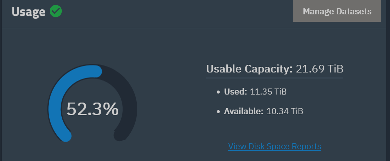
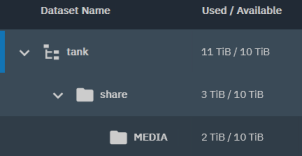
Clearly you have data on the pool that isn’t in the share dataset, about 8 TB of it (your share dataset only has 3 TB, not 5 TB).
Because, unless you’ve set a quota or reservation for the dataset, ZFS is going to report its size as the amount of data it contains + the remaining free space on the pool.
Oh damn! You’re right. I completely missed a directory under /mnt/tank (so outside share) that contains all my proxmox VMs backup… It’s time to reduce the retention!
Thanks for explanation, now is clear. I’ll move my data outside the datasets and delete them as I don’t need them.
Even with reduced retention never put data in the top level dataset of your pool. Always use child datasets for sharing. That’s even in the documentation.
I see. This was a temporary location as I planned to use a separate dataset for it. But then I forgot to do it. That’s why I wasn’t able to identify the pool used space.
Out of curiosity, is there any specific technical reason to not use the top level dataset of the pool? e.g. data integrity or something like that? Other than the abilities like to use separate snapshots/replications and just better data organization