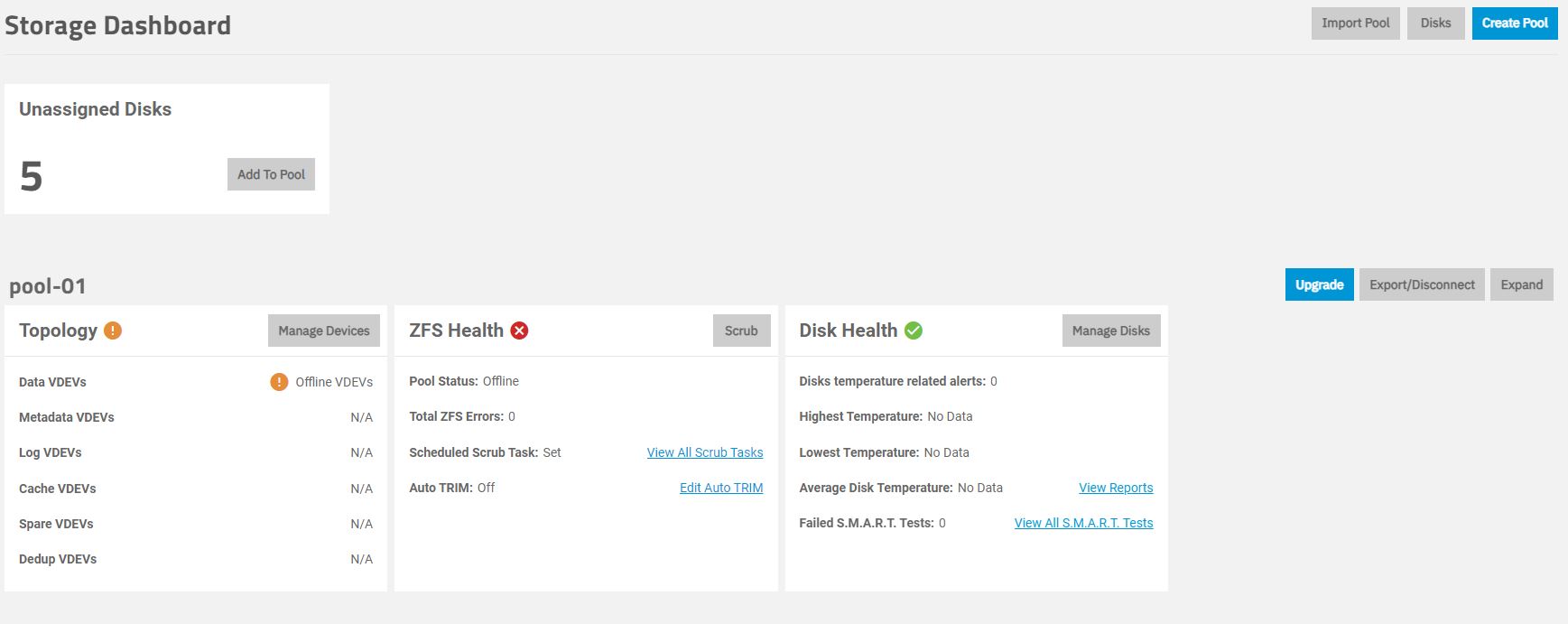
I have a TrueNas Scale installation that I set up about a month ago. Recently I got an alert that my pool was degraded. When I was able to get back and check it 2 of the disks were showing as FAULTED, then another came up as FAULTED. I restarted the system and then the pool was not showing at all, with the drives showing up as unassigned drives on the storage dashboard.
OS: TrueNAS-SCALE-24.04.2
CPU: i5-6600K
Memory: 16GB DDR4
System Disk: 500GB SATA SSD (onboard controller)
Pool: 5x Seagate IronWolf Pro 16TB (ST16000NT001) - RAIDZ1
Storage Controller: LSI 9300-16i )IT mode)
Short SMART test on all drives (before failure) showed no issues.
Can I recover my pool / data? I have included some of the logs from when the issue appears to have started. My best guess is that there is an issue with the HBA, but I am hoping I can get some advice and guidance before trying anything, I know that if there is a chance of getting my data back - it relies on me not doing anything silly now.
I have another NAS with the same HBA in it that I can borrow if needed.
If anyone can provide any insight or assistance in recovering my situation it would be very much appreciated!!
Sep 28 05:08:15 nas-01 kernel: pcieport 0000:00:1b.4: AER: Corrected error message received from 0000:00:1b.4
Sep 28 05:08:15 nas-01 kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID)
Sep 28 05:08:15 nas-01 kernel: pcieport 0000:00:1b.4: device [8086:a2eb] error status/mask=00000001/00002000
Sep 28 05:08:15 nas-01 kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First)
Sep 28 05:26:43 nas-01 kernel: pcieport 0000:00:1b.4: AER: Corrected error message received from 0000:00:1b.4
Sep 28 05:26:43 nas-01 kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID)
Sep 28 05:26:43 nas-01 kernel: pcieport 0000:00:1b.4: device [8086:a2eb] error status/mask=00000001/00002000
Sep 28 05:26:43 nas-01 kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First)
Sep 28 06:38:16 nas-01 kernel: pcieport 0000:00:1b.4: AER: Corrected error message received from 0000:00:1b.4
Sep 28 06:38:16 nas-01 kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID)
Sep 28 06:38:16 nas-01 kernel: pcieport 0000:00:1b.4: device [8086:a2eb] error status/mask=00000001/00002000
Sep 28 06:38:16 nas-01 kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First)
Sep 28 07:50:31 nas-01 kernel: pcieport 0000:00:1b.4: AER: Corrected error message received from 0000:00:1b.4
Sep 28 07:50:31 nas-01 kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID)
Sep 28 07:50:31 nas-01 kernel: pcieport 0000:00:1b.4: device [8086:a2eb] error status/mask=00000001/00002000
Sep 28 07:50:31 nas-01 kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First)
Sep 28 09:43:06 nas-01 kernel: pcieport 0000:00:1b.4: AER: Corrected error message received from 0000:00:1b.4
Sep 28 09:43:06 nas-01 kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID)
Sep 28 09:43:06 nas-01 kernel: pcieport 0000:00:1b.4: device [8086:a2eb] error status/mask=00000001/00002000
Sep 28 09:43:06 nas-01 kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First)
Sep 28 15:08:32 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 15:08:32 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 15:08:32 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 15:08:32 nas-01 kernel: sd 0:0:4:0: [sde] tag#4157 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=2s
Sep 28 15:08:32 nas-01 kernel: sd 0:0:4:0: [sde] tag#4157 Sense Key : Medium Error [current]
Sep 28 15:08:32 nas-01 kernel: sd 0:0:4:0: [sde] tag#4157 Add. Sense: Unrecovered read error
Sep 28 15:08:32 nas-01 kernel: sd 0:0:4:0: [sde] tag#4157 CDB: Read(16) 88 00 00 00 00 00 07 f6 82 b8 00 00 00 40 00 00
Sep 28 15:08:32 nas-01 kernel: zio pool=pool-01 vdev=/dev/disk/by-partuuid/e6193543-b551-4653-816b-f7c33d94df73 error=61 type=1 offset=68398968832 size=32768 flags=1573248
Sep 28 17:32:55 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:32:55 nas-01 kernel: sd 0:0:4:0: [sde] tag#4626 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=2s
Sep 28 17:32:55 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:32:55 nas-01 kernel: sd 0:0:4:0: [sde] tag#4626 Sense Key : Medium Error [current]
Sep 28 17:32:55 nas-01 kernel: sd 0:0:4:0: [sde] tag#4626 Add. Sense: Unrecovered read error
Sep 28 17:32:55 nas-01 kernel: sd 0:0:4:0: [sde] tag#4626 CDB: Read(16) 88 00 00 00 00 00 0b b8 eb 08 00 00 02 00 00 00
Sep 28 17:32:55 nas-01 kernel: zio pool=pool-01 vdev=/dev/disk/by-partuuid/e6193543-b551-4653-816b-f7c33d94df73 error=61 type=1 offset=100692004864 size=262144 flags=1074267296
Sep 28 17:34:11 nas-01 kernel: Adding 16777212k swap on /dev/mapper/sdf4. Priority:-2 extents:1 across:16777212k SS
Sep 28 17:35:14 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:35:14 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:35:14 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:35:14 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:35:14 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4694 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=4s
Sep 28 17:35:14 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4694 Sense Key : Medium Error [current]
Sep 28 17:35:14 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4694 Add. Sense: Unrecovered read error
Sep 28 17:35:14 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4694 CDB: Read(16) 88 00 00 00 00 00 00 6e b3 b0 00 00 07 30 00 00
Sep 28 17:35:17 nas-01 kernel: zio pool=pool-01 vdev=/dev/disk/by-partuuid/89b5831d-d307-4e01-9a02-f3b1835c2e5f error=61 type=1 offset=3712442368 size=1048576 flags=1074267312
Sep 28 17:35:25 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:35:25 nas-01 kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000)
Sep 28 17:35:25 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4674 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=2s
Sep 28 17:35:25 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4674 Sense Key : Medium Error [current]
Sep 28 17:35:25 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4674 Add. Sense: Unrecovered read error
Sep 28 17:35:25 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4674 CDB: Read(16) 88 00 00 00 00 00 00 6e b9 f0 00 00 00 40 00 00
Sep 28 17:35:25 nas-01 kernel: zio pool=pool-01 vdev=/dev/disk/by-partuuid/89b5831d-d307-4e01-9a02-f3b1835c2e5f error=61 type=1 offset=3713261568 size=32768 flags=1605809
Sep 28 17:35:27 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4709 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=2s
Sep 28 17:35:27 nas-01 kernel: sd 0:0:0:0: [sdb] tag#4709 Sense Key : Medium Error [current]
** many similar entries removed **
Sep 28 17:50:20 nas-01 kernel: sd 0:0:0:0: device_block, handle(0x0009)
Sep 28 17:50:22 nas-01 kernel: sd 0:0:0:0: device_unblock and setting to running, handle(0x0009)
Sep 28 17:50:22 nas-01 kernel: sd 0:0:0:0: [sdb] Synchronizing SCSI cache
Sep 28 17:50:22 nas-01 kernel: sd 0:0:0:0: [sdb] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK
Sep 28 17:50:22 nas-01 kernel: mpt3sas_cm0: mpt3sas_transport_port_remove: removed: sas_addr(0x4433221102000000)
Sep 28 17:50:22 nas-01 kernel: mpt3sas_cm0: removing handle(0x0009), sas_addr(0x4433221102000000)
Sep 28 17:50:22 nas-01 kernel: mpt3sas_cm0: enclosure logical id(0x500062b200263780), slot(0)
Sep 28 17:50:22 nas-01 kernel: mpt3sas_cm0: enclosure level(0x0000), connector name( )
Sep 28 17:50:30 nas-01 kernel: Adding 16777212k swap on /dev/mapper/sdf4. Priority:-2 extents:1 across:16777212k SS
Sep 28 17:51:06 nas-01 netdata[1540425]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:51:29 nas-01 netdata[1540621]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:51:52 nas-01 netdata[1540844]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:52:14 nas-01 netdata[1541090]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:52:37 nas-01 netdata[1541303]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:53:00 nas-01 netdata[1541498]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:53:23 nas-01 netdata[1541705]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:53:33 nas-01 kernel: task:txg_sync state:D stack:0 pid:1458 ppid:2 flags:0x00004000
Sep 28 17:53:33 nas-01 kernel: Call Trace:
Sep 28 17:53:33 nas-01 kernel:
Sep 28 17:53:33 nas-01 kernel: __schedule+0x349/0x950
Sep 28 17:53:33 nas-01 kernel: schedule+0x5b/0xa0
Sep 28 17:53:33 nas-01 kernel: schedule_timeout+0x98/0x160
Sep 28 17:53:33 nas-01 kernel: ? __pfx_process_timeout+0x10/0x10
Sep 28 17:53:33 nas-01 kernel: io_schedule_timeout+0x50/0x80
Sep 28 17:53:33 nas-01 kernel: __cv_timedwait_common+0x12a/0x160 [spl]
Sep 28 17:53:33 nas-01 kernel: ? __pfx_autoremove_wake_function+0x10/0x10
Sep 28 17:53:33 nas-01 kernel: __cv_timedwait_io+0x19/0x20 [spl]
Sep 28 17:53:33 nas-01 kernel: zio_wait+0x10f/0x220 [zfs]
Sep 28 17:53:33 nas-01 kernel: dsl_pool_sync_mos+0x37/0xa0 [zfs]
Sep 28 17:53:33 nas-01 kernel: dsl_pool_sync+0x3b9/0x410 [zfs]
Sep 28 17:53:33 nas-01 kernel: spa_sync_iterate_to_convergence+0xdc/0x200 [zfs]
Sep 28 17:53:33 nas-01 kernel: spa_sync+0x30a/0x5e0 [zfs]
Sep 28 17:53:33 nas-01 kernel: txg_sync_thread+0x1ec/0x270 [zfs]
Sep 28 17:53:33 nas-01 kernel: ? __pfx_txg_sync_thread+0x10/0x10 [zfs]
Sep 28 17:53:33 nas-01 kernel: ? __pfx_thread_generic_wrapper+0x10/0x10 [spl]
Sep 28 17:53:33 nas-01 kernel: thread_generic_wrapper+0x5b/0x70 [spl]
Sep 28 17:53:33 nas-01 kernel: kthread+0xe5/0x120
Sep 28 17:53:33 nas-01 kernel: ? __pfx_kthread+0x10/0x10
Sep 28 17:53:33 nas-01 kernel: ret_from_fork+0x31/0x50
Sep 28 17:53:33 nas-01 kernel: ? __pfx_kthread+0x10/0x10
Sep 28 17:53:33 nas-01 kernel: ret_from_fork_asm+0x1b/0x30
Sep 28 17:53:33 nas-01 kernel:
** many similar entries removed **
Sep 28 17:53:33 nas-01 kernel: Future hung task reports are suppressed, see sysctl kernel.hung_task_warnings
Sep 28 17:53:43 nas-01 kernel: mpt3sas_cm0: handle(0x9) sas_address(0x4433221102000000) port_type(0x1)
Sep 28 17:53:45 nas-01 netdata[1541965]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:53:51 nas-01 kernel: mpt3sas_cm0: log_info(0x31111000): originator(PL), code(0x11), sub_code(0x1000)
Sep 28 17:53:59 nas-01 kernel: mpt3sas_cm0: log_info(0x31111000): originator(PL), code(0x11), sub_code(0x1000)
Sep 28 17:54:08 nas-01 netdata[1542174]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:54:08 nas-01 kernel: mpt3sas_cm0: log_info(0x31111000): originator(PL), code(0x11), sub_code(0x1000)
Sep 28 17:54:29 nas-01 kernel: scsi 0:0:5:0: attempting task abort!scmd(0x00000000e6c941da), outstanding for 45800 ms & timeout 20000 ms
Sep 28 17:54:29 nas-01 kernel: scsi 0:0:5:0: tag#4687 CDB: Inquiry 12 00 00 00 24 00
Sep 28 17:54:29 nas-01 kernel: scsi target0:0:5: handle(0x0009), sas_address(0x4433221102000000), phy(2)
Sep 28 17:54:29 nas-01 kernel: scsi target0:0:5: enclosure logical id(0x500062b200263780), slot(0)
Sep 28 17:54:29 nas-01 kernel: scsi target0:0:5: enclosure level(0x0000), connector name( )
Sep 28 17:54:31 nas-01 netdata[1542374]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.
Sep 28 17:54:33 nas-01 kernel: scsi 0:0:5:0: task abort: SUCCESS scmd(0x00000000e6c941da)
Sep 28 17:54:33 nas-01 kernel: end_device-0:5: add: handle(0x0009), sas_addr(0x4433221102000000)
Sep 28 17:54:33 nas-01 kernel: mpt3sas_cm0: mpt3sas_transport_port_remove: removed: sas_addr(0x4433221102000000)
Sep 28 17:54:33 nas-01 kernel: mpt3sas_cm0: removing handle(0x0009), sas_addr(0x4433221102000000)
Sep 28 17:54:33 nas-01 kernel: mpt3sas_cm0: enclosure logical id(0x500062b200263780), slot(0)
Sep 28 17:54:33 nas-01 kernel: mpt3sas_cm0: enclosure level(0x0000), connector name( )
Sep 28 17:54:54 nas-01 netdata[1542578]: CONFIG: cannot load cloud config ‘/var/lib/netdata/cloud.d/cloud.conf’. Running with internal defaults.

