Hi all,
New starter with NASs and Linux in general. I have recently build an old Precision 7910 into a TrueNas SCALE 24.10 server with RAIDZ2 and 5 drives (14tb each) into the Storage Pool, and a mirrored 2tb pool on ssds for apps.
It was all going well and very pleased with myself on getting the server up and running just by using the information found in this great forum and the TrueNas documentation.
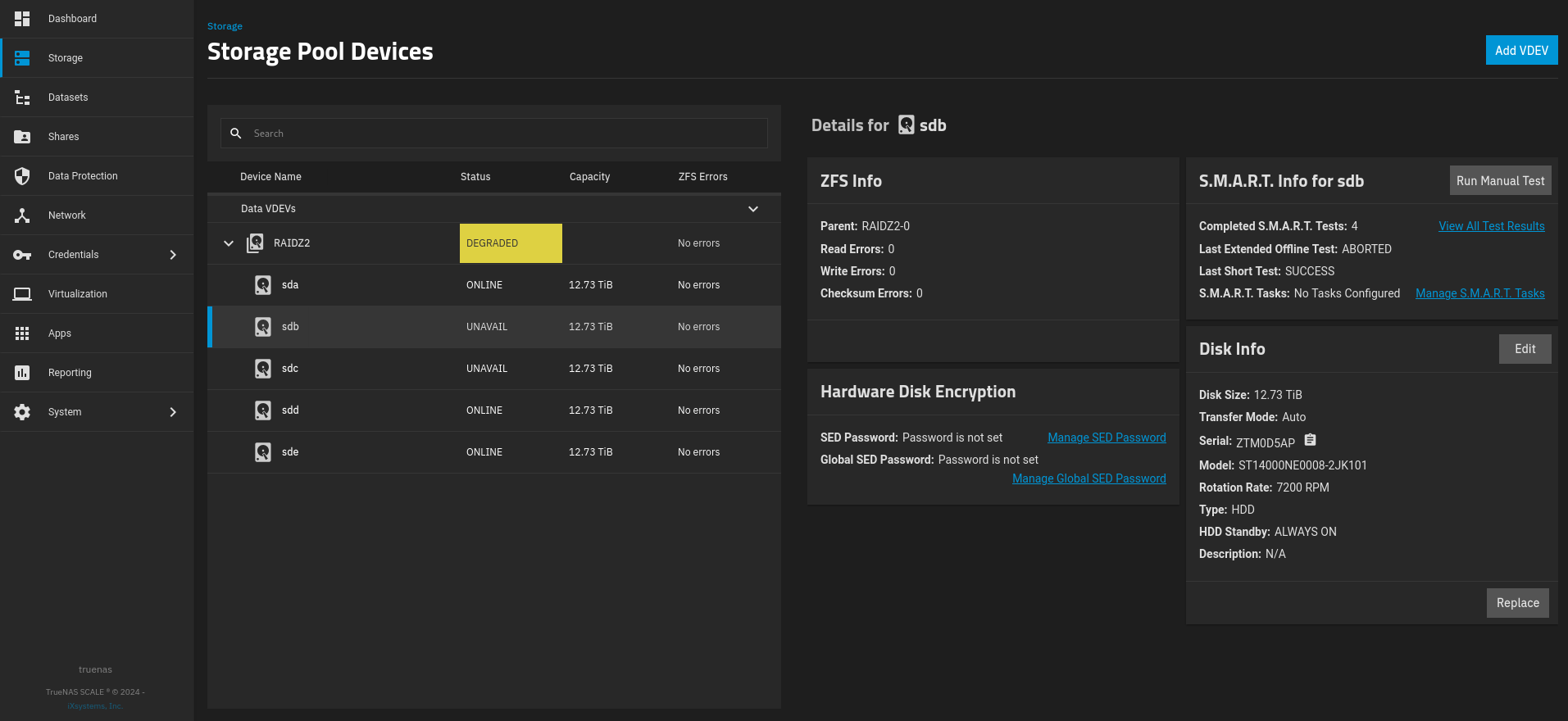
This only lasted until yesterday… While creating a new Windows 10 boot drive (I had removed the ssd pool disks to avoid any mistakes, but forgot the hdds connected), and I stupidly clicked on delete partition on two of the HDDs that form the Storage Pool. When I booted into TrueNas, the Storage Pool shows degraded and sdb and sdc both show unavailable.
I have tried to repair the mistake using shell and parted and changed both devs to zfs and they match the healthy drives, but I am stuck… I can not seem to get the pool to repair the two drives.
I am currently running a scrub, not certain if this will resolve or even help with the issue, and I was wondering if you could help get me out of this pickle i got myself into, just to have a Windows 10 boot drive…
Current Zpool status is as below.
truenas% sudo zpool status -x
[sudo] password for my_user:
pool: Storage Pool
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using ‘zpool replace’.
see: link removed as required by forum
scan: scrub in progress since Fri Jan 10 17:42:51 2025
5.92T / 35.9T scanned at 3.44G/s, 1.26T / 35.9T issued at 753M/s
0B repaired, 3.52% done, 13:24:58 to go
expand: expanded raidz2-0 copied 18.8T in 1 days 01:18:24, on Fri Dec 13 19:18:06 2024
config:
NAME STATE READ WRITE CKSUM
Storage Pool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
6322218737244047899 UNAVAIL 0 0 0 was /dev/sdb
6960868856447592706 UNAVAIL 0 0 0 was /dev/sdc
99b9486b-f8af-464e-8740-4e9f38128df9 ONLINE 0 0 0
0dde2dae-81ad-44c3-b027-6b4145dbef0c ONLINE 0 0 0
b4575789-b449-441c-a1f0-c7c78e06e1b9 ONLINE 0 0 0
Hi neofusion,
Thank you for replying so quickly
I have backups of the files on separate hard drives, so shouldn’t be an issue to restore them. The Storage Pool (made of the 5 rust spinners) is only storing media files for the plex server I set up, so loosing them is not the end of the world. All my sensitive info is in the mirrored ssd pool.
This is the first server I set up, and a backup server is only in the planning stage currently.
Since TrueNAS uses the partition ID to identify what disk is what, when you removed the partitions TrueNAS lost track of the drives.
If you go to Storage, does it say anything about Unassigned Disks?
There may be a way to manually recreate the partitions but that is beyond my abilities.
So instead my process here would be to treat the drives as new, and use the UI to replace the “UNAVAIL” drives with the “new” drives, one at a time. Storage → Manage Devices on the relevant pool, select an UNAVAIL disk and then click Replace.
No unassigned disks in the Storage Dashboard and the it seems to already include them in the pool, just as unavailable status.
I tried to do the Replace step but I do not have any other disks of the same size attached to the server, and the dropdown list is empty.
Something else that I have also noticed is that the Offline option is not there for either of these two drives, but selecting one of the Online drives, the Offline option appears.
ps. I seem to be unable to attach screenshots for some reason.
Given how badly you have stuffed the drives - I don’t think replace will work.
You will need to potentially physically remove the drive, wipe them completely and then put them back.
You should be able to wipe in situ, but it’ll be safer if you remove physically (testing that the pool still works), wipe and return. At that point you should be able to replace a missing disk with a “new” one.
Hi NugentS,
I tried this method using a quick format ntfs in windows but it did not make a difference yesterday. I will however try a full format of these drives as per your suggestion, and then try to put them back in the pool to see if it did the trick.
They are currently at 3% formatting. I will update the thread once I have put them back on the server.
The issue with formatting is that a consumer OS typically only formats a the main partition, leaving other smaller invisible partitions untouched. These residual partitions can then cause issues at a later point.
You want the disk entirely wiped so you need to verify that all the partitions are removed. Follow @NugentS advice and use diskpart to clear them, carefully. Diskpart is like a loaded weapon, don’t point it at anything you’re not willing to kill.
Thank you @NugentS and @neofusion,
I stopped the formatting as advised, and just simply used diskpart in cmd to clean both disks (I made sure to disconnect all the healthy drives first.
I booted back in TrueNas but the disks are still unavailable and the wipe command is still not showing in TrueNas…
What am I missing?
hi @etorix,
thank you, I ran the wipe command sudo dd if=/dev/zero of=/dev/sdb bs=1M count=100 and then followed it for sdc (these are the drives that I am tryintg to force a resilver on) as per your advice, but still no change. I am still not getting the option to resilver these drives.
ok, I have been going around in circles and I still have not been able to make any progress. I am now fairly certain that the reason why I am not seeing the drives as replacements is that they are the same drives that formed the pool.
The thing is that I know the drives are good. What would be the procedure in this case?
I believe I was able to make some progress on this today and it has just started resilvering the drives after they became available in UI to replace.
Steps I took to get it to accept the same drives as replacements.
with @etorix help, I was able to wipe each of the drives as below dd if=/dev/zero of=/dev/sdb bs=1M count=100 dd if=/dev/zero of=/dev/sdc bs=1M count=100
ran lsblk -o name,size,partuuid to get the unique uuid of the drives (sdb and sdc)
then sudo zpool replace “Storage Pool” “old uuid” “new uuid” -f
Shell complained that the new uuid is already part of the pool.
I did a restart of truenas and upon loging back in, i was able to see the drives as available. I then followed the replace process for each and is currently resilvering.
Fingers crossed, all is well.
I will update the thread once is complete.
Thank you for your help @etorix@neofusion@NugentS.