Terramaster F2-423 NAS (Intel N5095 CPU. Intel i225 NIC);
2*8 TB WD Red Pro WD8003FFBX in ZFS Mirror for data;
2*256 GB NVME SSD ARDOR GAMING m.2 NVME 256Gb AL1282 in ZFS Mirror for SLOG;
64 GB RAM;
Connected via 2*2.5 Gb/s directly to the Proxmox host with 2.5 Gbps with Intel i226 ports (LACP bond).
OS is Dragonfish.
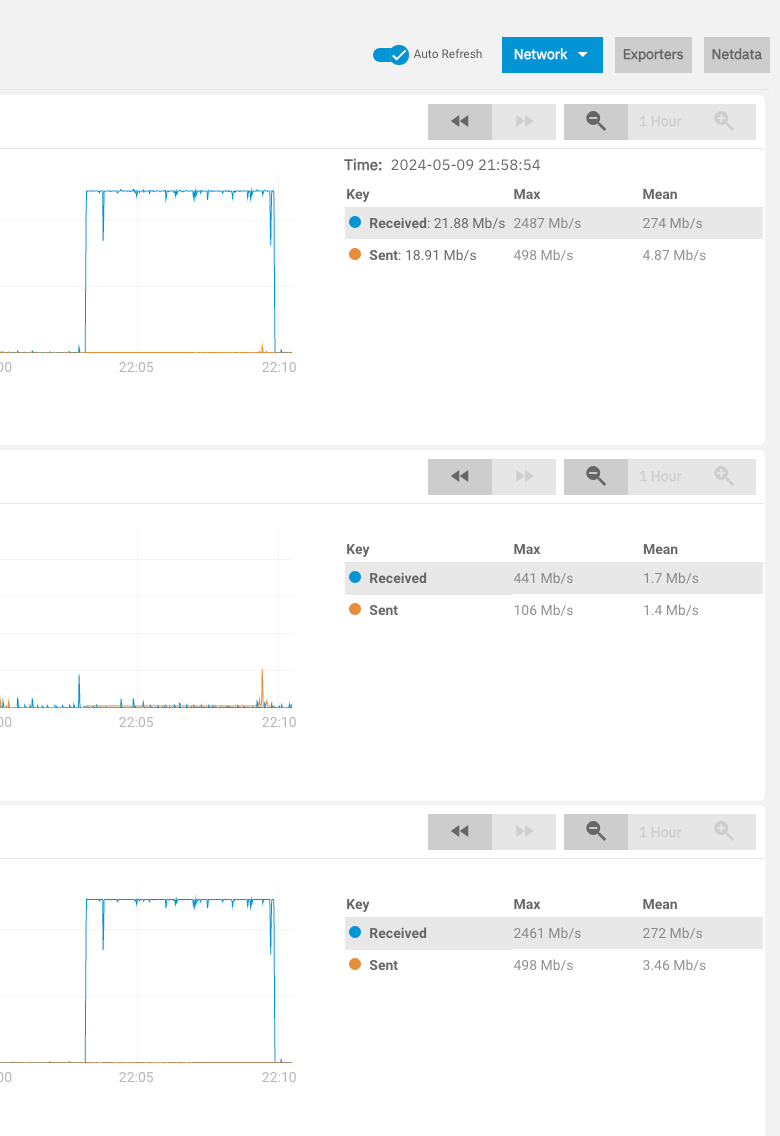
I’m facing a problem when copying large files such as VM backups from my Proxmox host to the NAS via NFS on a separate dataset. For example, if I try to upload some large files (20-30 GB) from my Mac to the NAS through the switch via 1 Gb/s wired connection, everything works fine. Write speed is consistent and is close to 1 Gb/s, networking data graph is nice and smooth. But when I try to upload those files from my Proxmox host which is directly connected via 2*2.5 Gbps links, write speeds are inconsistent.
I made some tests with fio with the following command from my Mac (1 Gbps) and Proxmox (2*2.5 Gbps): fio --ramp_time=5 --gtod_reduce=1 --numjobs=1 --bs=1M --size=100G --runtime=120s --readwrite=write --name=testfile
I guess I’m hitting some bottleneck but can’t figure out where, could please help me with finding it? In my opinion my setup should process 2.5 Gb/s speeds with no issues.
I understand that PLP is preferred but removing SLOG mirror from the pool doesn’t resolve the issue. It does the opposite: 1 Gb/s writes are degraded too.
Well, it’s not required for security, as long as the SSD is not broken by design.
PLP means an SSD can implement fast sync writes because it can safely acknowledge a sync write when it is received rather than when it is committed to flash, as it knows that in the event of a power failure (or more importantly system crash) it can finish writing the transaction to flash.
Without PLP the drive has to wait for the transaction to be committed to flash before acknowledging the sync write and this is where the terrible speeds come from.
OR the drive could be defective by design and say that it’s committed the write to flash when it hasn’t. This is how you get fast sync writes without PLP. And this can lead to data loss.
And then there is Optane, which can write to flash so fast, that it doesn’t matter if there’s no PLP on the drive.
FWIW, I think the issue may be you are being bottlenecked by your SLOG.
You can try setting sync=disabled temporarily on the dataset to see if this helps.
And the TerraStor only uses x1 lane per m.2. Which I think shouldn’t matter.
I was concerned about System CPU spikes and figured out that they are caused by z_wr_iss process. When I disabled dataset compression, those spikes went away.
Overall 2.5 Gb/s write became smoother, but not perfect. What I see now is that at first 10-20 seconds transfer speed hits 2.5 Gb/s but then drops and barely increases. This behaviour occurs every time:
It looks like you’re filling a write buffer somewhere in the storage chain and xfer speeds drop after that. Those WD Reds have 256MB cache each. Could be that once that’s full, and data needs to actually be written to disk, your iowait states go up and everything has to wait for the disks to catch up.
Interesting. I decided to make a separate zpool with 2 mirrored SSDs that I used previously for SLOG. Created a separate dataset with disabled sync, compression turned off. Ran the same tests with fio and it looks familiar to HDDs, but amount of time on 2.5 Gb/s writes is much longer, but shortens on every attempt.
I tried another attempt with copying beefy VM snapshot (~120 GB) from my Proxmox host to newly created SSD-based dataset. On per-core CPU dashboard I can see strange per-core spikes up to 100% that match with dropping write speeds, though there is no are issues on Total CPU Utilization dashboard. Later then something like “TCP Sawtooth” pattern, but something tells me it is not a networking issue.
Swap was already disabled. This is where it all started from, by the way.
I noticed terrible performance on my backup tasks and some of my k8s workloads that use ZFS over iSCSI after upgrading. I had 16+4 GB of RAM so I decided to upgrade RAM to 32+32 GB. That didn’t help and then I noticed some CPU throttling due to peak CPU temperatures. I changed the thermal paste, got rid of throttling but performance was still unacceptable. Then I figured out this swap problem on Dragonfish and disabled swap, but the problem was still there. Then in order to play around with write performance I got two NVMe SSDs for SLOG (they are TLC). That didn’t help as well.
So now I’m here asking for help, because I’ve seen similar setups on Intel 5095/5105 NAS builds that could saturate 2.5 Gb/s link (DIY NAS: 2023 Edition - briancmoses.com) and I’m frustrated and cannot understand what am I doing wrong.
I tried to run some copy tests with the same snapshot file using two different NVME to USB adapters connected directly to my Mac. Write speeds are almost the same I’ve seen when they were connected to TrueNAS, so those SSDs are cheap and bad.
Then I tried to run some local test with dd directly from TrueNAS on a single SSD, also got the same under-2.5 Gb/s result:
dd if=/dev/zero of=/mnt/ssd/ssd/tmp.dat bs=2048k count=50k
51200+0 records in
51200+0 records out
107374182400 bytes (107 GB, 100 GiB) copied, 488.39 s, 220 MB/s
Ok, what we’ve got is a really slow single SSD for write. Let’s convert it to stripe pool instead of mirror. After that:
dd if=/dev/zero of=/mnt/ssd/ssd/tmp.dat bs=2048k count=50k
51200+0 records in
51200+0 records out
107374182400 bytes (107 GB, 100 GiB) copied, 93.5753 s, 1.1 GB/s
And network transfers at 2.5 Gbps are now nice and smooth:
The most satisfying part is that now CPU load average during file transfer is pretty low (~1).
Now returning HDD transfers where it all started from. Obviously as @etorix mentioned, I’m hitting HDD max write speed limit (or throughput). Those HDDs cannot ingest data at line-rate, unfortunately. In this case I’m concerned about high CPU load average (20 and more for 4-core CPU) due to increasing iowait. Will it be a good idea to manually negotiate lower speed on NICs, 1 Gb/s for example? Just to control CPU LA.
And the second question is about increasing write speeds to line-rate. I see two options.
1 x 3-wide Z1
2 x 2-wide Mirror
Now if I have 8 TB pool (1 x 2-wide mirror of 8 TB drives) and would like to have the same pool size, I can go with 4 TB drives in both cases above. Am I correct?
Great info in this thread. I know when I was testing my system I had similar issues with peak speeds, then dropping over the network, even though I thought my rig was beefy enough. I was then seeing 100% CPU spikes on a single core when doing fio tests:
And can’t reply on the other forum MrGuvernment, but the true nvme speed could not be more than 4GB/s, as was discussed by @Arwen
As soon as you start trying to benchmark zfs datasets things get weird because of ARC etc.
Its a good idea to keep an eye on your threads when benchmarking something like this as well, because with nvme and smb etc etc things can easily get single thread bound, ie the perf you see is limited by the max speed of a single thread…
Thus high clocking modern CPUs can be good for filers, when trying to saturate high bandwidth links, with few client connections