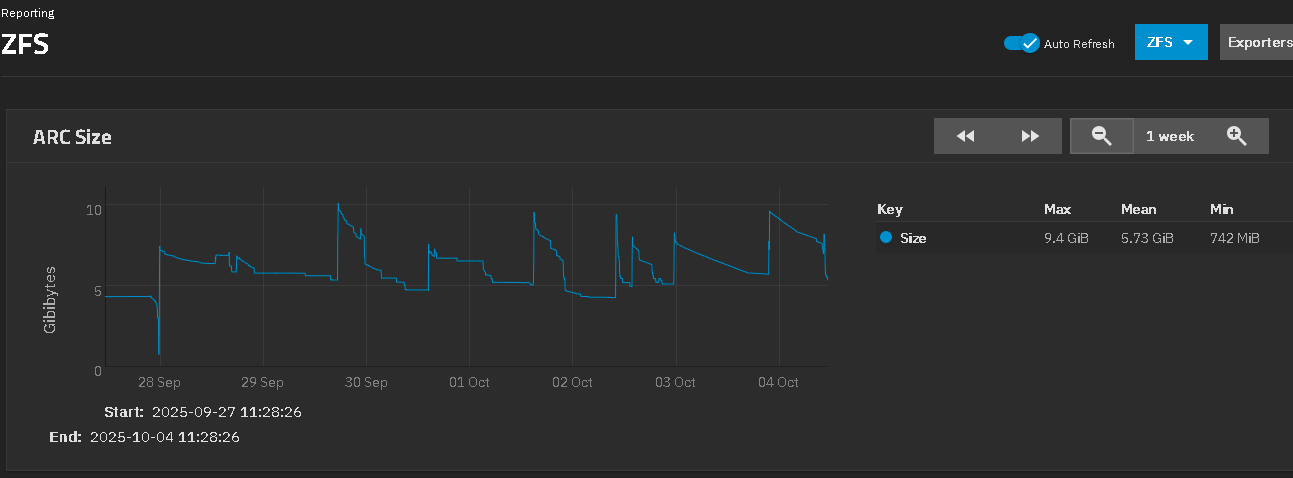
I’ve recently upgraded my NAS from CORE 13.0-U5.1 to SCALE 25.04.2.4.
I was still on CORE because I had pools with geli encryption as well as a pool that held unencrypted datasets within an encrypted root dataset.
System specs
- PSU:
Corsair HX850i - CPU:
Intel(R) Xeon(R) CPU E5-2620 v4 - Mainboard:
Supermicro X10SRH-CLN4F (Broadcom 3008 hba crossflashed to IT mode) - RAM:
128GB DDR4 ECC RAM - Boot drive:
128GB sata SSD - App drive:
1TB m2 SSD via pci/e to m.2 adapter - Data pools:
8x 18TB Toshiba HDDs as Z2 pool with zfs encryption
8x 12TB WD HDDs as Z2 pool with zfs encryption
10x 24TB Seagate HDDs as Z2 pool with zfs encryption - HBAs:
2x dell perc h310 crossflashed to IT mode - NIC:
1x Intel X540-T2 2x 10GbE
Upgrade steps from CORE to SCALE
After buying new hard drives, I installed the current version of SCALE on a spare PC, used replication tasks (with encryption enabled and matching the target pool) to move the problematic unencrypted datasets to a new zfs encrypted pool on the other machine and then moved the datasets off the geli encrypted pools to the then free zfs encrypted pool (where the unencrypted datasets were) within the CORE machine (also via encrypted replication tasks).
After performing a scrub on the target pools to ensure that there were no errors, I exported the geli encrypted pools, updated the CORE system to the latest CORE version, exported the config, physically removed the geli encrypted pools, performed a clean install of SCALE and imported the config.
Then I installed the new hard drives in the NAS and imported the new pool.
On SCALE the SMB performance is highly inconsistent. Copying files to/from the NAS works at expected speeds (~700MByte/s sequentially via 10GBit/s Ethernet). However traversing folders (especially ones with many subfolders) on smb shares makes Windows Explorer hang/load while also slowing active transfers down to <5MByte/s and killing the connection so much that even music playback from an smb share stutters or pauses. Opening a folder with 9000ish subfolders can take up to 5 minutes now. On CORE that same folder opened in less than 30 seconds if I recall it correctly.
The folder traversal speed has become so terrible that Voidtools Everything (which indexes the smb shares as network drives) takes multiple hours to scan them (during which the SMB performance is unusable) while it used to be able to scan them in a few minutes with a minor impact on other programs accessing smb shares at the same time.
MusicBee also takes multiple hours to scan for new music on the smb shares (and used to be able to scan them in ~20 minutes on CORE).
Curious is that if I let MusicBee finish a scan once and then immediately re-scan, the scan only takes the original ~20 minutes.
However the next day it’s back to crawling speeds, taking hours. I assume some kind of caching is involved but I’m unsure if that happens on my Windows 10 machine or on the NAS.
This performance degradation is also present on another Windows 10 PC of a family member.
The subnet also does not seem to matter. It happens when I access the shares via a 10GBit/s direct connection in the 192.168.0.x subnet and on the other Windows 10 PC in the general 192.168.1.x network.
I’m also using the music via an NFS share on a linux machine. That machine can index the files via NFS in 35 minutes (however this goes down to 6 minutes if I immediately let it rescan after a scan). This makes me think that the issue is SMB or permission related.
Steps I have taken to try and fix this issue:
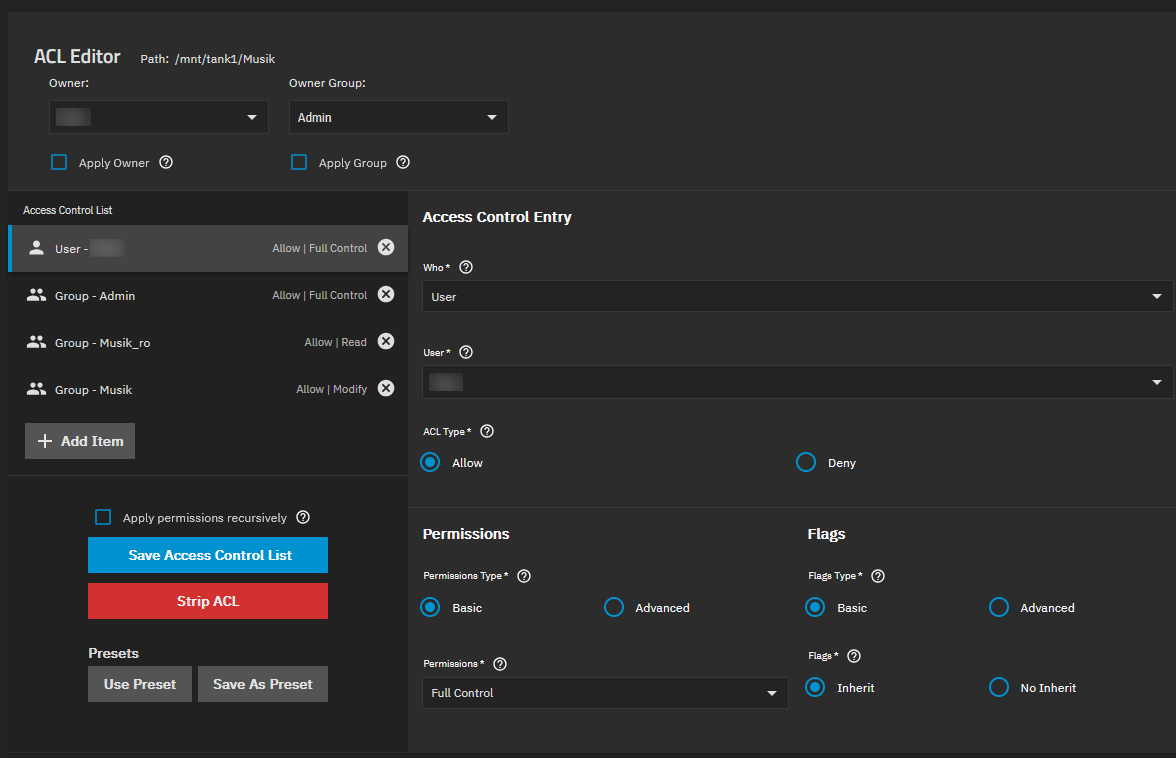
- recursively re-applied permissions (the ones imported from CORE were incorrect)
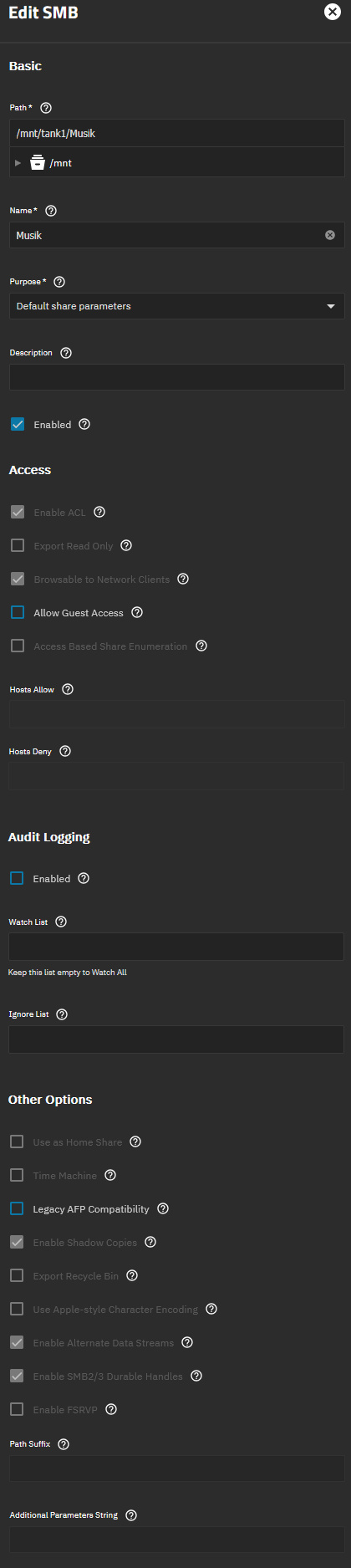
- changed all smb shares to use default settings
- checked dataset properties for unusual settings
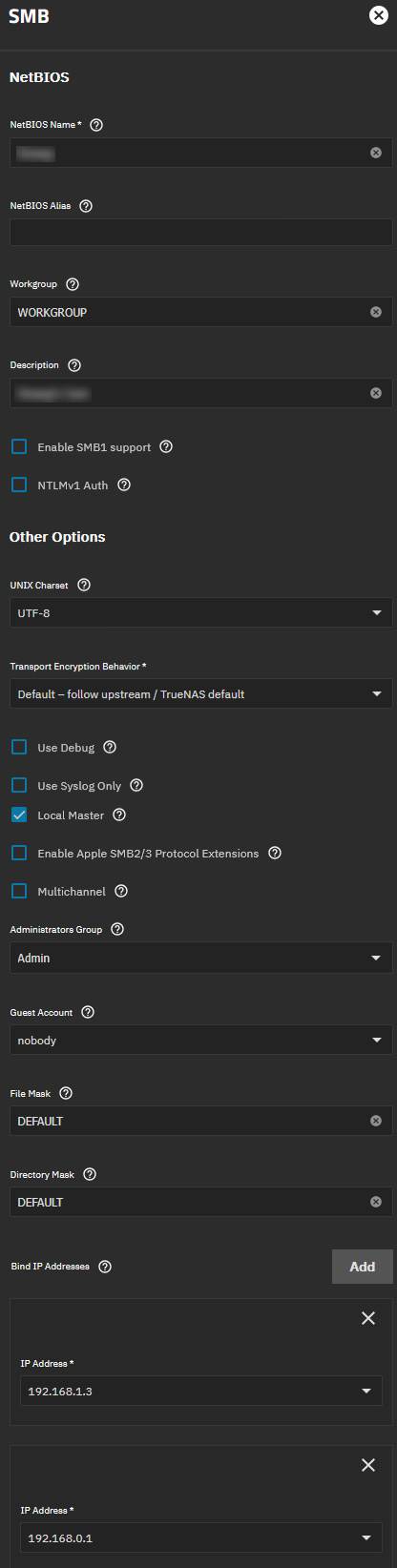
- checked smb settings
- upgraded the pools
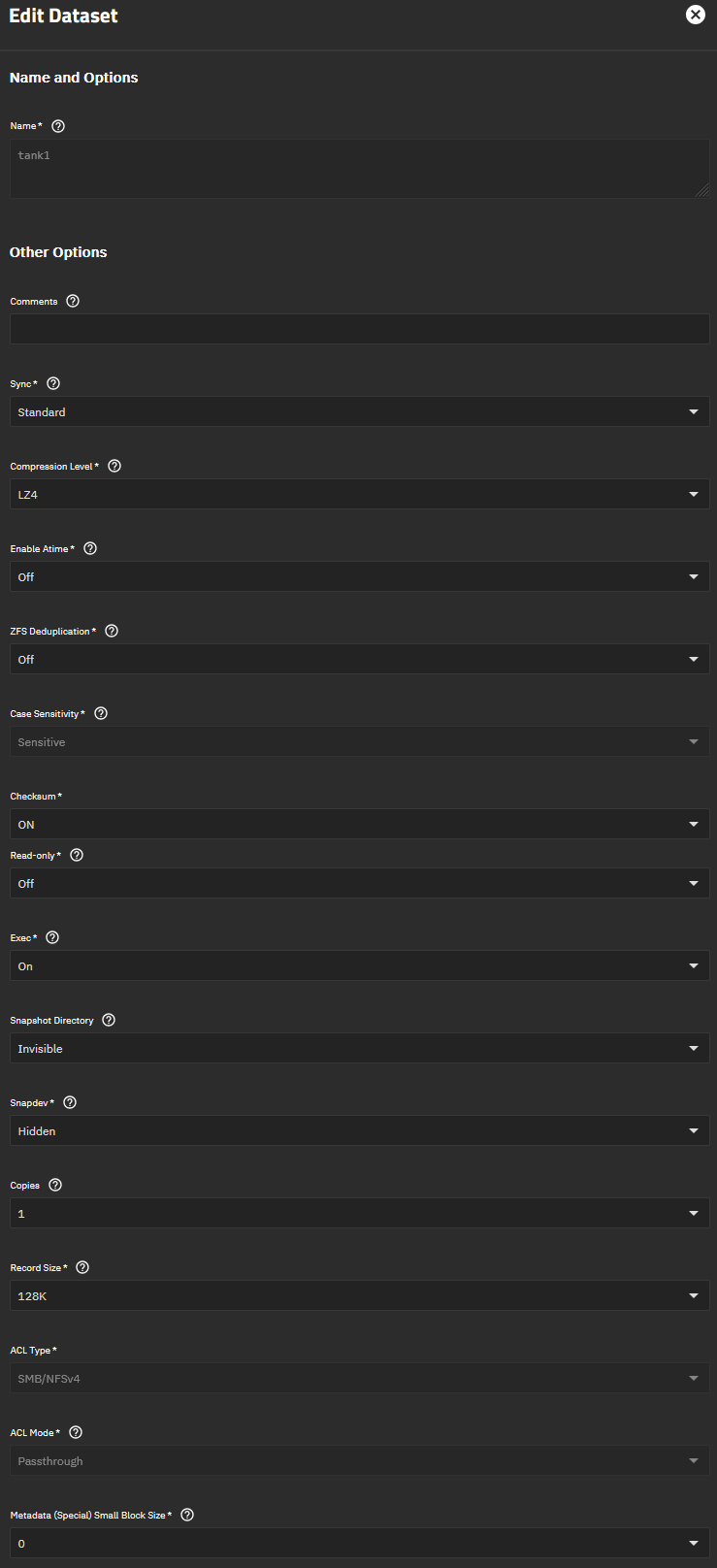
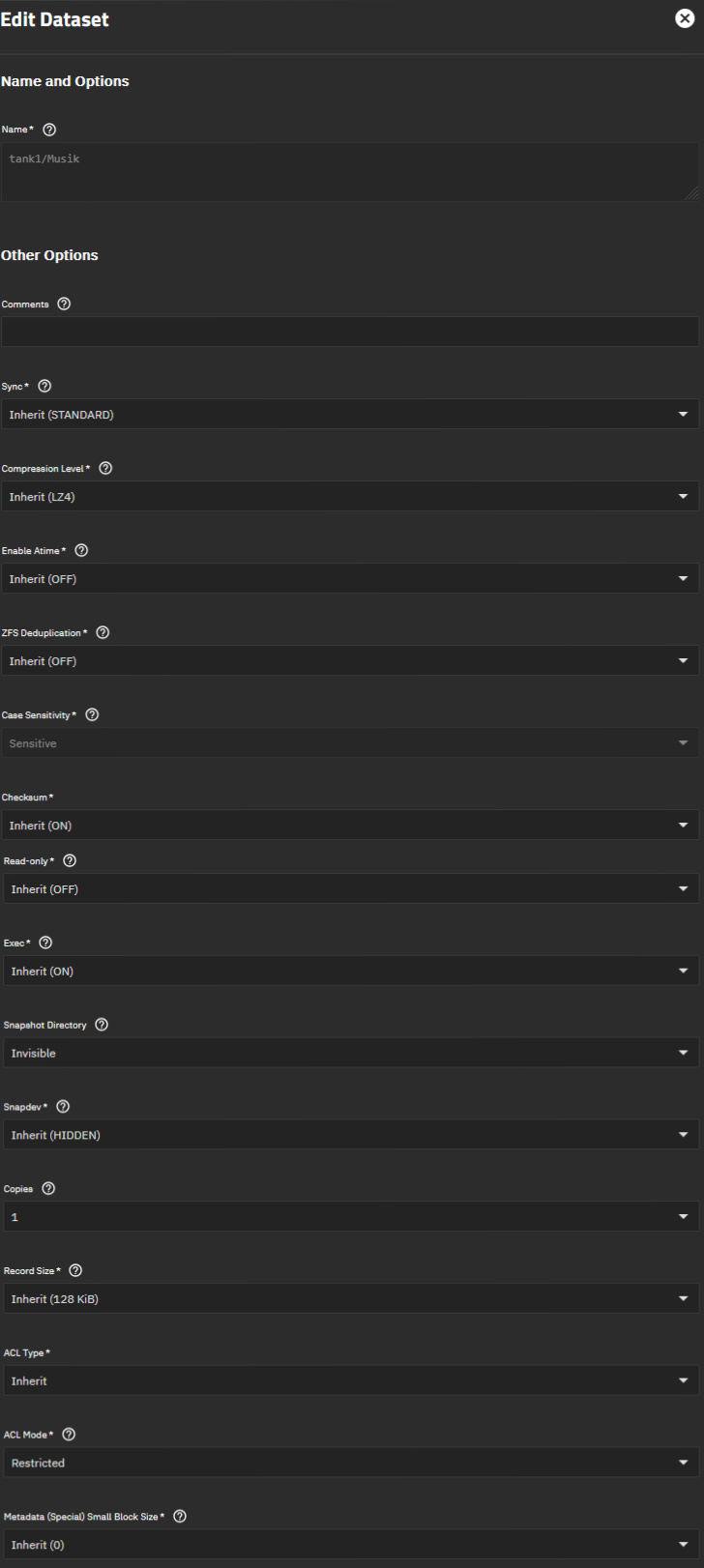
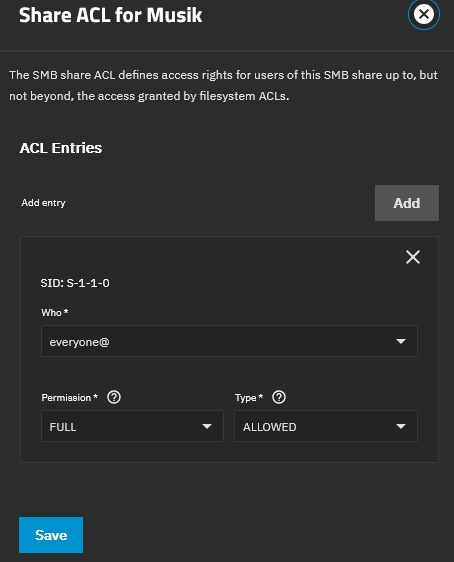
TrueNAS dataset and share settings screenshots:
root dataset properties:
music dataset properties:
music share ACL:
music ACL:
music SMB share settings:
global SMB settings:
I have been banging my head against this for the last week and I do not understand what the issue is. Hopefully some of you can enlighten me why the performance is so terribly inconsistent and how I can hopefully get it back to how it was under CORE.