Thank you to anyone who responds and takes time to read my post. I have a TrueNAS Scale system that I’ve been running for nearly 3 years with no issues at all. First a quick breakdown of my system:
ASRock X570M Pro4 M-ATX motherboard
Ryzen 9 3950X (in ECO Mode)
64 GB of Kingston ECC RAM
6 8TB HGST Ultrastar He8 (HUH728080ALE601) drives for storage
2 Intel 240 GB SSD for boot
2 Intel P1600X 118 GB Optane Drives for SLOG
TrueNAS Scale 24.10.1
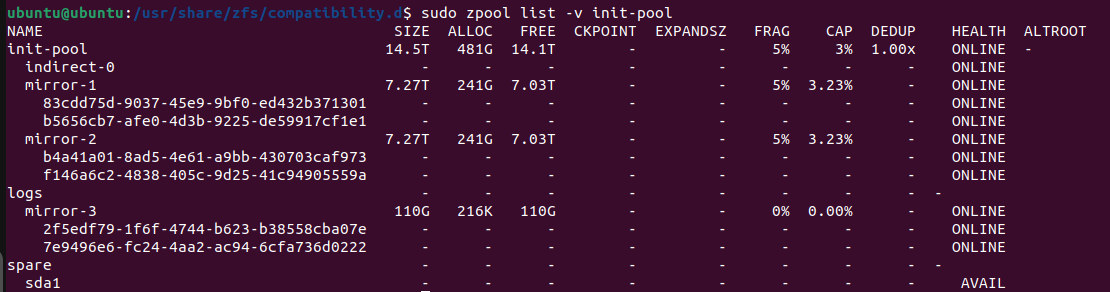
1 Pool with 3 mirrored VDEVs
About 7 or 8 days ago, one of my hard drives in one of the mirrored VDEVs went down, all the other drives were reporting back as good, so I decided to offline the drive and remove the VDEV entirely since my overall pool has enough storage space to absorb the data. I reassigned the now extra drive as a spare vdev for the pool. Everything seemed to run fine and I did a SMART test to make sure all the other drives were good, and a scrub to make sure the pool was still healthy - all checks came back with no errors. Then last night I was trying to access my SMB share and I noticed that it was inaccessible, so I tried to log in to the TrueNAS server and realized it was completely frozen. This is the first time this has ever happened, so I rebooted it and when it was starting it went directly into a Kernel Panic. I’ve tried to do research on what may be causing this issue but I haven’t been able to find much aside from one issue that seemed unrelated. So far the only troubleshooting I could think of is running a MEMTEST86 test to make sure the memory is good, but aside from that I don’t know what else to do. Any and all help would be greatly appreciated as this is my production system.
I also have a pool with an “indirect vdev” after doing a mirror vdev removal. It uses 9 MiB of RAM for the indirect mappings. I hope this does not mean my pool is also a ticking time bomb.
After the vdev removal, but before this kernel panic: Did you at any point delete any snapshots or files that might have contained data on the removed vdev? (Currently being mapped by the indirect vdev.)
EDIT: I’m on Core (FreeBSD-based), so it might not apply to me (yet).
Until someone with a deeper knowledge of this type of issue offers a troubleshooting avenue, are you able to download an Ubuntu ISO, boot from USB, and in the live session import the pool as “readonly”, to make sure that the pool itself is okay?
This might also clue you into whether it’s the pool itself, or a combination of “indirect vdev” + “TrueNAS SCALE (or Linux with a ZFS root system)”.
Hey! Thanks for reply and I really hope you don’t suffer the same fate as me, as there is almost nothing on the web that is any sort of help aside from the Bug Report that was basically dead until my post and may possibly not even apply.
As far as the conditions prior to failure, as I said I had 1 mirror vdev with 2 drives, one drive failed so I removed the whole vdev and used the good drive as a spare for the pool. I did this as precautionary measure in case any of the other drives started acting up while I waited for the replacement drive to come in. I performed the vdev removal from the UI, and I only did it after reading the documentation and making sure that it was going to be a safe operation. As I said the pool continued to work with no issues, all of my data was accessible (NFS for Proxmox, SMB for Syncthing, and SMB for Windows shares). My TrueNAS install and ZFS configuration was pretty vanilla aside from the Optane SLOG drives which I added to improve my VM performance over NFS. I wasn’t taking any snapshots but I did have one encrypted Dataset that had all of my picture backups. I hadn’t even deleted any large amounts of data. I think the weirdest thing about this is that the entire server crashed with no warning at all. Scale has been pretty rock solid since I started using it, and a vdev removal seemed like a pretty harmless operation, so this is super disappointing, especially if I lose all my data
This is really good idea. I’ll have to look up how to actually do it since I’ve only used ZFS with TrueNAS. My MEMTEST86 finished and it came back good so I guess it’s definitely not a memory issue
The files and folders should be browseable (whether in a terminal or file manager) from this location in the filesystem: /<poolname>/
You might bump into permission issues, though. The Ubuntu live user UID is 1000, but I think SCALE’s default UID starts at 3000 for newly created users. (If your permissions were restrictive, you might have to browse the files/folders as the root user in the live Ubuntu session.)
I really appreciate it!!! I’ll give it a shot tomorrow to see what happens. I wonder how I would access the encrypted Dataset, but I guess first step is to see if I can even access the pool in general.
And yeah, hopefully an OpenZFS expert or someone from iXSystems that has seen this issue before can chime in with some recommendations.
Passphrase, was scared to lose my keyfile, which I would have stored in VaultWarden which would have had it’s disk in my NFS dataset. I guess I was right to not use a keyfile lol
So I was able to mount my pools using Ubuntu Live boot, and everything looks good. I ran a scrub on my boot and storage pool and no errors were found. Tried to reboot and it failed with the same error from the original screenshot.
The issue seems to be related to the indirect-0 device, which from everything I found online says that it is a “ghost” device that ZFS creates as a pointer for the VDEV that was removed. The reason I think they’re connected is because the error states “PANIC at vdev_indirect_mapping.c:528”, however, I have no clue where to go now, especially since everything is my pool is showing as healthy.
This indicates that it’s not likely the pool itself that is the cause of the kernel panic on your TrueNAS SCALE server.
So this still leaves these possible culprits, in combination with the presence of an “indirect vdev”:
version of OpenZFS
version of Linux kernel
version of TrueNAS SCALE and/or the kernel which it runs atop
combination of two or three from above
The presence of an “indirect vdev” and a pool imported in a writable state might also contribute to this issue.
I didn’t have a chance to reply sooner, but can you still try a few more things? I am very unlikely to help, but I will summarize what’s going on and try to get others to help, as well as something that you can point to in a bug report.
Boot back into the Ubuntu live session
Print the kernel version: uname -r
Print the version of OpenZFS: zfs --version
Import the pool as writable: zpool import -d /dev/disk/by-partuuid init-pool
Does the system crash? Does the pool report any errors?
You do not need to import the boot-pool.
I have the same thing, but never once faced a kernel panic. I am on TrueNAS Core 13.3-U1, based on FreeBSD 13.3.
Between you and someone else, a common denominator seems to be that you were both using SCALE. (If I am remembering correctly.)
To confirm, you mean you rebooted into TrueNAS SCALE?
Hi @winnielinnie thanks for the reply and no worries at all, I appreciate the help!
The kernel version is 6.8.0-40-generic
the zfs version is zfs-2.1.5-1ubuntu6~22.04.4 and zfs-kmod-2.2.2-0ubuntu9
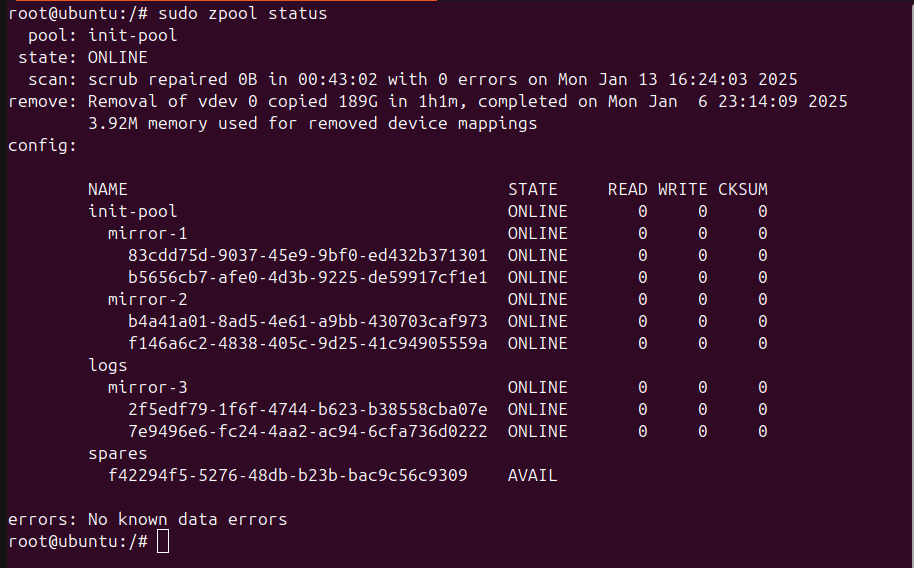
When I imported the init-pool using the command you provided, it mounts just fine and when I run zpool status, everything seems to be fine and the pool doesn’t report any errors. My vdevs all show ONLINE with 0 errors.
Yes, after I poked around using the Ubuntu Live environment, I removed the USB and rebooted into the original TrueNAS SCALE environment which led to the same kernel panic as before.
While in the Ubuntu Live environment I had no kernel panics and I was able to browse my data. I was even able to access my encrypted dataset with no issues.
It’s not that I want to crash your system, but that’s a two-year old version of Ubuntu, with an OpenZFS version of 2.1.x instead of 2.2.x. (Very notable difference.)
EDIT: Just noticed it’s using an older version of zfs-utils compared to the zfs module.
I would repeat the above, but with Ubuntu 24.10, for something closer to the current iteration of SCALE.
After this, I’ll summarize something that you (and others) can refer to.
I probably would have suggested something like: mfsbsd; I’m not saying there’s 100% truth to the “ZFS is baked into FreeBSD vs Linux aftermarket…” but wouldn’t hurt to eliminate any possibility of that argument and get a more recent zfs version as well. I mean, we KNOW zfs on FreeBSD is solid so why not eliminate that from the equation.
So Ubuntu 24.10 did not want to boot, it would just give me a a long loading screen then it would just turn to a black screen with a mouse pointer. So I tried Ubuntu 24.04.1 LTS which worked.
kernel is 6.8.0-41-generic
zfs is zfs-2.2.2-0ubuntu9.1
zfs-kmod-2.2.2-0ubuntu9
I imported the pool with no issues and I did a zpool status and everything came back as healthy.
It can hopefully be used to get further help and troubleshooting from someone else, as well as refer to it in a bug report.
Your TrueNAS system is:
– SCALE 24.10.1
– Linux kernel 6.6.44
– Open ZFS 2.2.99 (2.3.0 pre-release)
You had recently removed a mirror vdev, which created an “indirect vdev” in the pool.
Every time you reboot, your SCALE system crashes with a kernel panic.
The panic seems related to the indirect vdev.
– PANIC at vdev_indirect_mapping.c:528:vdev_indirect_mapping_increment_obsolete_count()
This was also experienced by a Fedora Linux user with kernel 6.5.12 and OpenZFS 2.2.1.
– A third user affected by this is on SCALE (version unknown), who also removed a mirror vdev which resulted with an “indirect vdev” in his pool.
– All three users that suffer this kernel panic have a pool with an “indirect vdev” (after having removed a mirror vdev).
– OpenZFS bug report link
There is nothing wrong with the pool itself, as its status is “HEALTHY” and it is fully importable in a recent Ubuntu distro without issues.
You are able to import it and access the data within, using an Ubuntu live session on the same hardware (NAS server).
– Ubuntu 22.04 and 24.04
– Linux kernel 6.8.0
– OpenZFS 2.1.5 and 2.2.2
I also have an “indirect vdev” in my pool, but never faced this crash on my TrueNAS Core system.
– TrueNAS Core 13.3-U1
– FreeBSD kernel 13.3
– OpenZFS 2.2.4
Some further observations:
A common denominator between you and the other users is that the kernel panic happens on Linux kernels older than 6.8. When using 6.5 or 6.6, him and you face a kernel panic. When you imported the pool in 6.8, everything was fine, and the pool and its contents were accessible.
All three users have “indirect vdevs”.
It could be a red herring, and using a Linux kernel earlier than 6.8 might just be a coincidence.
It’s not ruled out that you wouldn’t see this kernel panic on an older version of SCALE.
Booting into SCALE 24.04 also results in the same kernel panic.
It’s not ruled out that you wouldn’t see this kernel panic if you were able to boot into SCALE without any imported/active pools, which you can later attempt to manually import.
It’s not ruled out that you wouldn’t see this kernel panic on a version of Ubuntu that ships with Linux kernel 6.6 or earlier.
I would file a bug ticket and point them to this post.
Thanks so much for the recap @winnielinnie, that captures everything perfectly except I did just attempt to boot to an older version of TrueNAS Scale. It was version 24.04 which was still on my system, however, as with version 24.10.1 it crashed with the same kernel panic.
Thank you so much for the help, I really appreciate it!
@pncv87, do you have a spare SSD to install a nightly release of TrueNAS Fangtooth (25.04)?
I wouldn’t recommend using the current system’s boot-pool SSD(s), since doing a new install will wipe the older boot environment.
If you’re able to: Install Fangtooth on a spare SSD, boot into it, and then simply try to import the pool “init-pool”. No need to upload a config file or setup any services or shares. Bare minimum, just to see if you can import the pool.
Just be careful when you do a fresh install, and don’t point the installer to your current boot drive SSDs.