Hello everyone, I am new here so please be patient with me. I have read a lot of guides and TrueNAS forum posts for solutions but I still could not manage to set up my GPU passthrough to my VMs.
Before getting into detail, here is my setup:
Mobo: ASUS P8B75-V (with latest bios)
CPU: Intel i7 2600
RAM: (4x) 4GB 1333Mhz DDR3 (Total 16GB)
Storage:
-SanDisk 128GB SATA SSD
-(3x) Seagate Constellation ES.3 ST2000NM0033 2TB 7200 RPM 128MB Cache
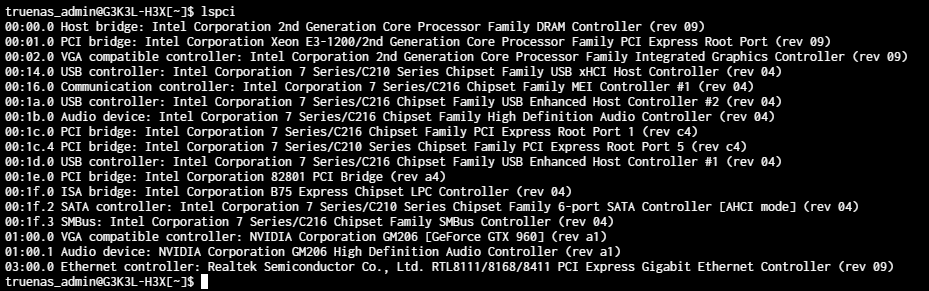
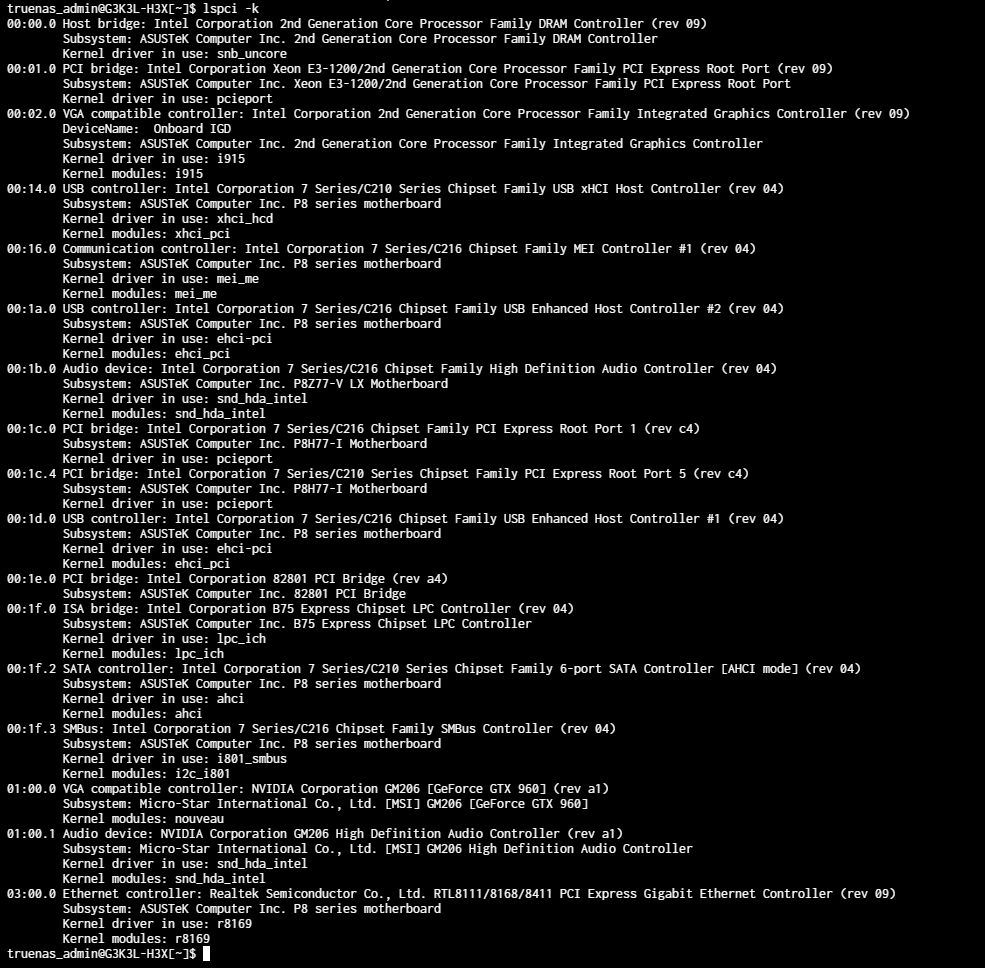
GPU: Nvidia GTX 960 MSI 4GB gaming
PSU: Thermaltake Smart 500W
So, I set up my server using HexOS without a GPU and now getting more familiar (or trying to) with TrueNAS Scale. I have setup Immich and Plex and have no issues with them so far. Then recently I upgraded my mobo to the one that is mentioned above and tried to add my GTX960. I updated the BIOS to the most recent available version. And after trying many things for hours and hours I realised 2 things.
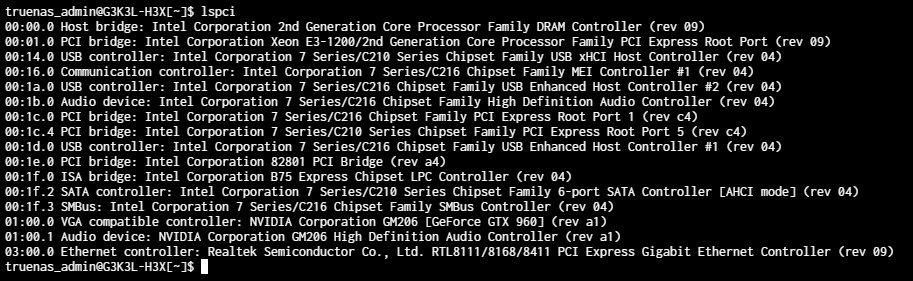
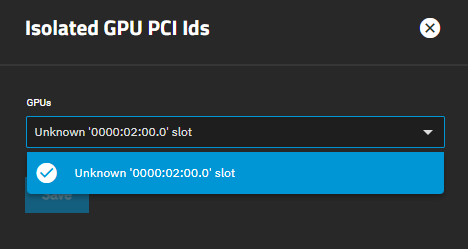
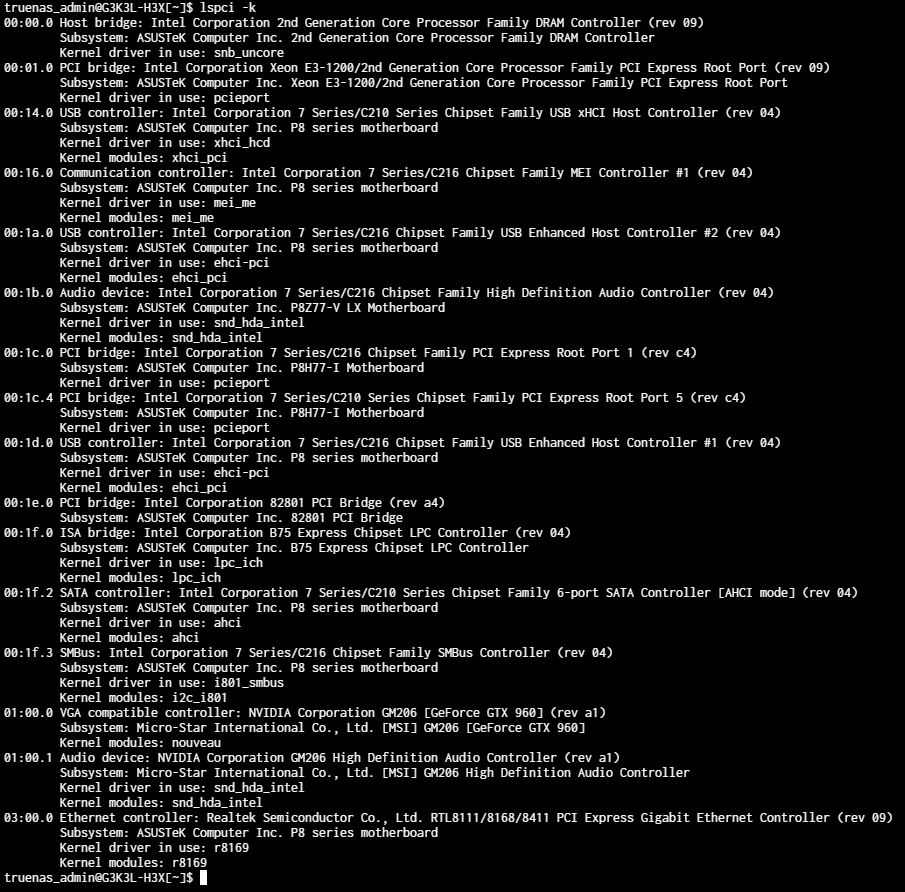
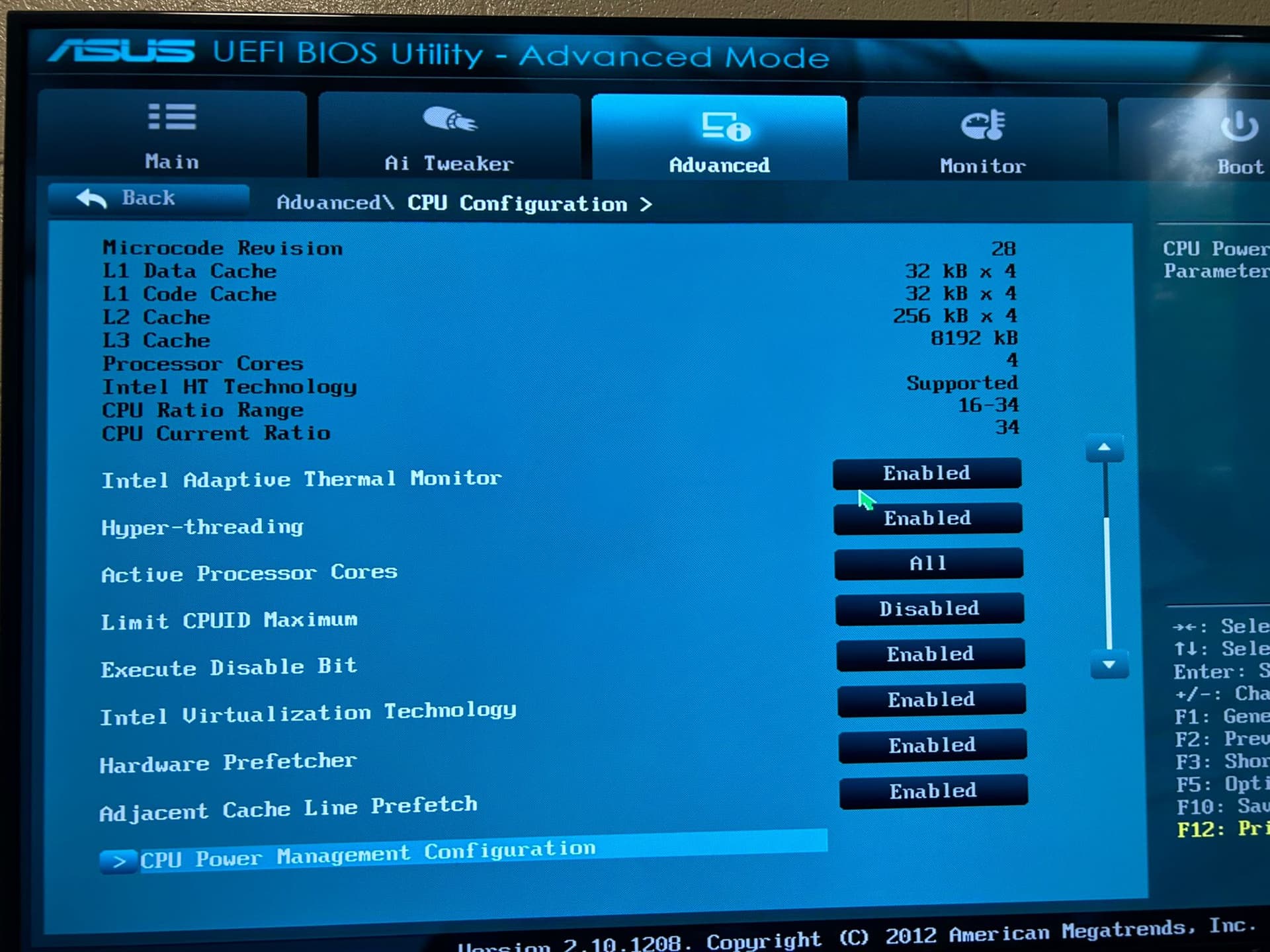
First of all even though my CPU has a built in iGPU (and it is selected as the main display device) if I plug in a dGPU into the first PCIe slot, it is not recognized in the advanced settings menu for GPU isolation UI (dropdown) eventhough I can go to shell and check nvidia-smi and see it recognized) so I don’t really know what is the deal with that.
The second thing is if I move the GPU to the secondary PCIe slot, it becomes visible on the dropdown under GPU isolation and I can select it. After that I go to my already created Windows VM and add it there as PCI device (2 of them one as VGA output it says and one as audio device) and then if I try to launch that VM it fails. I tried so many things I don’t even know where to start to mention.
Ideally it would be nice to figure out why the first PCIe is not even showing for isolation but honestly I am not planning to add a 2nd PCIe device to this machine anytime soon so we can skip that as well. I would really appreciate it if someone can help me with the problem to launch the VM when it is isolated and added to the VM.
Here is the error I get when I try to launch the VM with the GPU attached to the VM:
[EFAULT] internal error: qemu unexpectedly closed the monitor: 2025-07-30T17:54:18.723358Z qemu-system-x86_64: -device {"driver":"vfio-pci","host":"0000:02:00.0","id":"hostdev0","bus":"pci.0","addr":"0x7"}: VFIO_MAP_DMA failed: Bad address 2025-07-30T17:54:18.761342Z qemu-system-x86_64: -device {"driver":"vfio-pci","host":"0000:02:00.0","id":"hostdev0","bus":"pci.0","addr":"0x7"}: vfio 0000:02:00.0: failed to setup container for group 12: memory listener initialization failed: Region pc.ram: vfio_dma_map(0x5560bb4135d0, 0x100000000, 0x1c0000000, 0x7fbe23600000) = -2 (No such file or directory)
More info… shows me this:
Error: Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/plugins/vm/supervisor/supervisor.py", line 189, in start
if self.domain.create() < 0:
^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/libvirt.py", line 1373, in create
raise libvirtError('virDomainCreate() failed')
libvirt.libvirtError: internal error: qemu unexpectedly closed the monitor: 2025-07-30T17:54:18.723358Z qemu-system-x86_64: -device {"driver":"vfio-pci","host":"0000:02:00.0","id":"hostdev0","bus":"pci.0","addr":"0x7"}: VFIO_MAP_DMA failed: Bad address
2025-07-30T17:54:18.761342Z qemu-system-x86_64: -device {"driver":"vfio-pci","host":"0000:02:00.0","id":"hostdev0","bus":"pci.0","addr":"0x7"}: vfio 0000:02:00.0: failed to setup container for group 12: memory listener initialization failed: Region pc.ram: vfio_dma_map(0x5560bb4135d0, 0x100000000, 0x1c0000000, 0x7fbe23600000) = -2 (No such file or directory)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 211, in call_method
result = await self.middleware.call_with_audit(message['method'], serviceobj, methodobj, params, self)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1529, in call_with_audit
result = await self._call(method, serviceobj, methodobj, params, app=app,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1460, in _call
return await methodobj(*prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 179, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 49, in nf
res = await f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/vm/vm_lifecycle.py", line 58, in start
await self.middleware.run_in_thread(self._start, vm['name'])
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1367, in run_in_thread
return await self.run_in_executor(io_thread_pool_executor, method, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1364, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/vm/vm_supervisor.py", line 68, in _start
self.vms[vm_name].start(vm_data=self._vm_from_name(vm_name))
File "/usr/lib/python3/dist-packages/middlewared/plugins/vm/supervisor/supervisor.py", line 198, in start
raise CallError('\n'.join(errors))
middlewared.service_exception.CallError: [EFAULT] internal error: qemu unexpectedly closed the monitor: 2025-07-30T17:54:18.723358Z qemu-system-x86_64: -device {"driver":"vfio-pci","host":"0000:02:00.0","id":"hostdev0","bus":"pci.0","addr":"0x7"}: VFIO_MAP_DMA failed: Bad address
2025-07-30T17:54:18.761342Z qemu-system-x86_64: -device {"driver":"vfio-pci","host":"0000:02:00.0","id":"hostdev0","bus":"pci.0","addr":"0x7"}: vfio 0000:02:00.0: failed to setup container for group 12: memory listener initialization failed: Region pc.ram: vfio_dma_map(0x5560bb4135d0, 0x100000000, 0x1c0000000, 0x7fbe23600000) = -2 (No such file or directory)
Note: If I de-attach the GPU from the VM (regardless of the GPU physically installed or not), I can launch the VM without any issues and can connect to it through the SPICE interface
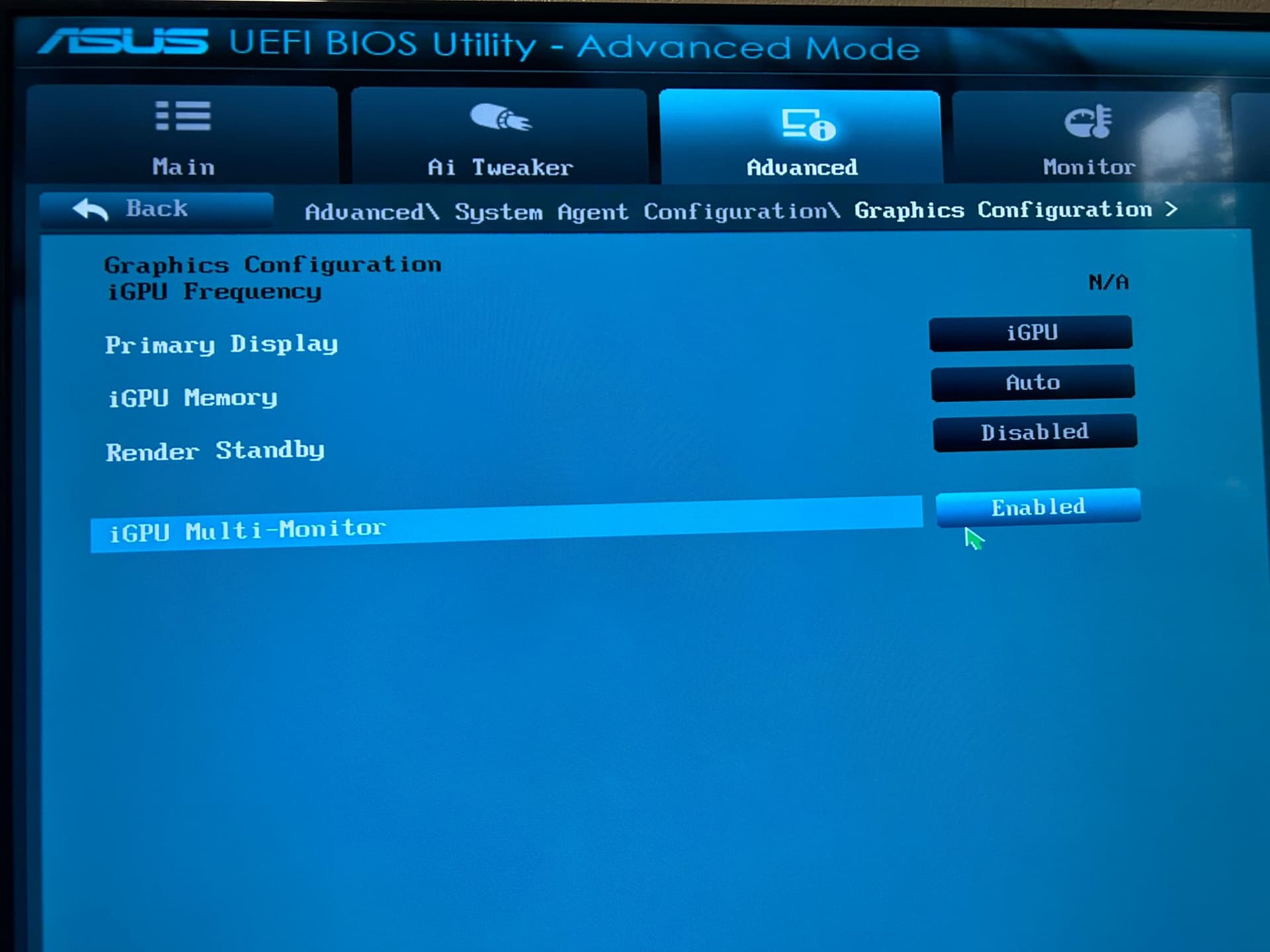
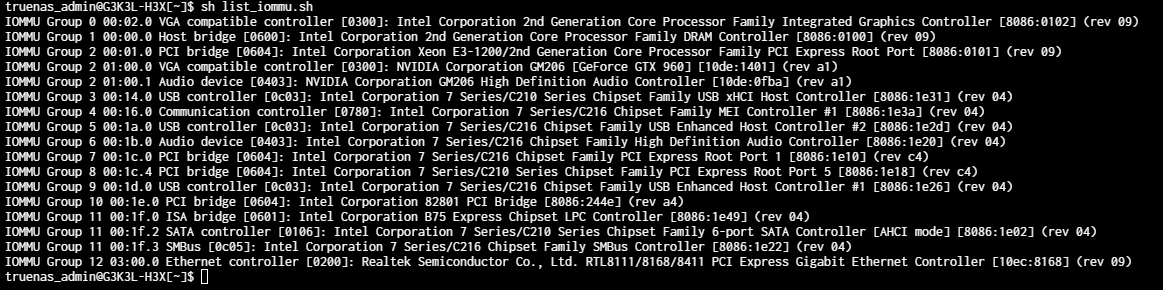
Note 2: There is no IOMMU setting on the BIOS but Virtualisation is on and I don’t know what other settings should I be changing or if it is even related to that (the mobo is pretty old, I built this system just because I had most parts lying around, trying not to spend too much on it if possible) - (The mobo upgrade was to get a mobo that can allow me to put the GPU in as the old one was hitting the SATA ports and not going in)
Here is a screenshot of the devices when I add the GPU:
Thank you so much for your help in advance