I am experiencing uneven and generally poorer than expected performance on one of my three main pools. I recently upgraded to SCALE after being on CORE for several years. Unfortunately, I’m not sure if the issue was there without my noticing before the upgrade. I know it certainly wasn’t there always, but I didn’t test the performance of each pool just before upgrading, only after.
Over SMB, I am getting uneven read speeding averaging 160MB/s from this pool, which is 25%-35% of what I’m getting from my other pools, and I can see the transfer speed fluctuates throughout, also unlike the other pools, where it’s a flat speed. See:
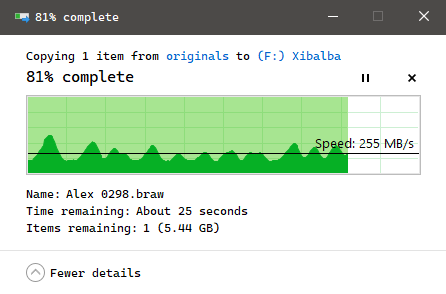
The problematic pool in question is called “Renenutet”. It is a 5-wide Z1 pool of 18GB drives.
- 2 of the drives are Seagate Exos x18 (ST18000NM000J-2TV103) – sde, sdn
- 3 of the drives are WD Ultrastar DC HC550 (WDC_WUH721818ALE6L4) – sdo, sdp, sdq
- all of the drives are set to 4kn (checked in smartctl)
I am a video editor and this pool holds my datasets for video footage, often working with 6K RAW files of 50GB+ each. The datasets are shared via SMB with my desktop Win10 Pro client, all connected over 10gbe. The same issue exists with both the datasets I have on this pool. I know the 10gbe connection works at close to full saturation because when working with files in the TrueNAS cache, I am able to get 900MB/s+ speeds.
And with files not in the cache but in my other two pools, I get the following:
- 5-wide Z1 pool of 20GB drives: 650MB/s (all WD Ultrastar DC HC 560)
- 4-wide Z1 pool of 16GB drives: 400MB/s (all Seagate Exos X16)
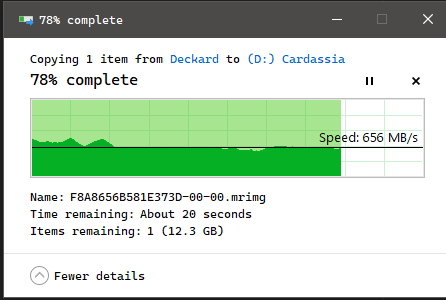
With both the above properly functioning pools, the transfer speed is also very stable. With the problematic pool I can see it constantly going up and down. None of these pools have extra caches/slog/special attached – they’re just Z1 rust pools. All drives in all three pools are attached to the same LSI 9400-16i HBA. Both the good pools actually have higher used capacity than the bad one – one of them is actually in the red, at 87% capacity right now. The slow pool is at 61% capacity.
I have followed clear instructions here to perform iostat checks using non-cached fio data on each pool: https://klarasystems.com/articles/openzfs-using-zpool-iostat-to-monitor-pool-perfomance-and-health/
It shows that 2 of the 3 WD drives are getting quite a bit fewer reads than the other three drives. Those other 3 drives have higher total_wait than the 2 getting fewer reads, and 1 of the 3 (sde) has much higher total_wait.
basestar% sudo zpool iostat -vly 240 1
[sudo] password for adama:
capacity operations bandwidth total_wait disk_wait syncq_wait asyncq_wait scrub trim rebuild
pool alloc free read write read write read write read write read write read write wait wait wait
-------------------------------------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
Renenutet 49.9T 31.9T 1.22K 0 317M 0 53ms - 31ms - 24ms - 4ms - - - -
raidz1-0 49.9T 31.9T 1.22K 0 317M 0 53ms - 31ms - 24ms - 4ms - - - -
sde2 - - 291 0 74.8M 0 106ms - 41ms - 71ms - 8ms - - - -
sdn2 - - 287 0 73.5M 0 57ms - 36ms - 21ms - 6ms - - - -
sdo2 - - 283 0 72.1M 0 43ms - 33ms - 10ms - 3ms - - - -
sdp2 - - 189 0 47.5M 0 17ms - 17ms - 25us - 1ms - - - -
sdq2 - - 194 0 48.7M 0 18ms - 18ms - 24us - 1ms - - - -
-------------------------------------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
Thoughts: Is the poor and uneven performance of the problematic pool:
- Just because I have mixed drives within it?
- Just that one or more of those drives is failing/bad?
Please help!