Hey all, I apologize if I’m not posting this in the correct manner. I need help with my server. I was copying some files over from windows and I come to find the whole system crashed. It was boot looping because, after watching it loop for a little while, I realized that when it was trying to import my Zpool, it would crash so hard that I just rebooted. No warnings no logs no nothing it just crashed. So I decided to take the OS drive out and install trunas on a fresh drive and see if I could just import it. Well, anytime I try to import it to any Installation the whole thing just crashes, no matter what.
Yes, I did try to import It read only which it did work. But I’m not sure what to do after that if I do it only because i Still can’t access it, Unless I am just not doing it correctly, which Very well could be the case. So my latest attempt at Trying to rectify this issue was running the ZDB – E command. And this was the end result.
So I’m stuck now. I don’t know where to go from here. Any help would be appreciative. Thank you.
My system:
Dell PowerEdge R510
No modifications.
Hardware raid is set to 8 individual drives. Truenas is what takes are of my raid.
8 3 TB drives
OS is on an SSD
Sorry I didn’t mean to say hardware raid. It’s running each drive as its own, I didn’t set it up as an actual raid. That’s what truenas is doing. I’m just using the controller to interface with the server since they’re all sas drives and I don’t have any other means to connect them.
You have to watch your terms here, zfs is not raid, quite a bit different. It has some similar qualities, but , not at all the same thing. I would suggest not using raid as a term on the forums.
What is your controller?
The error is corruption. This super rarely happens, can be for a variety of causes, memory, cabling, controller firmware, power failure without a UPS maybe, and the least likely, a zfs bug. Probably some others as well.
Read only is a good thing, if you don’t backup (a very bad idea) then at least you could copy stuff off somewhere and remake the pool. I am doubting there is a way to fix this. Listing all your hardware with model #'s might help with advice, and, you will likely want to do testing of your equipment before putting it back into use. So, memory tests, controller up to date firmware, drive burn in tests.
If it were me, I’d probably also ask on reddit, in the zfs sub.
Ok thank you, I appreciate the help, and your patience with my slight ignorance to the nomenclature. I was only trying to explain (what I thought) I had set up. So ZFS is not a type of software raid? After looking it up I’ve found that it’s a filesystem and a raid wrapped together? Is that true?
As for the server, I’ve already started an extended hardware diagnostics that’s built in to the server. I’ll update my signature to reflect my current set up.
Oh and I forgot to mention that yes I had a slight brown out occurred without it being on a UPS, but I didn’t encounter any issues until I copied a large amount of files over. That’s when this all began. Oh and my controller, I’ll need to double check what it is after the diagnostics is complete.
ZFS is similar to software RAID but with many additional features RAID does not have. It is typically more resilient than software/hardware RAID for a variety of reasons. There are a lot of differences but that’s beyond my ability to type. It’s an entire subject by itself. For simplicity, you may consider it a type of software raid.
Will wait for your report. A UPS is (almost) a requirement. A UPS that is preferably NUT (network UPS tools) compatible.
For your array, is it a 4 mirrored vdevs (groups) of drives, is it a single vdev (group) of 8 drives, and if so, how many parity (so, it would be a raidz1, raidz2, or raidz3.
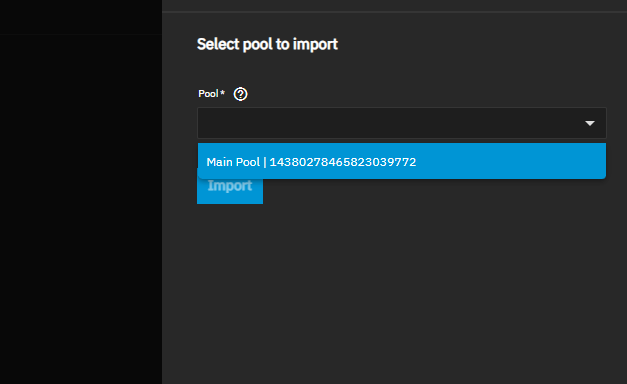
I have it on a UPS now, and the diagnostic came back clear. No issues. And it’s a single vdev of 8 drives, I have included a screen shot of the web interface, I was able to boot into an environment that doesn’t have it imported, and it seems to all be there.
So, are you still stuck then? Does it import? Not sure what environment you are in. So, you have a Raidz1 pool. With a so called cache drive, which isn’t a “normal” cache drive, it’s l2arc, which is almost never necessary. Did you have a reason you added it?
I am not familiar with an H700 raid card, but, according to posts I read about core, it is not really a recommended card, in fact, those folks say not to use it. Scale is typically not different in this respect, may be the source of your issues. Here’s one thread about it you may want to read:
You may also want to do a smartctl -a on each of your disks and if you can attach.
Here is another thread:
ZFS is picky about disk controllers and wants a real HBA. The recommended cards are LSI and all their various names like avago, etc.
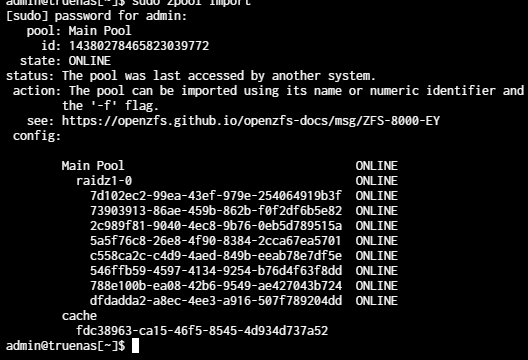
Nope, no success. I tried to import the zpool and it crashed. No warnings, no messages, no nothing. Just straight up rebooted after locking up for a second. Now, what’s different is that the system was able to reboot successfully. Before now, anytime I tried to import the zpool the whole install wouldn’t boot since it would lock up and crash at the initial loading of said pool. This time it booted to the console like normal. I’m going to assume the pool didn’t import and no config was saved, which it didn’t try to load? And the controller that came with this server is what was already installed - I didn’t add anything except the HDDs, which were an upgrade. The cache however I did add, and I’ll be honest - I’m not sure why. I initially wanted to run the OS off it, but trunas didn’t like it. So I opted for another SSD I had laying around. Once I get this back up and running, I’ll remove the cache drive.
Ok, well I gave up, since this is taking up too much of my time. I realized what I had done wrong. Mostly because, I’ll be honest, I’m new to this sort of set up. So I had just bought an actual rack mountable server not too long ago, and have no idea how to set the thing up. It came with a dell H700 Integrated/Adapter, which I didn’t know how to use or set up, so I just made 8 vdevs on it and used those to make my pool in truenas. Looking back on it, I feel extra stupid for not changing it’s mode to HBA and just passing it straight to the host. But I also didn’t really know what I was doing then either. Since then, I was able to make a new pool using an HBA I got off amazon, having 2 x RAIDZ1, each 4 drives wide, with each drive being 5.46 TiB, giving me roughly 30 TiB of data storage. And now I can actually use the filesystem properly. I think my previous set up prevented me from using some of zfs’ data retention and error correcting features. But, thank you for your help, I do appreciate it! Deff a lesson learned here.