I’m not sure what you mean “create a dataset off the main pool” ?
I have 1 pool - 2 x 10TB
1 Dataset
5 users and 5 shares
This is just for personal use with family. No need for quotas. I’ll just smack the person if they use too much ![]()
I’m not sure what you mean “create a dataset off the main pool” ?
I have 1 pool - 2 x 10TB
1 Dataset
5 users and 5 shares
This is just for personal use with family. No need for quotas. I’ll just smack the person if they use too much ![]()
So it’s always best practice IMO not to use the default ‘main’ dataset that it auto created when you first build your pool. This is what you are currently doing. To not do this you would need to create a new dataset give it a name and then do everything you had already done again but from within that new dataset. This it not mandatory but I would strongly recommend it. It looks like SCALE has the ability to manage users quotas from your screenshot so if that works well no need for a datasets per user if it’s just quotas you wanted.
Can I ask why it’s best to not use the default ‘main’
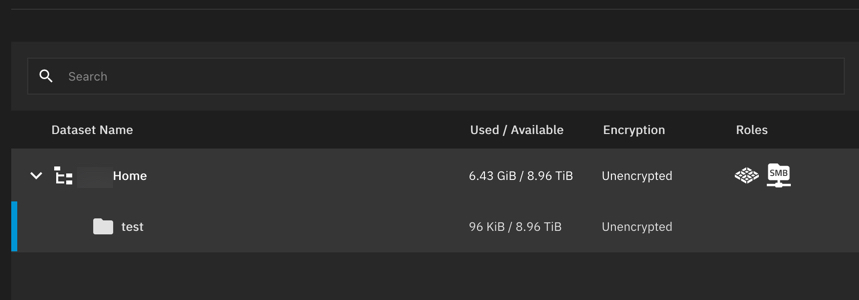
Is this the better way with test nested inside?
Appreciate all your help, Thank you
Perfect. There are lots of reasons but in short the default dataset that is created when your pool is created is given the same name as your pool which is why this is a little confusing. This is your root dataset for the pool and it is best practice not to store your data in the root dataset. Feel free to create however many datasets you like and store data in them just avoid doing that directly in the root dataset of the pool. Don’t forget to setup your snapshot schedule once your all setup and point it at your new dataset.
Confused again.
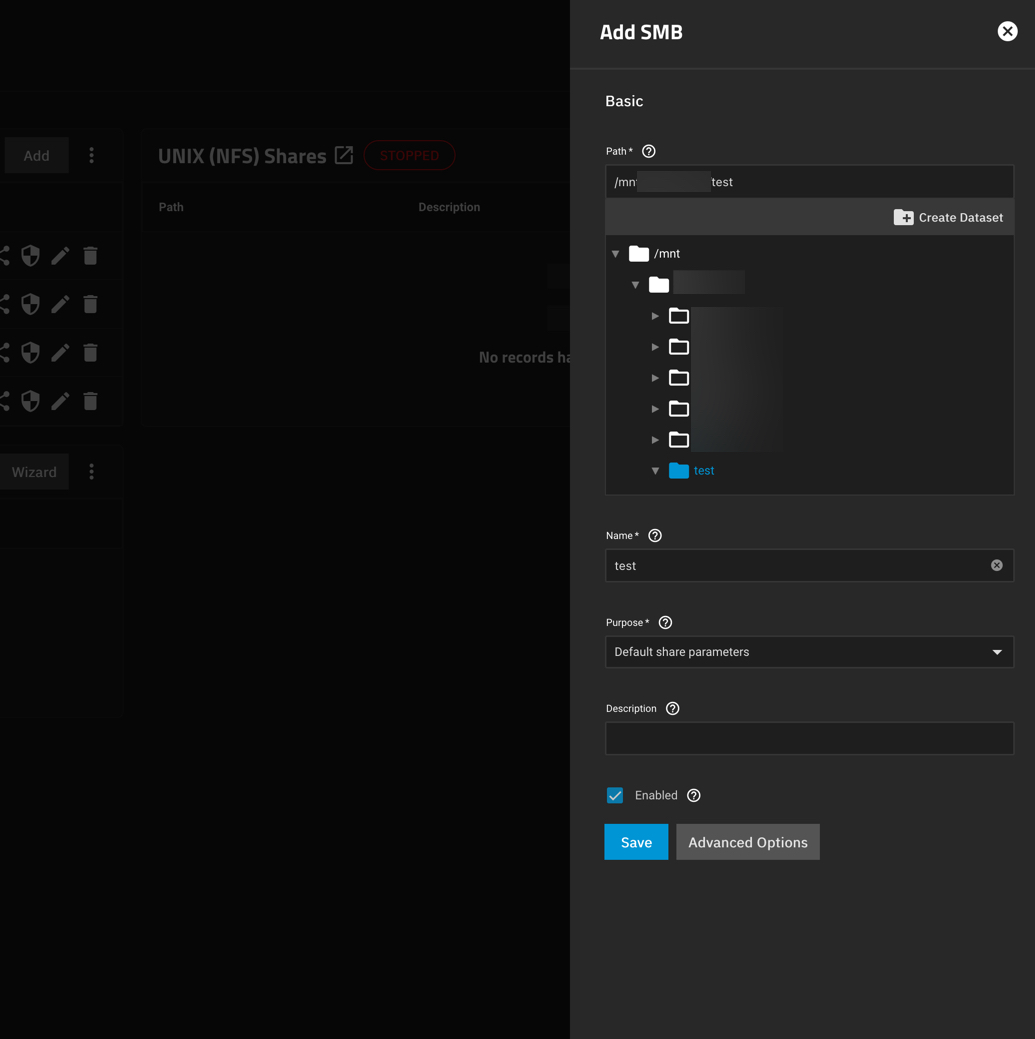
Now that I created a nested dataset, do I have to recreate my SMB shares to use that new one called test?
Yep you got it
Yup ![]()
Appreciate all the Farts, Johnny.
![]()
![]()
![]()