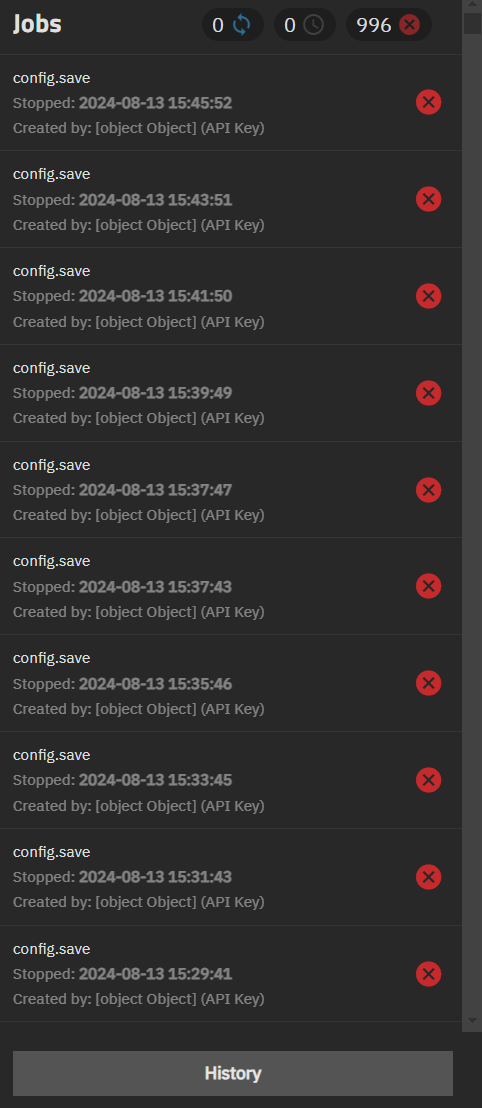
Three days ago, I migrated my TrueNAS Core 13.0-U6.2 to TrueNAS Scale Dragonfish-24.04.2. It went fine, I had a lot of help of some of the fine people here in the forum. Everything seems to be working ok, but I get some error messages in the Jobs tab. I did have some cron jobs setup in Core, and they´re still there, but it seems they can´t run anymore. They were all setup to run with the root user Running them manually works, though, it says the job runs succesfully. But the errors keep happening. So I disabled all the jobs. I still get errors, but only this one, repeatedly:
One thing I can think of is that I still use my old root account from Core. I know I am supposed to replace that witha a new admin account. Could that have something to do with this? Any hints on how I should proceed? Very new to Scale, so I am still learning.
Aside from the differences between SCALE and CORE (ie BSD/Linux) and some scripts needing to be updated to work, one of the biggest differences is that Dragonfish locks down the boot-pool a lot more.
This sometimes causes issues with scripts
Anyway, the point is, you need to work out which cronjob needs updating… and then make the necessary updates to make it work right.
Many community maintained scripts have already been updated, so it may just be a matter of some searching etc… but you should be able to work out which jobs are causing issues by setting different times etc for when they run… or just looking at your email, which should have the failed cron runs captured.
Maybe verify that your email notifications are working (there’s a test button)
That´s interesting. I do have the server monitored by my own TrueCommand instance. I don´t have an API key for that in TrueNAS though, it is connected from the other end. Meaning I have the API key for TrueNAS registered in TrueCommand.
I did find a key in TrueNAS though, probably from when I was learning to set up TrueCommand. I deleted that. It´s been a whie now, but the same error keeps happening. Is there something I wiuld have to do to make it stop? Or could be something else entirely?
Maybe check for TrueCommand updates. TC creates an API key on the TrueNAS server when it is configured to monitor it and uses the API key for authentication to TrueNAS.
I upgraded TrueCommand (3.0.1 → 3.0.2), deleted the API key in TrueNAS, and deleted the TrueNAS server in TrueCommand.
Then, I added a new API key in TrueNAS for TrueCommand, and added the server in TrueCommand again, using the new API key. It´s only been a few minutes, but the messages about config.save seem to have stopped. I will leave it overnight and check it again in the morning.