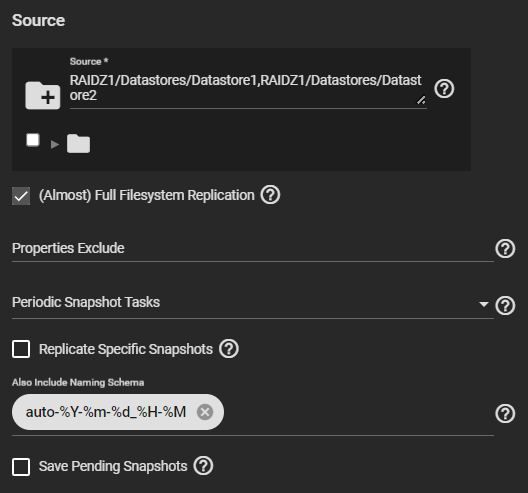
All of a sudden, my snapshots are not being deleted. To double check, I created new dataset, and a new snapshot task where they are supposed to be removed after an hour, and they are not being removed. There are no replication tasks associated with my new test dataset.
Snapshot list for test dataset where many should be deleted by now:
RAIDZ1/Test@auto-2024-04-27_15-00 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-05 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-10 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-15 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-20 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-25 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-30 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-35 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-40 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-45 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-50 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_15-55 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-00 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-05 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-10 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-15 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-20 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-25 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-30 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-35 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-40 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-45 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-50 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_16-55 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-00 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-05 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-10 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-15 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-20 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-25 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-30 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-35 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-40 0B - 140K -
RAIDZ1/Test@auto-2024-04-27_17-45 0B - 140K -
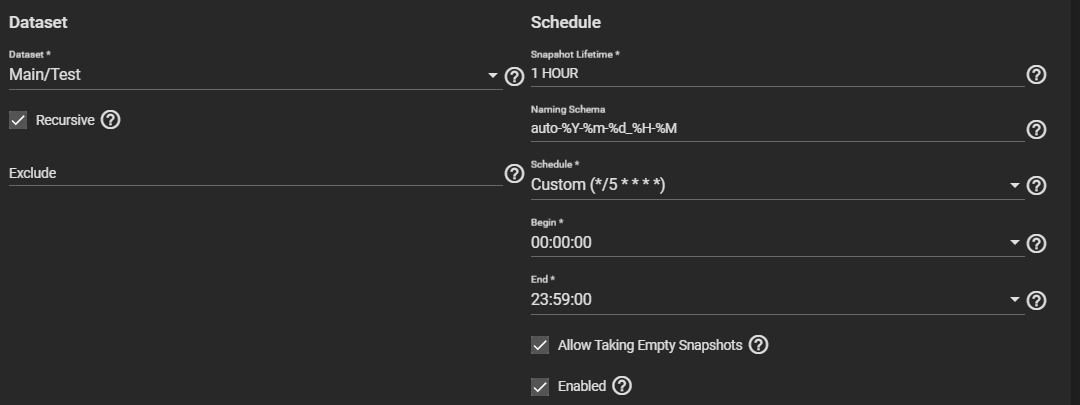
These are the settings for the snapshot task:

Not sure if it’s the right log, but zettarepl.log shows the snapshots being created, but never deleted:
[2024/04/27 17:15:00] INFO [MainThread] [zettarepl.zettarepl] Created ('RAIDZ1/Test', 'auto-2024-04-27_17-15')
[2024/04/27 17:20:00] INFO [MainThread] [zettarepl.zettarepl] Scheduled tasks: [<Periodic Snapshot Task 'task_45'>]
[2024/04/27 17:20:00] INFO [MainThread] [zettarepl.snapshot.create] On <Shell(<LocalTransport()>)> creating recursive snapshot ('RAIDZ1/Test', 'auto-2024-04-27_17-20')
[2024/04/27 17:20:00] INFO [MainThread] [zettarepl.zettarepl] Created ('RAIDZ1/Test', 'auto-2024-04-27_17-20')
[2024/04/27 17:25:00] INFO [MainThread] [zettarepl.zettarepl] Scheduled tasks: [<Periodic Snapshot Task 'task_45'>]
[2024/04/27 17:25:00] INFO [MainThread] [zettarepl.snapshot.create] On <Shell(<LocalTransport()>)> creating recursive snapshot ('RAIDZ1/Test', 'auto-2024-04-27_17-25')
[2024/04/27 17:25:00] INFO [MainThread] [zettarepl.zettarepl] Created ('RAIDZ1/Test', 'auto-2024-04-27_17-25')
[2024/04/27 17:30:00] INFO [MainThread] [zettarepl.zettarepl] Scheduled tasks: [<Periodic Snapshot Task 'task_45'>]
[2024/04/27 17:30:00] INFO [MainThread] [zettarepl.snapshot.create] On <Shell(<LocalTransport()>)> creating recursive snapshot ('RAIDZ1/Test', 'auto-2024-04-27_17-30')
[2024/04/27 17:30:00] INFO [MainThread] [zettarepl.zettarepl] Created ('RAIDZ1/Test', 'auto-2024-04-27_17-30')
[2024/04/27 17:35:00] INFO [MainThread] [zettarepl.zettarepl] Scheduled tasks: [<Periodic Snapshot Task 'task_45'>]
[2024/04/27 17:35:00] INFO [MainThread] [zettarepl.snapshot.create] On <Shell(<LocalTransport()>)> creating recursive snapshot ('RAIDZ1/Test', 'auto-2024-04-27_17-35')
[2024/04/27 17:35:00] INFO [MainThread] [zettarepl.zettarepl] Created ('RAIDZ1/Test', 'auto-2024-04-27_17-35')
The last time zettarepl.log shows local snapshots being destroyed was April 17th, which I believe was a day or two before I started the replication task that is currently running:
[2024/04/17 18:00:10] INFO [retention] [zettarepl.zettarepl] Retention destroying local snapshots: []
[2024/04/17 18:30:10] INFO [retention] [zettarepl.zettarepl] Retention destroying local snapshots: []
[2024/04/17 19:30:10] INFO [retention] [zettarepl.zettarepl] Retention destroying local snapshots: []
[2024/04/17 20:00:10] INFO [retention] [zettarepl.zettarepl] Retention destroying local snapshots: []
About 10 days ago I started a replication task on another dataset to a remote site. That task is still ongoing since the link is slow. I would think replication should be totally independent of snapshot deletion, unless “save pending snapshots” is selected on the replication task, which is of course not the case for a new dataset created specifically to test this. Thought I would mention it just in case.
Anyway, any ideas on why this would stop working all of a sudden?
Forgot to mention, I’m running Core 13.0-U5.3.