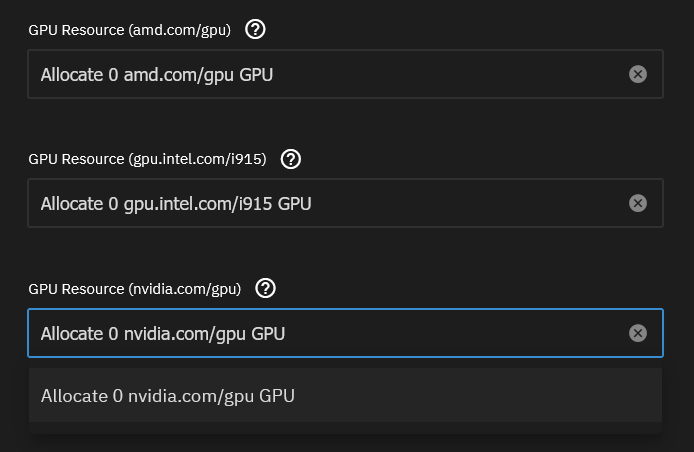
I’m on Dragonfish 24.04.0 running on a Dell R740xd with an nVidia P4000 GPU. I’ve got almost all of my ARR stack installed (via native charts), but I’m struggling with the Plex app. In the section to assign GPU resources, it shows 0 available nVidia GPU’s. When I run nvidia-smi from the shell, it shows I have a P4000 running. lspci shows the card, too. dmesg shows the driver loaded.
I have “Enable GPU Support” checked in Apps->Settings->Advanced and have no isolated GPU devices defined. Just for grins, I made sure the GPU showed up in the isolated GPU PCI ID list, but did not configure it.
I’m perplexed as to how to further troubleshoot this and would appreciate some insight from the community. Any ideas? Thanks in advance!
Sounds a bit like same problem I have: Cannot assign GPU to App - nvidia-device-plugin CrashLoopBackOff
I’m hoping 24.04.1 later this week will fix this, but as it is not accepted as a problem på ix i stil think it will not.
If you create a support ticket, ix might at least her convinced its a problem and start finding a solution.
Can you check what the nvidia-device-plugin pod is showing as status?
Use the command:
k3s kubectl show pods -n kube-system
Yup. I think we’re experiencing the same problem. Here’s the pertinent section from my log (I had to remove some dots to strip the links because noobs can only post two links in a post):
Name: nvidia-device-plugin-daemonset-br4g2
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Runtime Class Name: nvidia
Service Account: default
Node: ix-truenas/10.1.2.100
Start Time: Sun, 26 May 2024 19:23:49 -0700
Labels: controller-revision-hash=959889769
name=nvidia-device-plugin-ds
pod-template-generation=1
Annotations: k8sv1cnicncfio/network-status:
[{
“name”: “ix-net”,
“interface”: “eth0”,
“ips”: [
“172.16.10.91”
],
“mac”: “36:2e:13:77:59:cc”,
“default”: true,
“dns”: {},
“gateway”: [
“172.16.0.1”
]
}]
scheduleralphakubernetesio/critical-pod:
Status: Running
IP: 172.16.10.91
IPs:
IP: 172.16.10.91
Controlled By: DaemonSet/nvidia-device-plugin-daemonset
Containers:
nvidia-device-plugin-ctr:
Container ID: containerd://66cd48edfad1d4f19b56e9344818636fbc46fb85acdea0d4d62d0a5e14f00eeb
Image: nvcrio/nvidia/k8s-device-plugin:v0.13.0
Image ID: nvcrio/nvidia/k8s-device-plugin@sha256:e8343db286ac349f213d7b84e65c0d559d6310e74446986a09b66b21913eef12
Port:
Host Port:
Command:
nvidia-device-plugin
–config-file
/etc/config/nvdefault.yaml
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 27 May 2024 06:38:09 -0700
Finished: Mon, 27 May 2024 06:39:22 -0700
Ready: False
Restart Count: 111
Environment:
Mounts:
/etc/config from plugin-config (rw)
/var/lib/kubelet/device-plugins from device-plugin (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wk4qv (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
device-plugin:
Type: HostPath (bare host directory volume)
Path: /var/lib/kubelet/device-plugins
HostPathType:
plugin-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: nvidia-device-plugin-config
Optional: false
kube-api-access-wk4qv:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional:
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors:
Events:
Type Reason Age From Message
Normal AddedInterface 59m multus Add eth0 [172.16.10.82/16] from ix-net
Normal SandboxChanged 52m (x104 over 11h) kubelet Pod sandbox changed, it will be killed and re-created.
Normal AddedInterface 52m multus Add eth0 [172.16.10.83/16] from ix-net
Normal AddedInterface 47m multus Add eth0 [172.16.10.84/16] from ix-net
Normal Pulled 42m (x106 over 11h) kubelet Container image “nvcrio/nvidia/k8s-device-plugin:v0.13.0” already present on machine
Normal AddedInterface 41m multus Add eth0 [172.16.10.85/16] from ix-net
Normal AddedInterface 34m multus Add eth0 [172.16.10.86/16] from ix-net
Normal AddedInterface 28m multus Add eth0 [172.16.10.87/16] from ix-net
Normal AddedInterface 21m multus Add eth0 [172.16.10.88/16] from ix-net
Normal AddedInterface 15m multus Add eth0 [172.16.10.89/16] from ix-net
Normal AddedInterface 8m54s multus Add eth0 [172.16.10.90/16] from ix-net
Warning BackOff 7m54s (x2624 over 11h) kubelet Back-off restarting failed container nvidia-device-plugin-ctr in pod nvidia-device-plugin-daemonset-br4g2_kube-system(c445f15c-f127-4b7d-894c-ebb7059eb8ba)
Normal Killing 2m36s (x112 over 11h) kubelet Stopping container nvidia-device-plugin-ctr
Normal AddedInterface 2m26s multus Add eth0 [172.16.10.91/16] from ix-net
Also, when I run k3s kubectl describe nodes I see the GPU’s as able to be assigned.
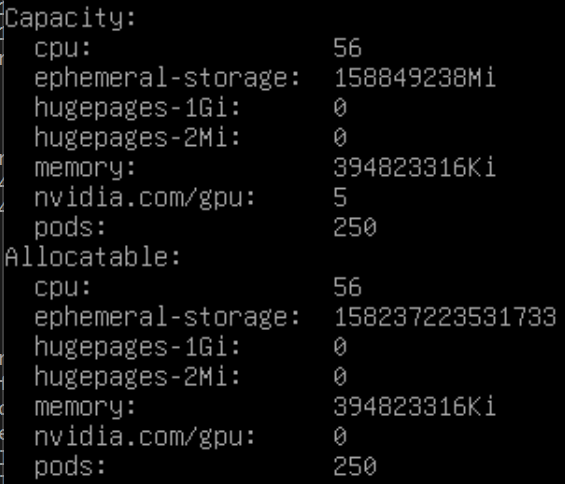
Unfortunatly on my side it show no available GPUs allocatable, so might not be the exact same problem.
Event though we have the same CrashLoopBackOff
@fayelund I just upgraded to 24.04.1 and now have access to the GPU’s. I hope your problem is also resolved. Good luck!
You lucy dog, unfortunately no joy here 
Sorry to hear that! Which GPU are you running?
I’m running a P4000 in case anyone who experiences this problem in the future finds this thread useful. Thanks for the help, @fayelund.