Hello all
short version, 8th Aug:rebooted/unset/rebooted/reset …still stuck.
Long version below showing everything I tried yesterday
A couple of hours ago one out of my six running apps needed to be reconfigured (TN app “Frigate”). Having done so, I couldn’t restart it beyond “deploying” so I tried (many times) to stop it from the UI.
Then I followed some forum advice (can’t remember the post but it seemed sensible and I think I’d used this approach before) so I tried unsetting and then resetting the pool which didn’t work, instead giving me this:
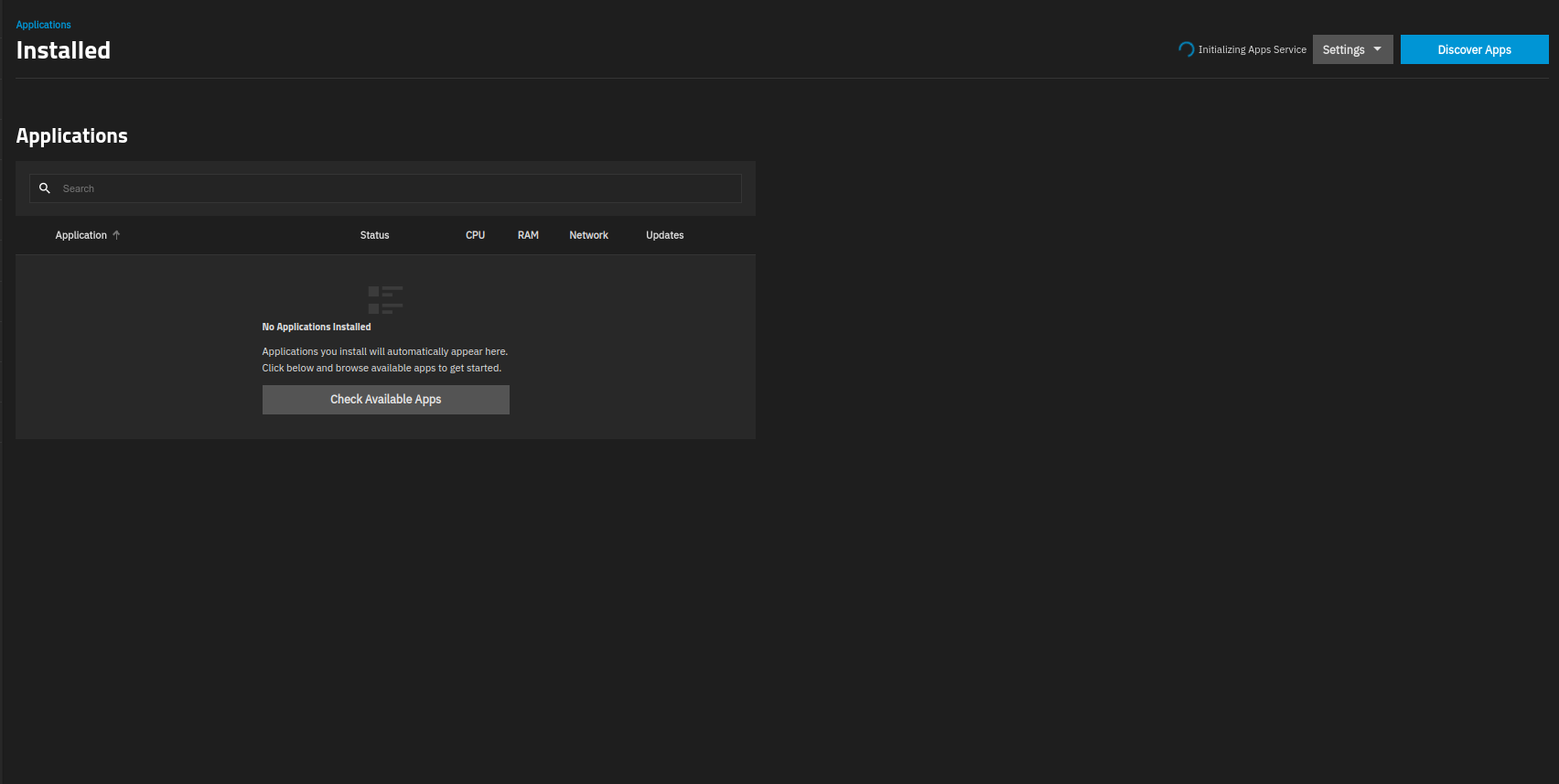
[edit - I did not reboot between unsetting and resetting the pool - I have since found other forum posts which suggest rebooting is a requirement].
I waited and got no progress so I decided to reboot TN. After doing so I got this instead:
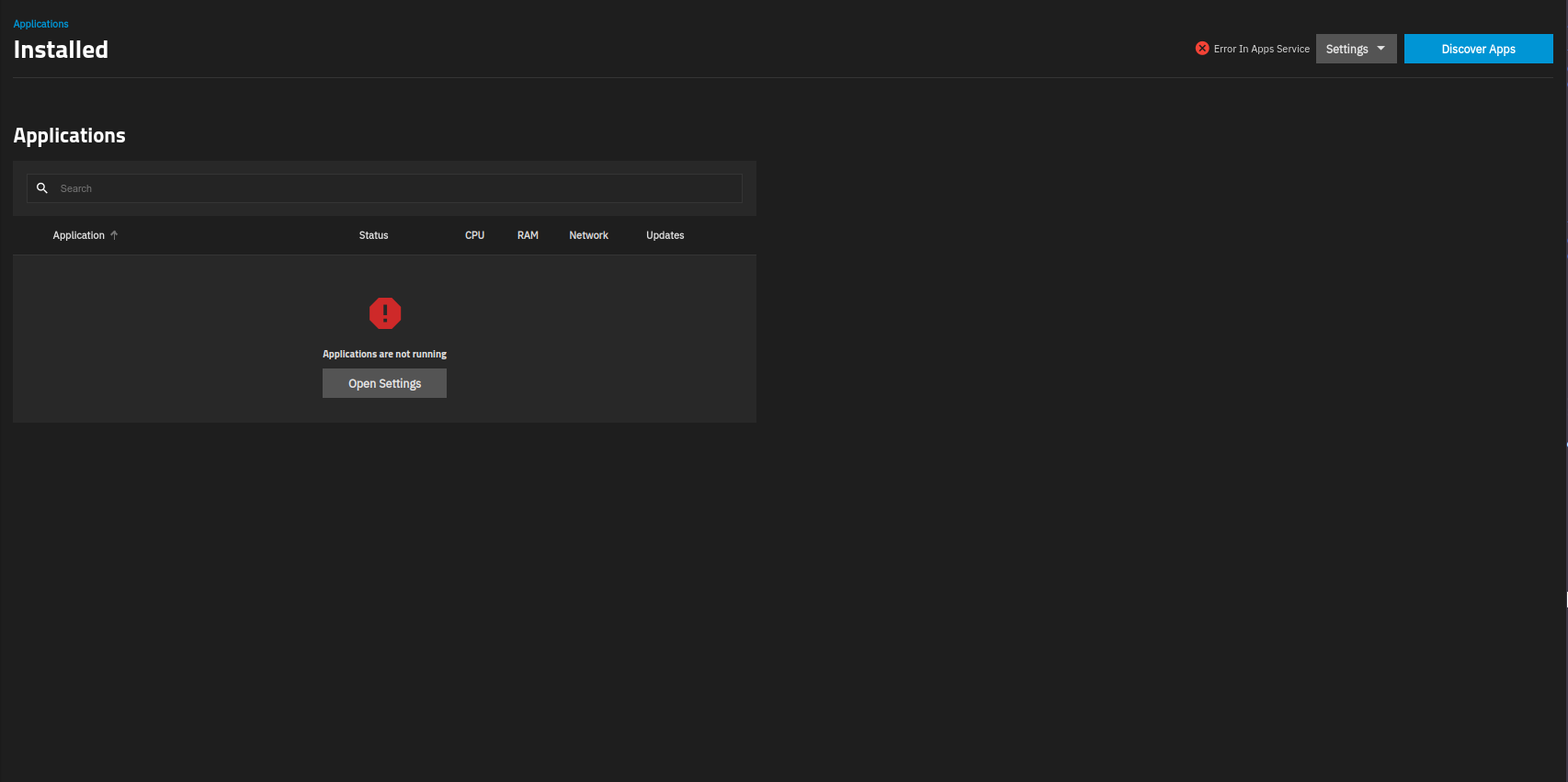
and an error message in the log telling me
CRITICAL
Failed to start kubernetes cluster for Applications: Client connection error raised from ‘/api/v1/pods’ endpoint
I searched here for a fix and saw this post so I decided to try the steps mentioned:
1. systemctl stop k3s
2. cd /mnt/data/ix-applications/k3s/server/db/
3. cp state.db state.db.save
4. sqlite3 state.db.save ".dump" > recovered.sql
5. sqlite3 state.db.recovered < recovered.sql
6. cp state.db.recovered state.db
7. systemctl start k3s
That didn’t work because after step (7) I saw in the ssh console:
Job for k3s.service failed because the control process exited with error code.
See “systemctl status k3s.service” and “journalctl -xeu k3s.service” for details.
I tried systemctl status k3s:
k3s.service - Lightweight Kubernetes
Loaded: loaded (/lib/systemd/system/k3s.service; disabled; preset: disabled)
Active: activating (auto-restart) (Result: exit-code) since Wed 2024-08-07 15:03:17 BST; 3s ago
Docs: https://k3s.io
Process: 46695 ExecStartPre=/sbin/modprobe br_netfilter (code=exited, status=0/SUCCESS)
Process: 46696 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS)
Process: 46697 ExecStart=/usr/local/bin/k3s server --flannel-backend=none --disable=traefik,local-storage --disable-kube-proxy ->
Process: 46721 ExecStopPost=/usr/local/bin/k3s-kill.sh (code=exited, status=0/SUCCESS)
Main PID: 46697 (code=exited, status=1/FAILURE)
CPU: 160ms
Then I started to sweat because I realise I don’t know what to do.
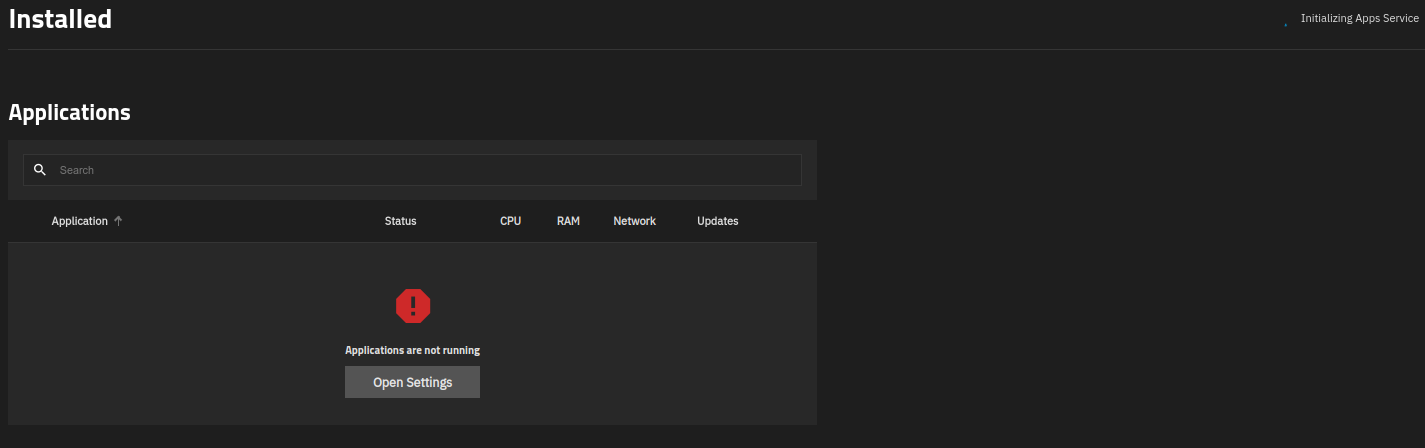
Fifteen minutes after rebooting, I’m still seeing the first picture “initialising apps …” combined with the second “applications are not running” and the big red exclamation mark where the “apps” should be.
Please can anyone help? I hope not to lose the six apps, because one of them is a custom app which i must have set up a couple of years ago and I can’t remember how I did it. The remaining apps are all standard TN catalogue items and not hard to reconfigure, but it is a bit laborious.
edit - I forgot to show you what my “apps” kubernetes settings look like. I don’t know what they were set to before I rebooted but this is what they say now:
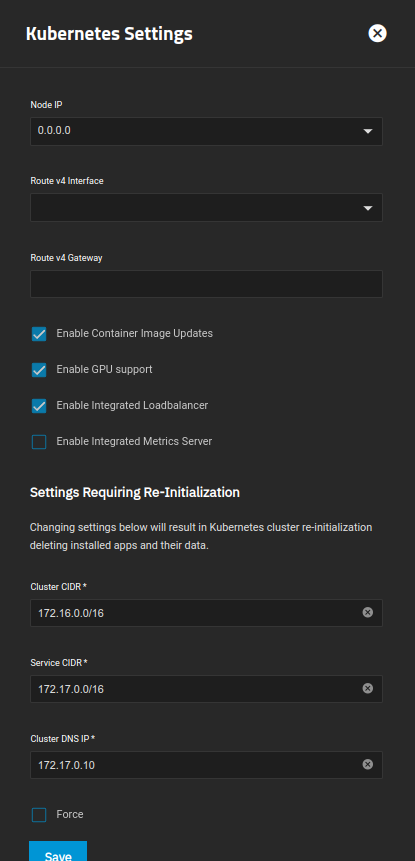
(I don’t know what to set the node IP or route v4 interface to, for example).
Thanks for any assistance which can calm me down and stop me weeping.
EB