Wait… quotas have performance implications?
Yes, unfortunately they do. For a while they don’t, but much like how the performance of a pool can degrade as its utilization nears its capacity, the performance of an individual dataset will degrade as it approaches the limit imposed by any present quota; however, there is something you can do to significantly lower the performance impact of quotas as your datasets fill. Technically, this tweak will also help when nearing pool capacity, but only in part, and there are other good reasons to leave overhead there.
You could simply avoid using quotas entirely, but if you’re like me you enjoy making ample use of them for organization and provisioning.
The good news is that in many cases this impact can be reduced to where it’s nearly negligeable.
The reason why the penalty is so much more significant by default and the mechanics of the resolution are fairly technical, so you may skip down to The Solution if you want a tl;dr, but I suggest you continue reading so you understand the changes you’re making.
The Problem
The mechanisms within ZFS that lead to the performance impact that quotas have are fairly complex, and to a degree outside of the scope of this resource so I won’t go into them too deeply. You just need to be aware of two things:
- ZFS doesn’t necessarily perform requested operations immediately and instead queues them up in transaction groups to be performed at a slightly later time for optimization purposes.
- The amount of data requested to be written by a process in user space is, depending on configuration, often not the amount of space that will actually be consumed on the pool because of various ZFS features and implementation details (i.e. redundancy, deduplication, etc).
Originally, because of the exact implementation of these two mechanisms, it was potentially possible for a transaction group to be processed that required writing more data than was available in free space, whether this be for the entire pool or within a dataset with a quota, which would obviously fail. The OpenZFS dev’s felt strongly that this should never happen, and so a change was merged in 2017 that ensured this, but unfortunately the fix came at the cost of performance [1]. The gist is that as the capacity of a dataset is approached, the size of transaction groups is artificially limited in order to prevent the above scenario from occurring[2]. This essentially means that IO is increasingly throttled.
As stated, this applies to the entire pool as well as datasets with quotas, though pools should never be ran close to capacity for a variety of other reasons, so this tuning really only helps with quotas specifically.
The Nitty Gritty
One of the largest factors in this safety mechanism is how ZFS accounts for scaling the size of a requested write to the actual space required when making transaction groups, and luckily the value used for this was later made a tunable kernel module parameter.
Enter, spa_asize_inflation .
This value is the multiplication factor applied to the original write request to determine the actual amount of space required to commit it.
By default, this value is set to account for the absolute worst case scenario across all possible ZFS configurations[3]; however, it factors in settings and features that often go unused by many, and as such tends to be extremely conservative. It is set to a whopping value of 24! So, there are cases where writes are assumed to take up to 24 times as much space as requested, meaning ZFS will begin limiting transaction size if free space on the target goes below that amount. The over simplified version is that you might only want to write 100 MiB, but ZFS will check to see if you have 2.34 GiB free.
It’s default value is realized as:
(VDEV_RAIDZ_MAXPARITY + 1) * SPA_DVAS_PER_BP * 2 = 24
Let’s break this down:
- VDEV_RAIDZ_MAXPARITY refers to the maximum amount of parity blocks that need to be written, which is the case if you are using RAIDZ3, and as such is defined as 3[4].
- The ‘+ 1’ is to account for the primary block being written, regardless of parity level
- SPA_DVAS_PER_BP refers to the maximum number of DVAs (Data Virtual Address) per BP (Block Pointer) and is defined as 3[5]. What this means gets fairly technical, but it’s essentially the number of pointers to real data blocks that can be contained within a reference to ‘virtual’ data within the ZFS filesystem[6-7]. The reason the value is 3 is because it directly corresponds to the configurable zfs property ‘copies’, which can be set between 1 and 3[8-9]
- The final factor of 2 is because the block might impact deduplication, which if it does, up to 3 more BPs could be contained within the duplicated (dittoed) DVA[3, 8]. Essentially, the value of ‘copies’ is accounted for twice.
So in practice the equitation ends up being:
(3 + 1) * 3 * 2 = 24
The Solution
Now that we understand this, the idea is to come up with a general formula that allows one to set an appropriate spa_asize_inflation value for their configuration specifically.
Taking what we know above, the equation can be reinterpreted into something that is a little more friendly:
spa_asize_inflation = (raidz_level + 1) * copies * (dedupe + 1)
where the variables are as follows:
raidz_level: 0 - 3 (0 if not using raidz)
copies: 1-3
dedupe: 0 or 1 (boolean, i.e. 0 = off, 1 = anything else)
NOTE: I believe if you’re using dRAID you can apply the same formula by just treating
raidz_levelas your parity level since they’re related and have the same range, but I’m not certain since dRAID is much newer and the source comments forspa_asize_inflationdon’t mention it.
Now, unfortunately since this is a kernel module parameter it affects the behavior of ZFS on your entire system, so when determining your own worst case scenario you have to consider the worst of these values across your entire setup (i.e. consider all pools/vdevs). Otherwise, it’s now just as simple as checking your pool configuration(s) and using this equation.
AFAICT the ‘copies’ parameter is not used very often, and as this great guide explains, you probably aren’t using deduplication, so in practice this is pretty straight forward.
In my own system for example, my main pool consists of a single RAIDZ2 VDEV, the ‘copies’ parameter on all of it’s datasets are the default of 1, and I don’t use deduplication. So:
raidz_level: 2
copies: 1
dedupe: 0
spa_asize_inflation = (2 + 1) * 1 * (0 + 1) = 3
Massively less than the default.
I’m not using duplication or a non-default ‘copies’ value for the boot/system pools either, nor am I using RAIDZ on them, so this value should work for my whole system.
To apply this change, you can add a sysctl tweak entry as follows at:
System → Advanced Settings → Sysctl->Add
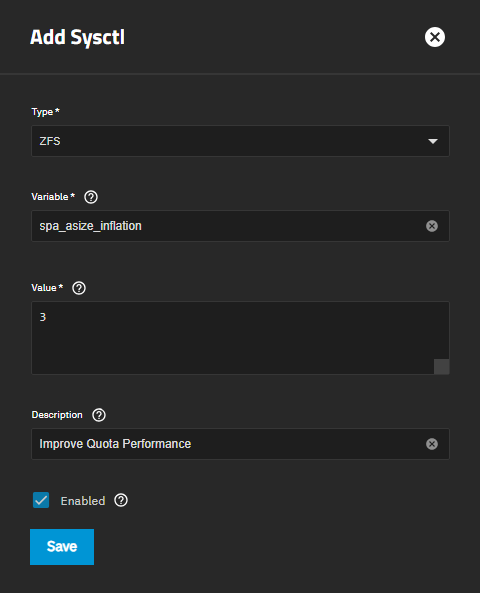
Be sure to replace 3 with a value appropriate for your configuration.
You can repeat the following on your system to ensure the value has taken effect:
admin@machine[~]$ cat /sys/module/zfs/parameters/spa_asize_inflation
3
admin@machine[~]$
I believe the ability to add ZFS kernel parameters on this screen was only added in Fangtooth, so if you’re on an earlier version you can try a pre-init script:
echo YOUR_VALUE >> /sys/module/zfs/parameters/spa_asize_inflation
or alternatively something like:
grep -qsF 'spa_asize_inflation' /etc/modprobe.d/zfs.conf || echo 'options zfs spa_asize_inflation=YOUR_VALUE' >> /etc/modprobe.d/zfs.conf
Conclusion
This should allow a dataset to get much closer to the limit of a quota before seeing performance degradation in many configurations.
Keep in mind that if you later change the configuration of your pool(s)/dataset(s) you may need to reevaluate this parameter if any of it’s factors were affected by your changes.
I hope that eventually OpenZFS is improved to handle this better in a seamless manner, like perhaps determining this value dynamically based on the vdev/dataset involved in the transaction group, but for now manually tuning this parameter when possible is likely the primary way to improve quota performance.
References:
- Writing to a filesystem close to its quota is slow and causes heavy IO
- Reason for performance degredation: openzfs/zfs/module/zfs/dmu_tx.c
- spa_asize_inflation default: openzfs/zfs/module/zfs/spa_misc.c
- VDEV_RAIDZ_MAXPARITY: openzfs/zfs/include/sys/fs/zfs.h
- SPA_DVAS_PER_BP: openzfs/zfs/include/sys/spa.h
- Some effects of the ZFS DVA format on data layout and growing ZFS pools
- What ZFS block pointers are and what’s in them
- Manual: spa_asize_inflation
- Manual: copies & dedup properties
- OpenZFS: Performance and Tuning / Module Parameters