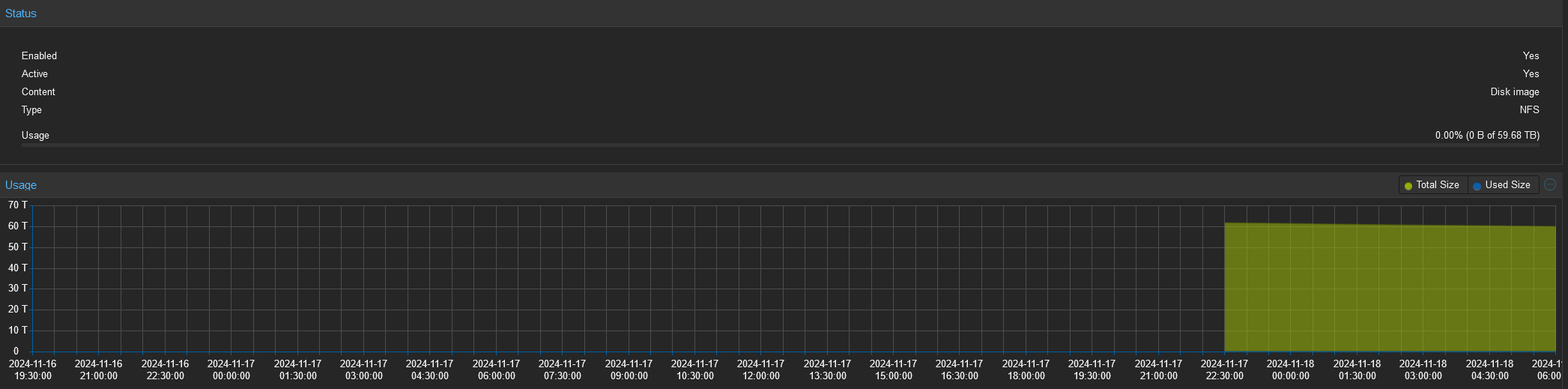
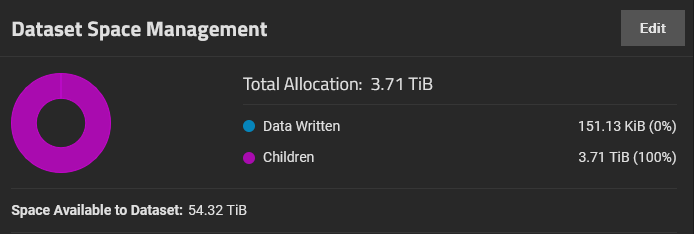
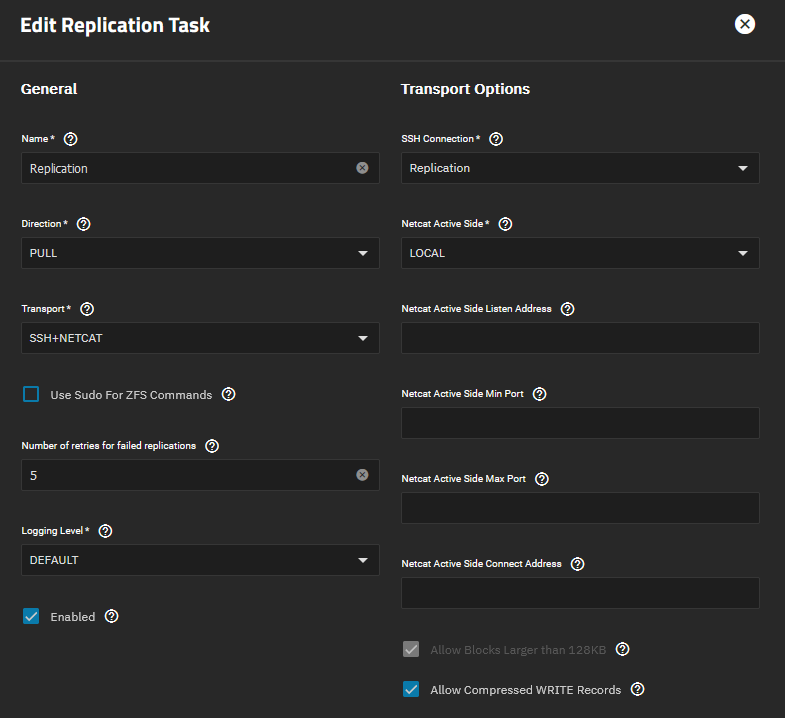
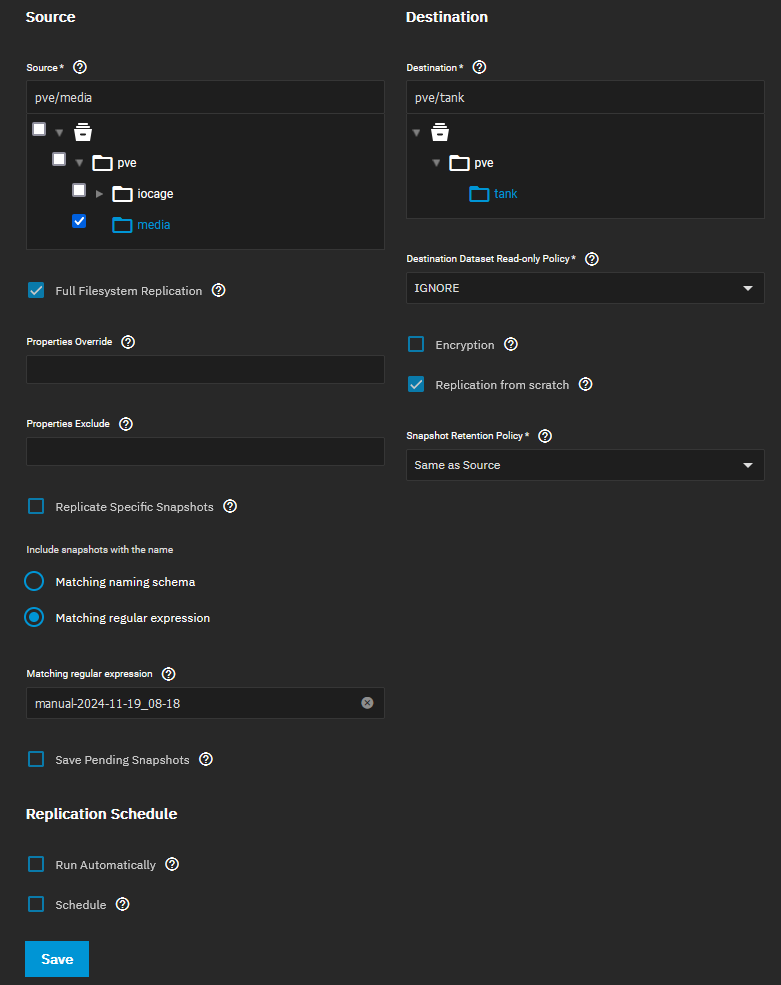
Another issue I am encountering during replication is the “[EFAULT] Failed retreiving GROUP quotas for tank” error I get whenever I access the Dataset section on TrueNAS. This does not happen when no replication is running. Here are the logs:
concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/plugins/zfs_/dataset_quota.py", line 76, in get_quota
with libzfs.ZFS() as zfs:
File "libzfs.pyx", line 534, in libzfs.ZFS.__exit__
File "/usr/lib/python3/dist-packages/middlewared/plugins/zfs_/dataset_quota.py", line 78, in get_quota
quotas = resource.userspace(quota_props)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "libzfs.pyx", line 3800, in libzfs.ZFSResource.userspace
libzfs.ZFSException: cannot get used/quota for tank: dataset is busy
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.11/concurrent/futures/process.py", line 256, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 112, in main_worker
res = MIDDLEWARE._run(*call_args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 46, in _run
return self._call(name, serviceobj, methodobj, args, job=job)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 34, in _call
with Client(f'ws+unix://{MIDDLEWARE_RUN_DIR}/middlewared-internal.sock', py_exceptions=True) as c:
File "/usr/lib/python3/dist-packages/middlewared/worker.py", line 40, in _call
return methodobj(*params)
^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/zfs_/dataset_quota.py", line 80, in get_quota
raise CallError(f'Failed retreiving {quota_type} quotas for {ds}')
middlewared.service_exception.CallError: [EFAULT] Failed retreiving GROUP quotas for tank
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 208, in call_method
result = await self.middleware.call_with_audit(message['method'], serviceobj, methodobj, params, self)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1526, in call_with_audit
result = await self._call(method, serviceobj, methodobj, params, app=app,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1457, in _call
return await methodobj(*prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 179, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/pool_/dataset_quota.py", line 48, in get_quota
quota_list = await self.middleware.call(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1626, in call
return await self._call(
^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1465, in _call
return await self._call_worker(name, *prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1471, in _call_worker
return await self.run_in_proc(main_worker, name, args, job)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1377, in run_in_proc
return await self.run_in_executor(self.__procpool, method, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1361, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
middlewared.service_exception.CallError: [EFAULT] Failed retreiving GROUP quotas for tank