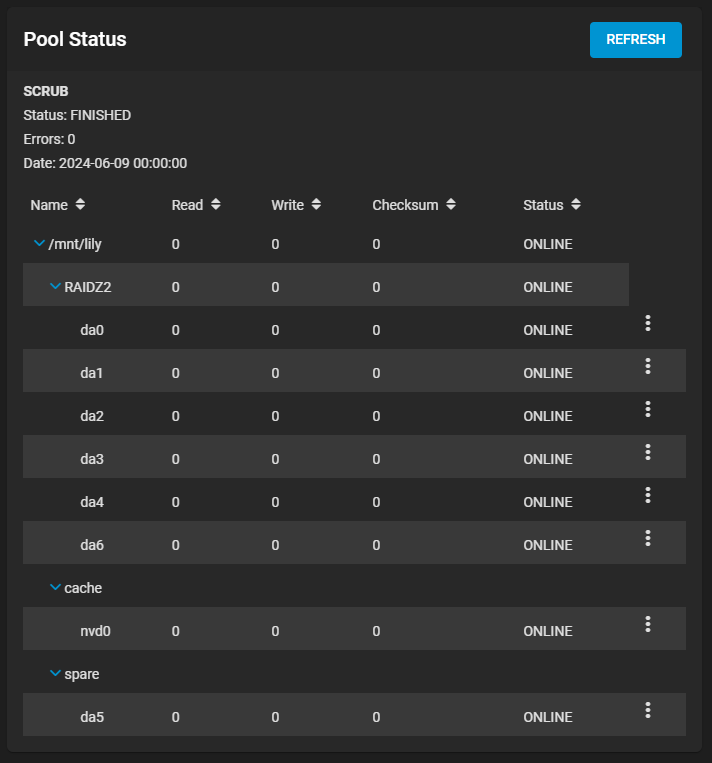
Two of the drives, 05a9fd1d and 0592f189, reported a number of read/write errors and were faulted and removed from the pool automatically last night. The single hotspare was activated. I didn’t capture the output of zpool status but I did get a screenshot of the GUI:

I checked SMART on each of the drives (short and long) and saw no errors. I figured it might be due to the data cables so I did some finagling, ran zpool clear, and rebooted the NAS. I now see the below:
root@truenas[~]# zpool status
pool: boot-pool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p2 ONLINE 0 0 0
ada1p2 ONLINE 0 0 0
errors: No known data errors
pool: lily
state: ONLINE
scan: resilvered 187G in 00:21:21 with 0 errors on Fri Jun 7 11:48:04 2024
config:
NAME STATE READ WRITE CKSUM
lily ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/0581ca01-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
gptid/0599f1d5-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
gptid/05b291f4-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
gptid/05a14fc6-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
gptid/05a9fd1d-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
spare-5 ONLINE 0 0 0
gptid/0592f189-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
gptid/05b9cf80-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
cache
gptid/047d338f-220f-11ef-ba5e-ac1f6b6aa75a ONLINE 0 0 0
spares
gptid/05b9cf80-220f-11ef-ba5e-ac1f6b6aa75a INUSE currently in use
errors: No known data errors
(For cross reference:)
Component Name Serial
ada0p1 gptid/b2c9bf83-2243-11ef-a124-ac1f6b6aa75a N/A
ada1p1 gptid/b2da6853-2243-11ef-a124-ac1f6b6aa75a N/A
da3p1 gptid/054a4c3b-220f-11ef-ba5e-ac1f6b6aa75a N/A
da0p2 gptid/0581ca01-220f-11ef-ba5e-ac1f6b6aa75a ZVT4ZWYV
da1p2 gptid/0599f1d5-220f-11ef-ba5e-ac1f6b6aa75a ZVT4ECV4
da2p2 gptid/05b291f4-220f-11ef-ba5e-ac1f6b6aa75a ZVT6MJNY
da3p2 gptid/05a14fc6-220f-11ef-ba5e-ac1f6b6aa75a ZVT46A6S
da4p2 gptid/05a9fd1d-220f-11ef-ba5e-ac1f6b6aa75a ZVT7CPYG
da5p2 gptid/0592f189-220f-11ef-ba5e-ac1f6b6aa75a ZVT6MJPQ
da6p2 gptid/05b9cf80-220f-11ef-ba5e-ac1f6b6aa75a ZVT7EQ50
nvd0p1 gptid/047d338f-220f-11ef-ba5e-ac1f6b6aa75a N/A
Here’s where I’m confused… The hot spare is still attached, and there are now 7 drives in the RAIDZ2 pool. Yet, my capacity is still as though I have only 6 drives. How do I get all the drives to return to the original state-- that is, having 05b9cf80 go back to being an idle hot spare, and having the 6 drives be regular ONLINE drives as part of the raidz2-0?
Thanks in advance.