I am building a new TrueNAS storage server for storage for our 4 Node Hyper-V cluster. The server is a Dell R640 with 2x Xeon Gold 6134 CPU, 128GB RAM, 2x 256GB M.2 SSD (Boss Card) for OS, 8x 1.92TB U.2 NvME for Storage (Model: Samsung MZQLB1T9HAJR-00007.) Connected via HBACurrently running Scale (I would like to run Core but issue #1 is preventing me from doing so as it requires all drives to be identical.)
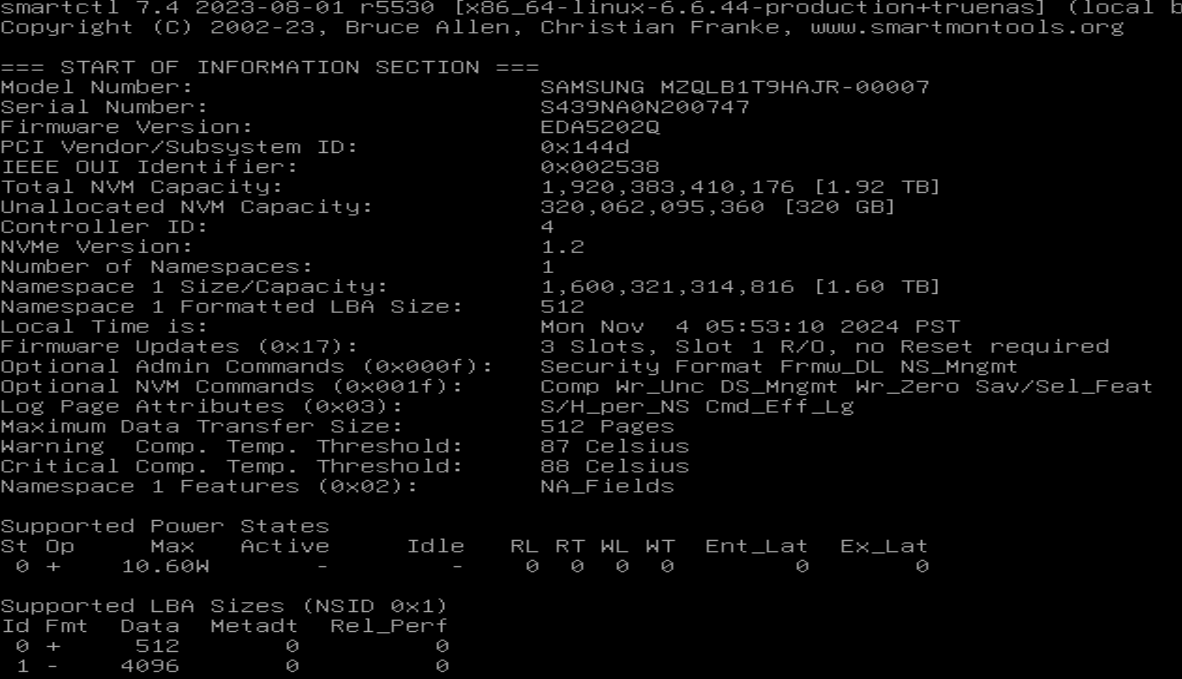
Issue #1: 7 of the 8 Drives show up as 1.46 TiB and 1 of the 8 Drives show up as 1.75 TiB although they are identical drives. Happens in both Core and Scale.
Also would like some advise on how to setup the pool layout to maximize speed and have at minimum 1 drive failure. I would like to real-time replicate this box to another truenas at a later point.
Looking forward to your insight into issue #1 and your recommendations on the pool setup. Thank You in Advance!
I’m not sure I follow as to the problem with Issue #1. You could build a RAIDZ2 (or 1 or 3) using all the drives, well anything, the size should not prevent you from creating anything. The drive reporting 1.75TB will only use 1.46TB of space is the only concern you have?
What kind of speed are you looking for? It is relevant to provide you ‘good’ advice. The use case matters here.
Does this mean you need ‘block’ storage (iSCSI)? I really don’t know about 4 Node Clusters, I’m not an I.T. person but someone will likely chime in.
Correct, using iSCSI Block Storage with MPIO and Failover Clustering. As far as speed, I would just like to take the best advantage of the drives capabilities and maintain at least 1 drive redundancy. We host several MS SQL databases on these VMs, so making sure those are responsive would be my highest priority. We have 2x 10GB uplinks to the storage server, and 1x 10GB uplink to each Hyper-V Node.
That’s what “overprovisioning” is about: Setting up more cells as reserve (= “provision”).
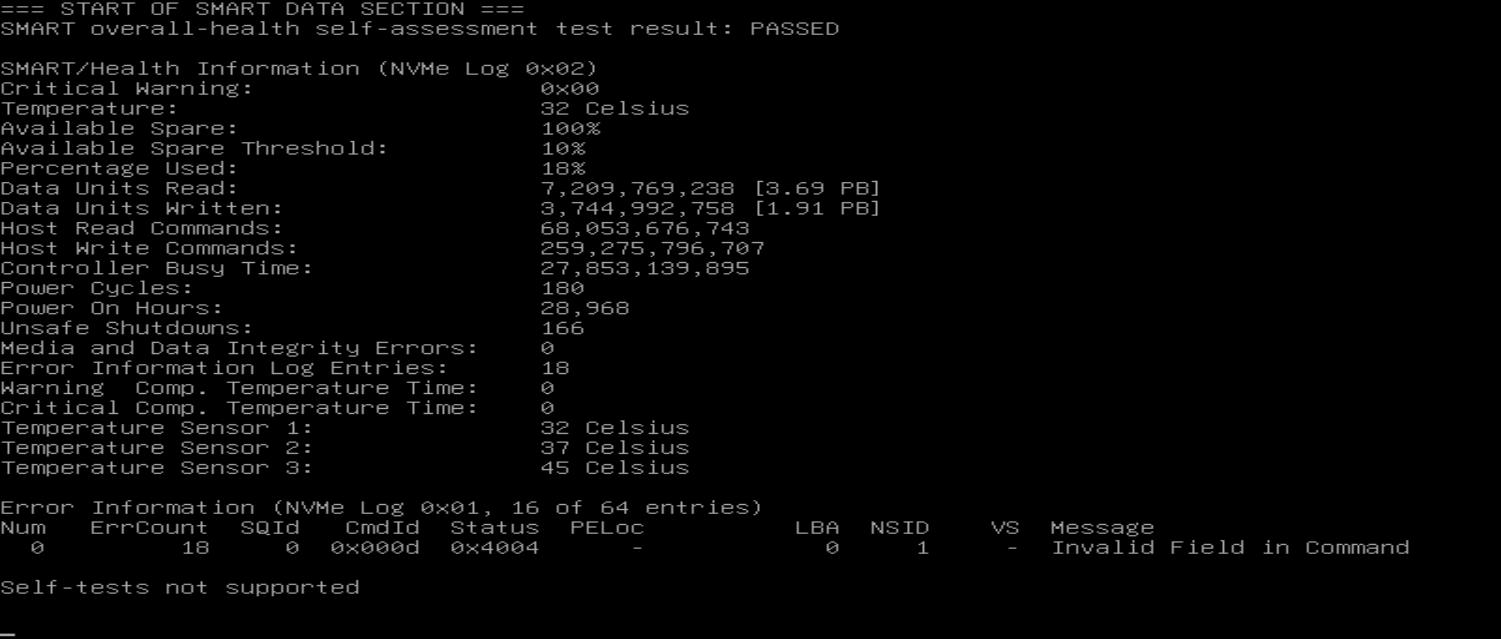
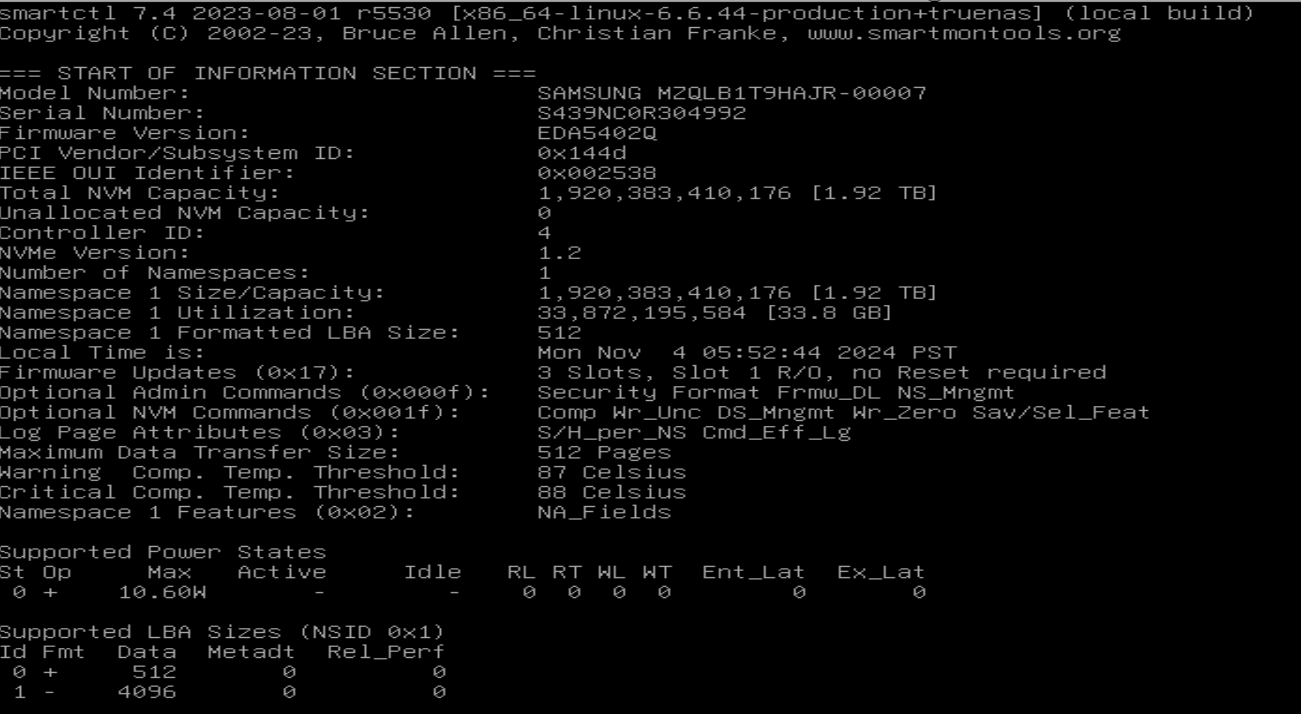
Your first drive is used (nearly 2 PB written), and has been overprovisioned for improved endurance: Capacity is 1.92 TB but only 1.60 TB has been allocated to namespace 1. Time to dig into man nvme, or whatever utility your current OS provides, to reset it. (I’ve done overprovisioning in CORE with nvmecontrol, quite some time ago…)
The second drive is new (86 GB written, i.e. nothing) and looks as expected. 1.92 TB = 1.74 TiB
Upon a quick look, I would issue sudo nvme format -l 1 /dev/nvme0
to all drives (should be nvme0 to nvme7) to make then 4k-native. I loathe 512-byte sectors. And the drive probably uses 4k or 8k underneath.
Thank You, I will give that a go and see if I can reset them to full capacity. Can you make a suggestion on how I should layout the drives, as in, how many vdevs for 8 nvme drives? 1 drive fault tolerance is fine for this application as the data is replicated to another server locally in Realtime and then to another server off-site, then additionally to Azure as well.
On the overall CORE vs SCALE discussion, I’d advise SCALE because we’re seeing better NVMe support (especially hot-swap) and performance under the Linux-based SCALE.
Try using the shell and issue the command sudo disk_resize nvmeX for one of the underprovisioned drives in question to see if it will reset the provisioning space.
How much capacity is required? Check the ZFS Capacity Calculator for the full breakdown, but with 8x 1.9T drives you could create
Given that you’re using iSCSI for your Hyper-V needs, you’ll also need to ensure that you set sync=always to have the data integrity guarantees for your cluster. This might slow your SSDs down as while the PM983 does have inline power-loss-protection it’s not a purely “write-optimized” drive.
Thank you for the awesome response. Everything you said makes excellent sense.
2 Questions, 1: When setting up the dataset, I have an option for “Record Size”, should I set this to something specific or leave it set to the default value of “128 KiB”?, 2: When setting up the zvol for the iSCSI share, is it okay to bypass the 80% limit and use more space or is it imperative to stay under the 80% limit?
You’ll need to set the Block Size on the zvols themselves. If you configure the pool as mirrors, I’d suggest 16K - if either RAIDZ configuration then consider 32K.
I would actually create multiple smaller zvols “on demand”, and ensure you create them as sparse so that you can reap the benefits of inline data compression.
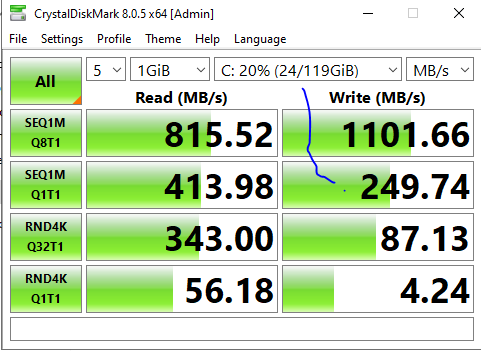
I have fixed all the drives to the correct size and setup a Raid-Z1 with 2 sets of 4 drives. I setup the ZVOL as instructed and setup the iSCSI share. I setup a temporary VM on the new storage and here are the test results I got from Crystal Disk Mark.
What do you think about the results? Again, the connection between the storage server and the node is 10gb. Any other tweaks you can recommend?
I assume you have only a single 10Gb uplink from each Hyper-V host, which lines up with the maximum sequential writes. I assume you set sync=always for the zvol?
The 4K write speeds are a touch pokey but because this is a single thread in a single VM from a single host it’s experiencing some write amplification especially in the RND4K Q1T1 test - multiple VMs across hosts should hopefully be able to be consolidated. There’s probably still gains to be had from a dedicated high-performance SLOG device such as an Optane P-series unit - if you have a 10-bay R640 you’ll have slots available for a U.2 device, but if you have an 8-bay then you might need to use a slot-based one (which means no hot swap) or potentially an Optane PMEM device.
When it comes to NVMe there’s also potential for things like power savings settings in the BIOS to have significant impacts. Dell documents some of this in a KB - you’ll want to look at the ones identified for “low-latency environments” and adjust towards those.