Just created a simple 10tb mirror - 2 disks. I understand this is not optimal as I loose 50% of the capacity but I don’t have a lot of data and value the safety of it. RAID concerns me as the complexities outweig the benefits for me.
Wanted to ask if I set things up the right way
Set up the Mirror
Created a Dataset that encompasses the entire space (9.9TB)
Then dropped to command line and created
/mnt/
/user1
/user2
/user3 etc
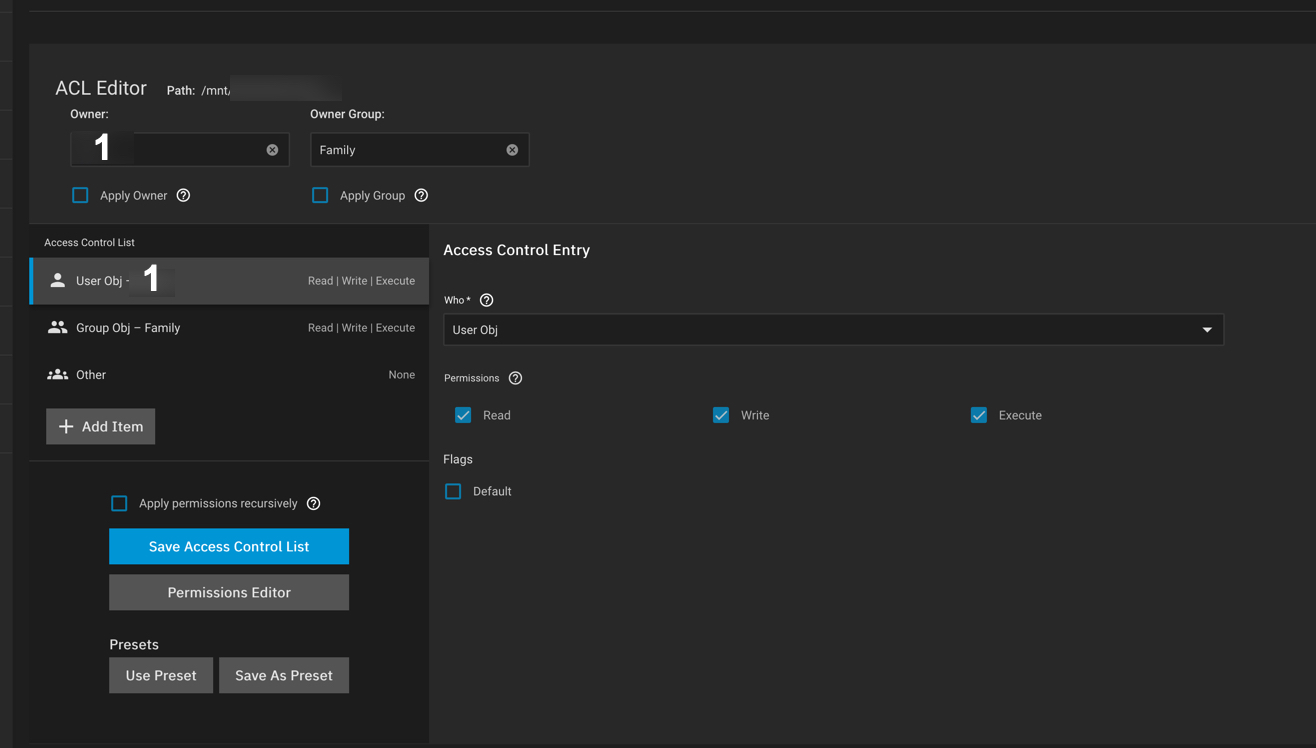
Then I created the users. Set their homes to those folders. Adjusted the ownership of the folder and only allowed those users access and not the entire family group.
I"m using Scale. I used the command line to create the directories that I want each user to put their data into. I couldn’t find a way to do it in the UI…
Is there anything wrong with making one big dataset and make shares in it? I’m not sure i’m getting the point of all the extra dataset work when it’s just for use files?
No issues destroying the pool as i’ve just been doing SMART tests and burn in so far ~3 weeks.
RAIDZ is what i’m looking for, I think per this. Just 1 drive, and 1 drive parity
It you want to have different ACLs you have to manage them from the WebUI in order to avoid issues, and this forces you to use datasets instead than simple folders. Not sure if I was clear.
Mirrors are a thing, RAIDZ1,2 and 3 another.
As far as I understood you wanted to go with mirrors which is fine.
/mnt should already have been there.
Where exactly did you put the userX folders?
Like this: /mnt/user1
or this: /mnt/yourpool/user1
?
One thing to keep in mind is that snapshots are on the dataset level, so in your case it looks like it’s all or nothing; you can’t selectively snapshot user1 separately from any other user.
Finally, a clarification; you don’t set the size of datasets beforehand. A dataset is not a volume. Whatever storage space is available according to your vdev configuration will be available to all created datasets. If you absolutely must put in restrictions, you can do so with quotas.
/mnt was already there.
I created /mnt/poolname/userX
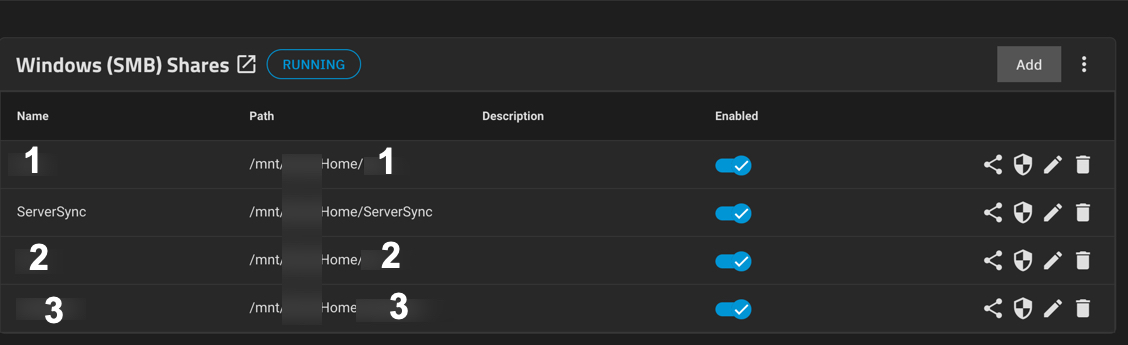
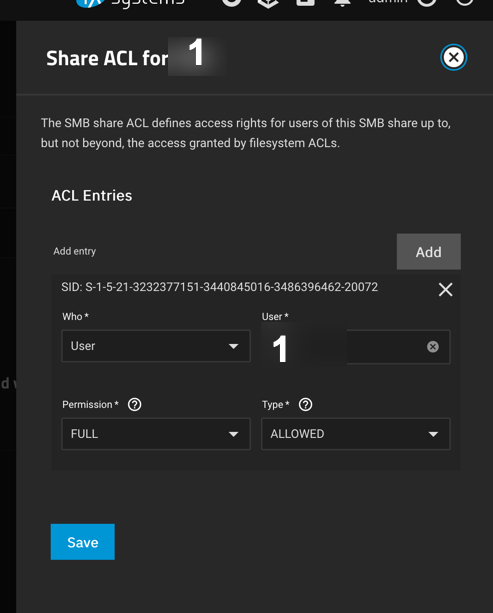
Then crated a share point to that mnt/poolname/userX. Then added permissions for that user.
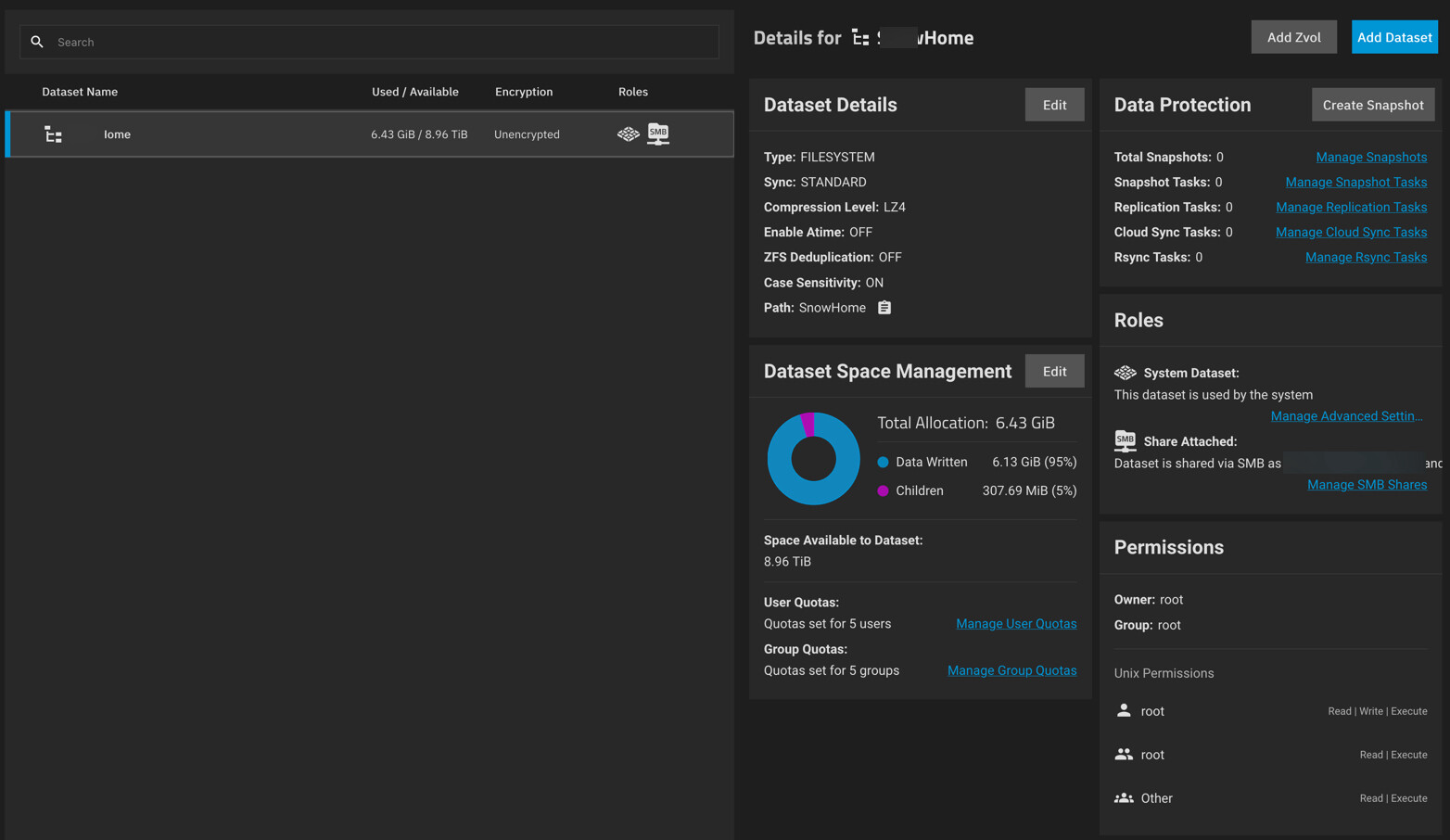
On the dataset piece, i’m brand new to this, I thought a datasat == pool size. Sounds like a dataset is just a referencable name for a container storing user data.
Is there something wrong with how i’ve done it as opposed to each user having it’s onw dataset? Just the backup issue? With Davvo’s explanation and the suggestion to rebuild my system, I think i’ve stuff up somewhere.
Not sure I agree with this. I can’t see a protocol mentioned in this thread but if using SMB then it’s perfectly feasible to create one dataset and then permission directories within it ideally managed via a Windows client as it’s less messy than the CLI.
Cool. Datasets are control points where you want to change a property like quotas for example or compression or isolate a chunk of data so it meets a specific snapshot schedule or replication task.You don’t need a dataset every time you want permissions to work differently.
Mistake in my wording. I should have said snapshots.
Per Neofusion
“One thing to keep in mind is that snapshots are on the dataset level, so in your case it looks like it’s all or nothing; you can’t selectively snapshot user1 separately from any other user.”
This is very true but so long as you are happy for all your directories within this dataset to fall under the same snapshot then no issues at all. I would suggest that it makes a lot of sense to have a single snapshot schedule on a single dataset to cover lots of users and directories. You will still have the ability to recover individual files and folders from within the snapshot for each of the user’s directories so I can’t see an issue here. In my organisation I create a dataset per group (I work in a University so that may be a lab of between 1-20 people). Then I create a directory structure to meet their needs and permission it off as required. Some datasets or only 1TB in size while others can reach 120TB in a single dataset.
Yeah sorry dude but you are confusing two different things here. Your Mirror provides you with redundancy if/when one of your hard drives fail so you don’t lose all your data. A snapshot gives you the ability to recover data from within a given dataset in the event of accidental or malicious deletion. Snapshots are a bit like time machines for your data. Have you ever deleted a file or folder by accident? If so this is where snapshots can help.
Maybe a silly question but if I a 10Tb drive in a mirror, I’m effectively 50% of actual storage. If I then do snapshots of the 10TB dataset, I could be reducing even further right?
Lastly, just to confirm that the way I set up my 1 big dataset and each user has their own folder (only 5 users) is ok?
Snapshots consume almost zero space until the data starts to diverge. In plain English don’t worry about it. Setup a snapshot schedule point it at your dataset and make it run every day for 2 weeks and you’ll be golden.
Show me your dataset layout in your pool so I can be sure. Nothing wrong with what you’ve done the only thing I always suggest is not to use the first default dataset and instead create a new one off it. Lots of reasons for this but I won’t go into them here.
Ok. Personally I would always create a dataset off the main pool and use that. Mostly it’s fine and I’m sure many people have setups like this but it can come back to bite you later down the line if you start getting into things like replication. I would suggest you create a new dataset off the main one called whateveryounlike and then setup your users there. Remember if you want users to have individual quotas then it’s best/easier to give them their own datasets but if that is not needed then go ahead and create your directories and permissions.