Hello there,
I am currently running Electric Eel 24.10.0
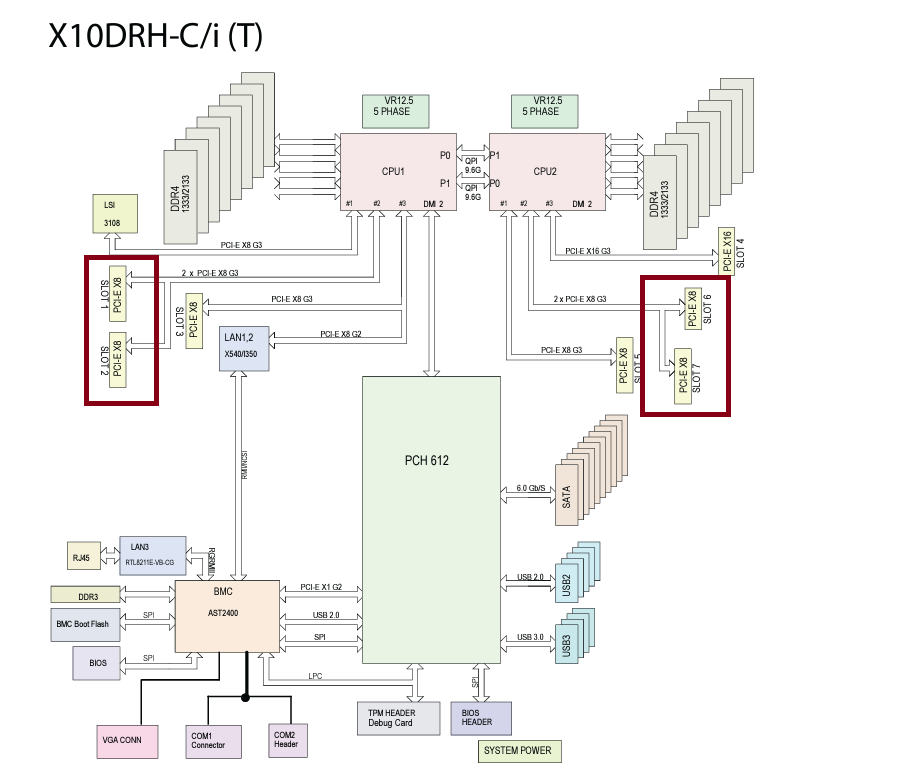
MB: X10DRH-iT
CPU: 2x E5-2699v4
RAM: 512GB DDR4
Disks Pool1: 30x 8TB in 5 x RAIDZ2 | 6 wide
Disks Pool2: 4x 4TB Samsung 990 PRO w/ Heatsink in Raid Z1
Problem only seems to be on the NVMe pool2.
NVMe Raid Z1 created using (2) AOC-SLG3-2M2 with 4x4 bifurcation.
After about 36-48 hours my Raidz1 goes degraded (only the nvme pool, the normal pool is fine), each time the disk which drops out is random and states that its been removed by admin. A reboot fixes the issue and brings the RAIDZ1 back to healthy status.
- Disk Samsung SSD 990 PRO with Heatsink 4TB S7DXXXXXXXXXXJ is REMOVED
Disk temps 28C well below limit. So I know its not a temperature issue.
I have tried a different motherboard and have tried different NVMe bifurcation cards without any luck.
Any help is appreciated.
You will need to be very specific when it comes to hardware issues.
Which slots are filled and what is in those slots?
Which PCIe slots are bifurcated and exactly what is the format x4x4x8, x4x4, etc.?
When you say you have used other motherboards, which models? And was there anything common between these besides the PCIe cards to M.2 adapters and the NVMe drives?
So you are able to create a pool without issue it sounds like.
If you have ever used an earlier version of TrueNAS, was the system stable and which version of TrueNAS?
Have you run a SMART Long test on each drive?
When you say the drive that drops offline is random, it there any commonality? The same PCIe card or PCIe slot?
Have you moved the M.2 PCIe card to use PCIe slots (1, 2, 3) for CPU1, (4, 5, 6,7) for CPU2. Stay within the same group of slots for a single CPU, recommend using CPU1 to start with.
Did you know that there are a lot of PCIe timing adjustments with that BIOS? If yo have to use those, Google may need to be your friend.
When it comes to a hardware issue, it can take a lot of patience to figure out. Hopefully you will say that Dragonfish worked fine.
Best of luck. Time to hit the hay.
Both are IOU1 Channel 2 in x4x4x4x4:
CPU2 Slot 5 8x
CPU2 Slot 6 8x
I was using (4) 2TB in Cobia and upgraded to (4) 4TB just before upgrading to Electric Eel.
Alternate hardware tested on:
X11SPI-TF with 1x Xeon Gold 5215
Tested with both the (2) AOM cards and (2) 10Gtek adapters all with the same error after 36-48 hours.
The card that drops is random all 4 drives have dropped off over the last week.
I have not touched the timing. Bios is running defaults other than the bifurcation.
I have not moved the cards since it also happened in a completely different motherboard of a different generation and single CPU config I figured that eliminated the slots.
Sorry I didn’t get back to you sooner, I didn’t see this pop up 5 days ago.
Thanks for the answers and now for a few more questions…
- On the two AOC-SLG3-2M2 cards, which one is in which slot? Feel free to name them by the slot numbers for now.
- What is the configuration of the three jumpers for each one of these cards?
- Have you looked into these jumpers before to find out if they need to be changed or not? There three jumpers provide the SMB Bus address. The default setting in “A0”. You “might” need to change one of these but I do not have the personal experience here to know for certain.
- Did you follow the instructions in the AOC-SLG3-2M2 User Guide in section 3-3 (the second item listed)?
- You said you have 4x4x4x4 bifurcation setup, but that is only on a x16 slot and you are using x8 slots, so I just want you to verify this. The x8 slots in questions should be 4x4. I have to assume you have it setup correctly otherwise I don’t think all the drives would be recognized, only the first drive on each card would be.
My current advice:
Verify the bifurcation settings and only have those setup on two of the slots. Both slots should be 4x4. But let me switch this up… If your settings are correct, then I recommend moving the AOC-SLG3-2M2 card from Slot 6 to Slot 3. This will split the drives across two CPUs. See if this fixes the problem. We are trying the simple stuff first. But you must also setup bifurcation for slot now to 4x4.
Read the first entry in this forum link, it is very enlightening, well to me at least.
I hope relocating the one card and changing the BIOS bifurcation wil fix the problem.
Hello,
I have tried one in each CPU and it still drops the drive.
-
As of last night I moved them to slots 1 and 2 both in x4x4
-
The jumpers are in default config all on the left, per the manual as it states to not change them unless instructed otherwise.
-
I would need to further check on changing these.
-
Yes I did. It is unavailable in my bios.
-
Some slots link to the same channel so by default they would be x8x8 but since I am using both slots bifurcation, it is setup as x4x4x4x4. I have attached a photo. Using the manual photo it is easy to tell which settings in the bios go to which port.
At the minimum the bifurcation is setup correctly or we couldn’t see all the drives. But timing could be an issue. (all of the current timing in bios is set to default auto).
As mentioned before I have also tried JEYI adapters and getting the same results. I have also tried putting a 4 port JEYI in the x16 slot in x4x4x4x4 and the drives STILL drop on the same card same channel.
At this point my guess would be something in Cobia or something not being able to handle the 4TB 990 pros vs the old 2TB 990 pros which worked.
Also running dragonfish before with (4) 2tb nvme 990 pro had 0 issues.
What I have done since last night:
Booted into 24.04 and destroyed the pool and recreated.
We will see if it drops out over the next 2 days or so.
When you said that slots 1 and 2, 6 and 7 were 4x4x4x4 because they are actually a x16 split into two x8 slots, that makes more sense to me. I was curious why they drew the diagram that way.
I have six 4TB NVMe drives in my system, one is the boot drive for ESXi, the other five are passed through to a VM of TrueNAS. It all works flawlessly, well for my system. I have run on bare metal as well without issue. And I will be removing the 4TB Boot drive in favor of a 1TB SSD (SATA). This is so I will have one replacement drive should I need it, as you should know, drive capacities are not all the same. Similar yet but if the new drive is smaller by 1 byte, it will not work. So I will be sticking it into an ESD bag and securing it to the inside of the computer case. With my usage needs, I will never run out of storage space with 10TB of storage. That is just me.
While you are waiting to see if the system is stable, let’s look at this as if the drive may be bad… maybe we can prove it or rule it out.
First lets run a SMART Long Test, this is the command for SCALE nvme device-self-test /dev/sd? -s 2 where the ? is the specific drive id, and then wait at least 15 minutes. My 4TB NVMe drives take just under 10 minutes to complete but I have no idea how long yours will take.
Them post the output of smartctl -x /dev/sd? where the ? is the specific drive id. Place the output in code brackets to maintain the format of the output.
I can examine it and then we can take it from there. I almost want the drive to fail so you know it had nothing to do with your setup. Sometimes drives fail, sometimes right away.
While you are at it, are you certain the NVMe drive is not counterfeit? If you are not sure, feel free to “message” me a photo of the drive, front and back. Since it has a heatsink, this can be done at a later date if in question. I have personal experience purchasing a Samsung fake NVMe drive through AliExpress. I got my money back and returned the drive (they paid the shipping).
The drives are 100% authentic, we get them from our vendor and they check out in magician and are registered.
My first thought was also bad drives. We have about 50 of them for our dedicated servers so I swapped each as they dropped out and the new ones also drop out.
I will run the long tests just for sanity sake but I am almost certain the drives are good.
Have you tried contacting Samsung for support, in case this is a reproducible issue with these drives? I would expect they have more hardware to test it against.
Is there a Jira ticket with iX Systems? Maybe the debug dump would offer some clues.
Well this is not a good sign. Sounds like bad hardware, however as you suspected it could be the software you were running.
Let me ask you this question as it is really on my mind… You have a rather beefy two CPU server which is why I’m asking… Are you running TrueNAS on bare metal or on a hypervisor? I would think all that CPU power would be going to waste if it were just TrueNAS.
Truenas is running bare metal and we are using the virtualization for multiple VM/docker setup. And using the dual CPU setup on the X10 gives us one extra pcie slot vs the single CPU X11.
We have plenty of hardware so keeping things separate and on their own hardware sometimes makes things easier.
I am confident the NVMe drives and pcie cards are good because they are working just find in other servers not running zfs/Truenas.
I have tried two motherboards with the same issues. So at this point I have dropped back to booting 24.04. This should help me eliminate if it’s the Cobia upgrade. If it still drops out my next test will be a fresh Dragonfish install which worked on the 2TB drives.
SmallBarky:
Thank you for your assistance. Samsung was not any help, since the drives have latest firmware and pass their magician tests they pretty much washed their hands of it.
As for a debug ticket. I have modified the system with several debug tools so based on their rules it would not be accepted. If this build continues to fail I will do a fresh install which I can submit debug on from an unmodified install.
Hello,
Here are the smart results.
Everything looks good except the calculation on hours used on the first device shows 17 hours yet the current machine uptime is over 51 hours oddly.
So far I am running Electric eel with the pool created on Dragonfish and not upgraded like before.
So far we have a record, 48 hours + no drop but I am keeping my fingers crossed.
Your smart data is missing some stuff, it could be the drives don’t have it but here are two commands (only for scale):
nvme self-test-log --output-format=json /dev/nvme0
nvme error-log /dev/nvme0
And the invalid data in field messages will go away when smartmontools 7.5 comes out.
I don’t need you to post the data from the drives, it is something you can look at.
Well looks like luck ran out and I am back to the drawing board:
- Pool nvme1 state is DEGRADED: One or more devices has been removed by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state.
The following devices are not healthy:
- Disk Samsung SSD 990 PRO with Heatsink 4TB XXXXXXXXX is REMOVED
I am at a loss, the drives themselves seem to work fine in other non Truenas systems and it seems not to be MB or card related.
Thanks
Have you installed TrueNAS Dragonfly and performed a basic configuration, nothing more. Then import your pool. Do not configure SMB or other file sharing. Just let the thing sit there. No VMs. Does the system fail like that?
1 Like
I have not but I suppose I can, to do this I would need to reinstall Truenas under a hypervisor as I have other shares which need to be online. Or split the NVMe’s into another system entirely.
I will work on this.
Okay, well that isn’t the same. You said that you had other hardware that also failed, how.about setting one of those up instead?
Alright here is an update.
I setup the second server, it also failed with 24.04. So then I decided to test if its actually TrueNAS or not. I installed Proxmox and after 48 hours the zfs pool also failed.
While googling “990 pro drops from zfs” I can see a lot of people seem to be having issues with the 990 series in zfs.
So I think its safe to say that this is not a TrueNAS specific issue. I am guessing its most likely a firmware/hardware issue with the 990 devices themselves or an incompatibility of some sort with this specific NVME model.
I also setup a (4) drive raidz1 with (4) 4tb HP FX900 on the alternate hardware and it ran for the last 4 days without dropping.
So I guess its safe to say at this time don’t mix any 990’s with ZFS.
I have seen on the google search some people reporting success disabling the power states. So for the sake of completing the experiment I will try this and report back.
1 Like