I’m asking for support on how to identify a problem in my homelab, where I have two similarly configured systems with TrueNAS Scale running in VMs over Proxmox VE 8.2.4.
The two systems run on significantly different hardware: A tiny mini PC with PCI passthrough to host TrueNAS VM of a single SDD (to host TrueNAS datasets) and a mini PC with hardware passthrough to host TrueNAS VM of an additional SATA controller board (again, to host TrueNAS datasets).
On both systems, Proxmox boots from distinct NVMe drives and it does not use neither the single SDD nor the additional SATA controller board passed to the TrueNAS VMs hosted on two Proxmox systems.
The two Proxmox systems run the hosted TrueNAS Scale 23 for months, with no troubles, being stable and reliable, until I decided, a few months ago, to upgrade both systems to Scale 24 Dragonfish.
After upgrading both to Scale 24, the system with PCI passthrough of the additional SATA controller board became unstable, experiencing various problems. Unable at that time to address the problem, I decided to step back that system to Scale 23.10.2, while leaving the other smaller system running Scale 24, while waiting for newer Dragonfish releases and available time before attempting to upgrade it again.
Both systems run stable in the meanwhile, one with Scale 23 and the other with Scale 24.
A few weeks ago I decided to address the problem again, attempting to upgrade the system running Scale 23 to Scale 24.04.
Having Proxmox servers over the hardware, I decided to create a second VM to run, alternatively, Scale 23 and 24 on the same hardware presenting the issues, to investigate the problem, since it’s unclear to me if the problem is related to the VM configuration in Proxmox, to TrueNAS, or to something else.
I did many attempts, configuring the new VM hosting Scale 24 with different BIOS (SeaBIOS - OVMF), Machine (i440fx - q35) , PCI Device options and underlying Proxmox drivers, and installing Scale 24.04 many times over it, but the system runs stable only using Scale 23.10.2.
I found no clue on how to address the problem or how to investigate further.
While running Scale 24.04, the system reports all of the sudden & all together, within 24h from boot, problems with the attached disks via the additional SATA controller, like [“any disks” being, in any order, anyone of the eight disks in the JBOD]:
- Device: “any disks” [SAT], not capable of SMART self-check.
- Device: “any disks” [SAT], failed to read SMART Attribute Data.
- Device: “any disks” [SAT], Read SMART Error Log Failed.
- Device: “any disks” [SAT], Read SMART Self-Test Log Failed.
- Device: “any disks” [SAT], not capable of SMART self-check.
The problems persist, with the system unable to access the disks.
Properly shutting down the system (long and troubled) and booting up again, all of the disks are accessible again, marked in DEGRADED status but with no error reported.
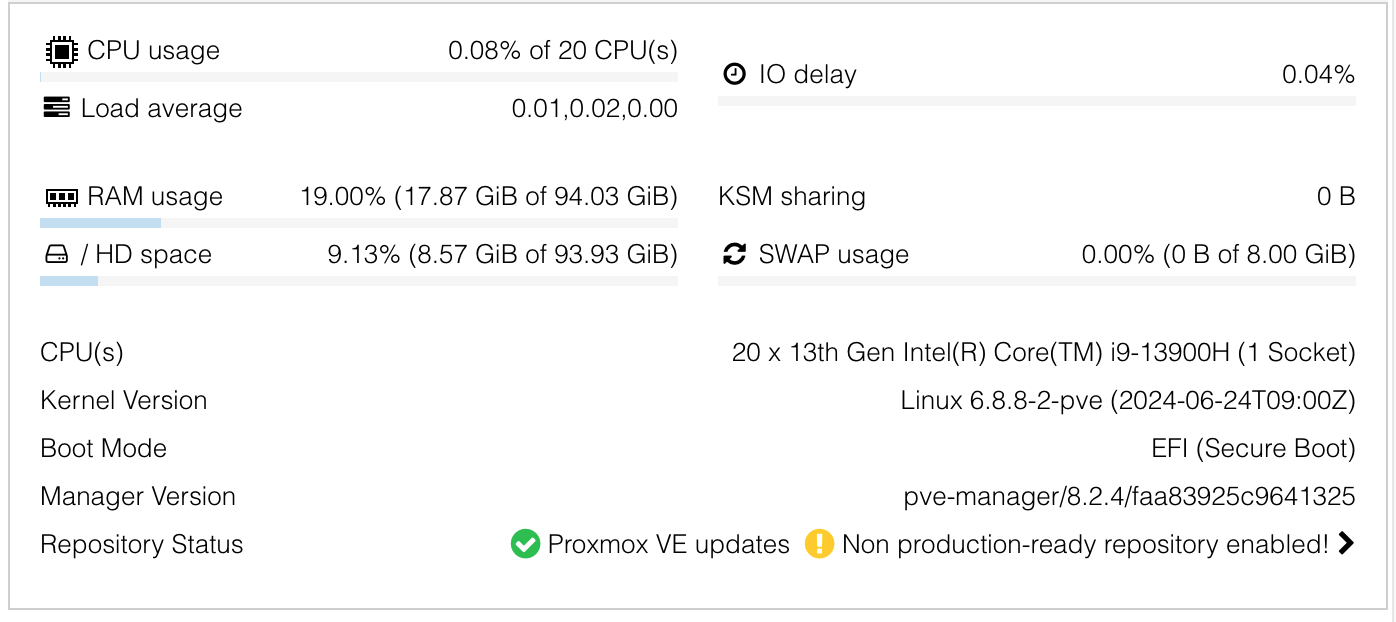
SYSTEM INFO:
The underlying hardware experiencing the instability only using Scale 24 is a Microforum MS01 (i9 13900H) where I installed the QXP-800eS-A1164 additional SATA controller coming with a QNAP 8BAY TL-D800S JBOD, and where I set up Proxmox with PCI passthrough to the TrueNAS VM of both ASM1164 controllers of the QXP board.
Microforum MS01 i9 13900H
96 GB RAM
512 GM SDD (Proxmox boot & VM volumes)
Proxmox VE 8.2.4 (kernel 6.8.8-2-pve)
TrueNAS VM (current setup, after other attempts)
16 GB RAM
Processors Type Host, 2 sockets, 2 cores
BIOS OVMF
Machine q35,viommu=intel
SCSI Controler VirtIO SCSI single
PCI Device passthrough:
hostpci0: 0000:03.00.0 (ASM1164 #1 on QXP board)
hostpci1: 0000:06.00.0 (ASM1164 #2 on QXP board)

I appreciate suggestions on how to solve and/or how to investigate the problem.
Thanks.