AFAICT, when dealing with a zvol, it doesn’t matter if its an “incus” zvol, or a zvol from somewhere else, they get treated as block-devices, and the same aioMode and cacheMode gets applied, unless overridden by configs.
The only difference that matters for performance, AFAICT, is the primary/secondary cache settings on the zvol.
And I have looked.
NOW,
@awalkerix makes a legitimate point about drives being able to backed up neatly using incus commands when they are imported as custom block volumes into an incus storage pool (using the zfs driver), but I was referring to the performance differences in usage, not the additional capabilities provided by incus when dealing with “native” images…
Which then leads back to the link I provided, which documents how to replace an incus existing vm root device with an external zvol, and if it wasn’t clear… the external zvol is no longer an external zvol… its a root device in the incus storage pool… not a custom block volume device in the pool but an actual root device, which gets snapshotted/backedup/restored with the instance, with no extra configuration.
So I shut down the Windows VM and spun up a new Fedora from scratch for the heck of it, and I got the same issue.
The more I dig into this, I’m thinking it might be exactly what the error message is saying … out of memory… the thing that threw me for a loop is that I never had this issue (with the exact same VMs) before Fangtooth. There seems to be something that spikes memory usage briefly (looking at graphs) and since I don’t have a swap … down goes the VM. I’m kind of wondering if ARC max size logic has somehow changed in fangtooth and the zfs part takes up more memory without consideration for VMs. Going by old forum threads, default for arc max size is half of system memory (which should still leave me with 64gb … pleeeenty). However, it seems like that value was tweaked based on VMs previously, and I’m thinking that was just not carried over to incus? That’s me guessing though.
I have no idea what’s causing spikes in my memory usage. The zvol stuff all improved performance from an io perspective for me, but ultimately unrelated to oom crashing.
So my initial thought on this issue when it was happening to me was that ARC just wasn’t releasing memory fast enough if the system comes under sudden memory pressure. But it seemed to be happening when the system wasn’t actually “out of memory” (still had 5GB free). That’s when I started to suspect memory fragementation and starting reading everything I could on the topic. Are you seeing a lot of kcompactd activity leading up to these crashes? That’s the marker that sent me down this path of inquiry.
@tokyotexture I’ve been thinking about your issues and I was wondering if maybe adding a little swap space might help. I think your kernel is coming under memory pressure it can’t resolve fast enough. Maybe this is a problem with the ARC not dumping things fast enough, but giving the kernel another option other dropping filesystem pages might prevent the crash.
These smallest Optanes are limited to about 150MB/sec, but the IOPS are still pretty good and the latency is low. iXsystems sets the vm.swappiness of the kernel to 1, so it really shouldn’t swap unless it absolutely has to. Interested to see what will happen.
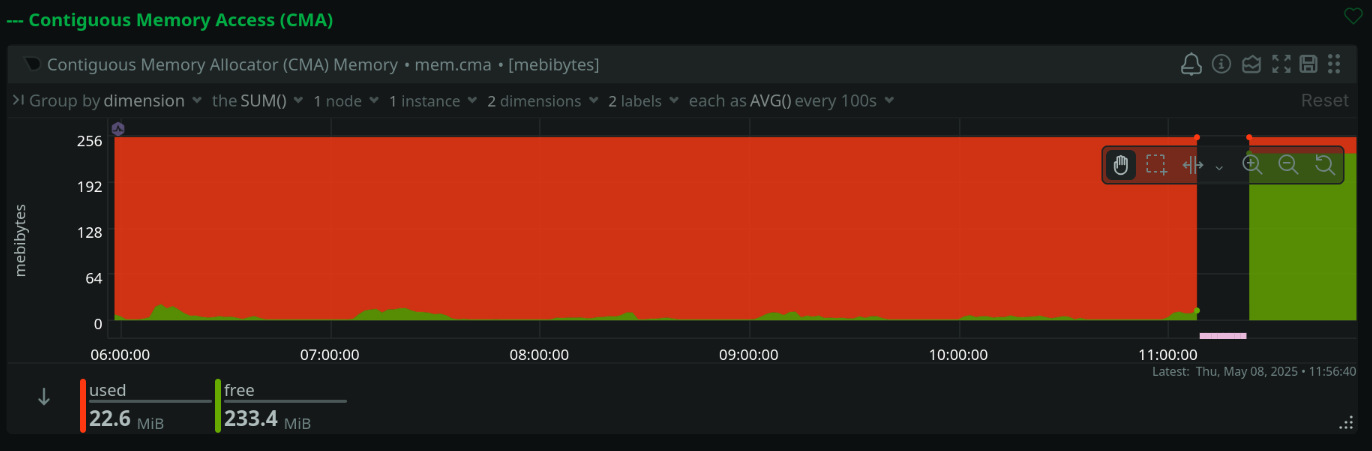
One of the reasons I’m poking at this is I’m seeing really really low contiguous memory available once I leave the system on for a long time. I think the ARC using all the otherwise unused memory plus large VMs like @tokyotexture and I are running might be perturbing the kernel’s memory mamangement. ARC on Linux still doesn’t seem quite as slick and tightly integrated as ARC on FreeBSD was*.
*I’m just a sysadmin, take this opinion with a grain of salt. If you know better, I’m eager to listen.
I’m thinking the same thing. I feel like it’s really short “blips” for whatever reason. I had the VM crash again the other day, and looking at just free memory graph, something all of a sudden grabs like 10GiB of memory and I have no idea of what it would be. The graph is just steady state with me doing nothing.
My system has been running for several days with a swap Optane, the ARC has filled the memory per the usual, but I only had ~45GiB committed on a 128GiB system (ie I have memory to spare). I decided to setup a bunch of pool scrubs as a test. I have 3 pools and had them previously set to all start a scrub at the same time. in the past this caused my largest VM (Security Onion 32GiB) to OOM.
With the kernel set to vm.swappiness=1, I wasn’t expected much swapping, maybe a couple hundred MiB pretty quickly and then leveling off with pretty minimal swapping in/out. What actually happened is over the last 2 hours the swap usage has grown to nearly 5GiB and has been swapping things out almost constantly. Also, the free memory has been growing slowly, from 6GiB it dipped to 4GiB and has been slowly growing to almost 11GiB now.
Seems super weird, but all around, but it proved my theory that swap space would prevent the crashes I was seeing.
Yes, I listen to T3 weekly as well. I’m not saying swap is great, but it’s usage tells us some things.
The system is coming under memory pressure that it is unable to resolve through dropping filesystem pages alone. This points on the direction of anon pages as our problem area.
The system here has ample memory that is being occupied by ARC, so why wasn’t ARC discarded to resolve this memory pressure?
Since most of us here aren’t developers compiling our own kernels nor running the nightly snapshots, it’s maybe a work around for people like me and @tokyotexture that continue to have issues with this.
I have a bug open on this already, I haven’t heard anything about it in a while. Not sure what other options we have.
Same. I would like for arc to just get evicted since I have lots of memory and not swap. But if I need to use swap until this gets resolved in order for my VMs to not crash once a day … well …
I figured something out. If you do a cat /proc/meminfo you get a bunch of memory stats from the linux kernel. One of those stats is “Cached”, this is memory that stored by the kernel to speed up things when RAM is not otherwise in use. ARC DOES NOT show up to the kernel as cached memory, it’s a separate thing and appears as Used memory (in top, ARC doesn’t show in cat /proc/meminfo for some reason). Because ARC is used memory, it takes priority over cached memory, so as it’s memory footprint grows it slowly displaces the standard linux cache memory.
So far, everything sounds lovely. Our superior ARC cache is using free memory so it isn’t wasted, but then along come our Incus VMs. For reasons I don’t understand, our VMs show up as cached memory to the linux kernel. Now we have a situation where the kernel thinks there’s a bunch of memory that it can dump if it needs it, but it’s not really cached memory, it’s VM memory. When a sudden memory pressure comes along, the kernel says “ok, I’ll dump those filesystem pages I have cached” but discovers quickly it can’t actually do that. It also can’t page them to the swap because there isn’t one. The kernel is now out of options and running out of time as the memory is quickly filling so it calls the OOM Killer.
The OOM Killer kicks down the door to the overcrowded process barn. All the processes cower in fear as the OOM Killer selects the largest, fattest process from group. The ARC sits in the shadows, unseen, not sure if it should act as the OOM Killer drags the process outside. A single gunshot is heard…the problem is solved.
clears throat
I think that’s what’s going on. I’m not sure if this is specifically an Incus thing, or if libvirt was doing the same in ElectricEel. I loaded up libvirt on my fedora 42 laptop and VM memory shows as Used, not cached, but I can’t easily roll back to EE with my server now as I updated my ZFS pools already. I’m like 99% sure that VMs shouldn’t be showing as Cached.
Well they posted before me, but I figured this out last night I swear.
An alternative workaround I’m playing with is using the Linux Huge Pages which put the VM memory in an entirely separate area. The downside is you have to mark it off at boot time and can’t grow it once the memory becomes fragmented.
ZFS allocates memory in several different ways. Where applicable, it does report to the kernel what memory is reclaimable on demand. Linux kernel does use that information for internal purposes to reduce fragmentation, etc. But for some reason not for all allocation kinds kernel accounts the reclaimable memory it as “Cache” (for some it does). And there is not much more can be done about it without patching the kernel. But while it may be an inconvenience for management, it does not really affect how kernel requests for the memory reclamation when needed.
The problem here is mostly specific to the VMs case. ZFS was incorrectly seen that memory as part of evictable page cache, rejecting kernel’s eviction requests, expecting kernel instead to evict that memory first. Obviously kernel could not, or was rather doing it quite drastically, by killing VM. See also my updates in the ticket above.